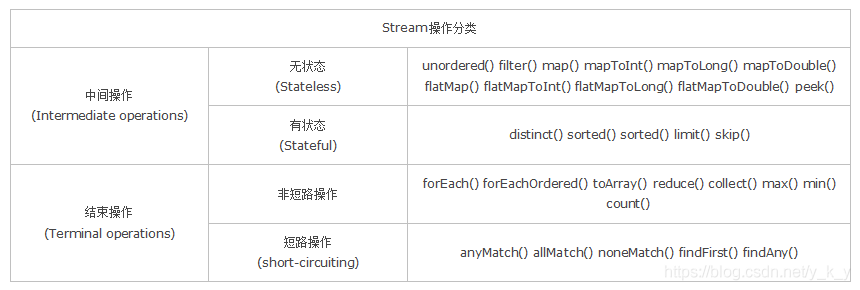
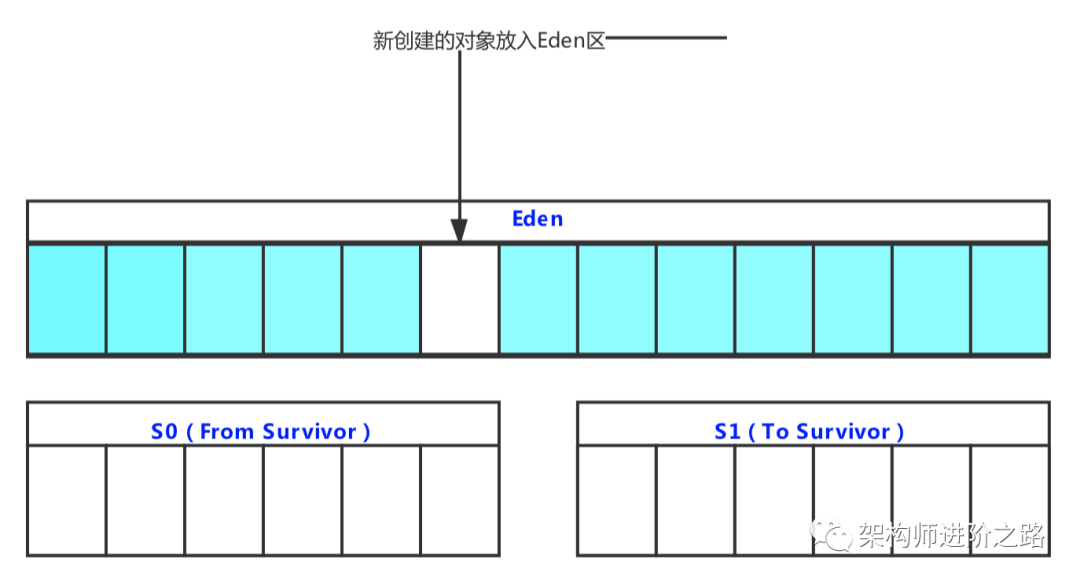
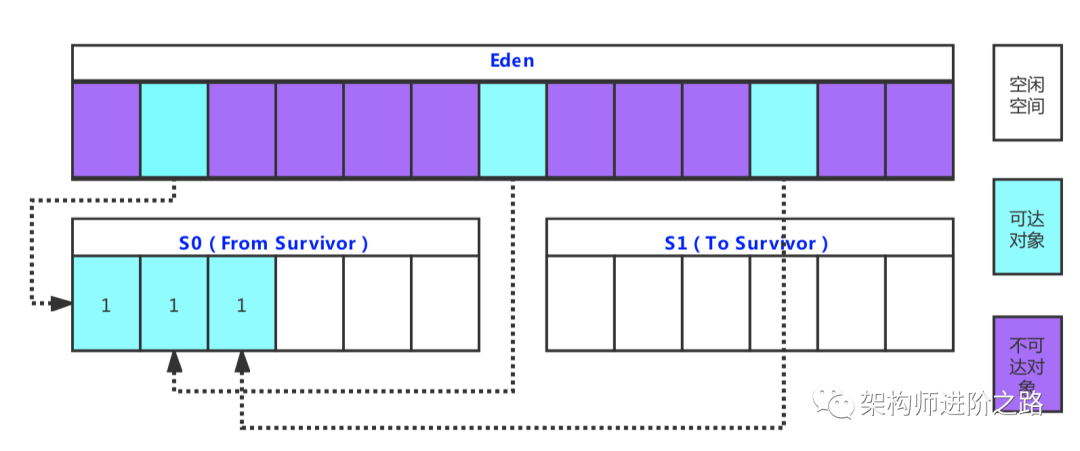
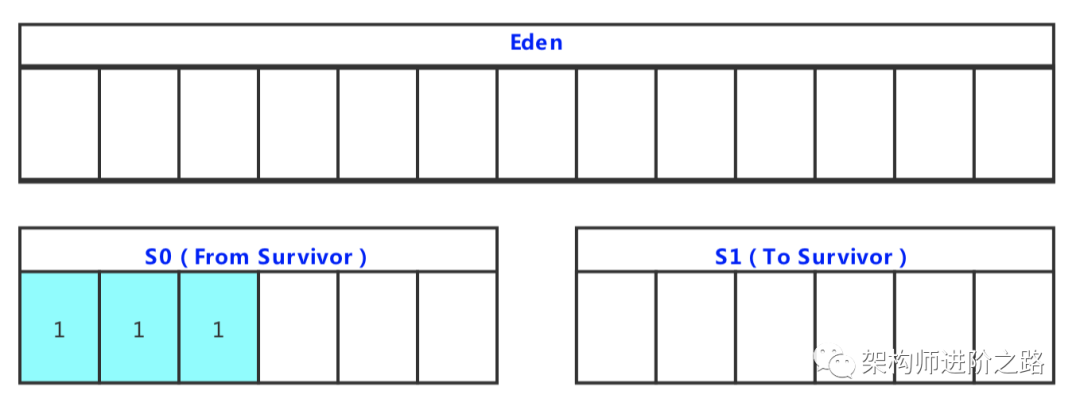
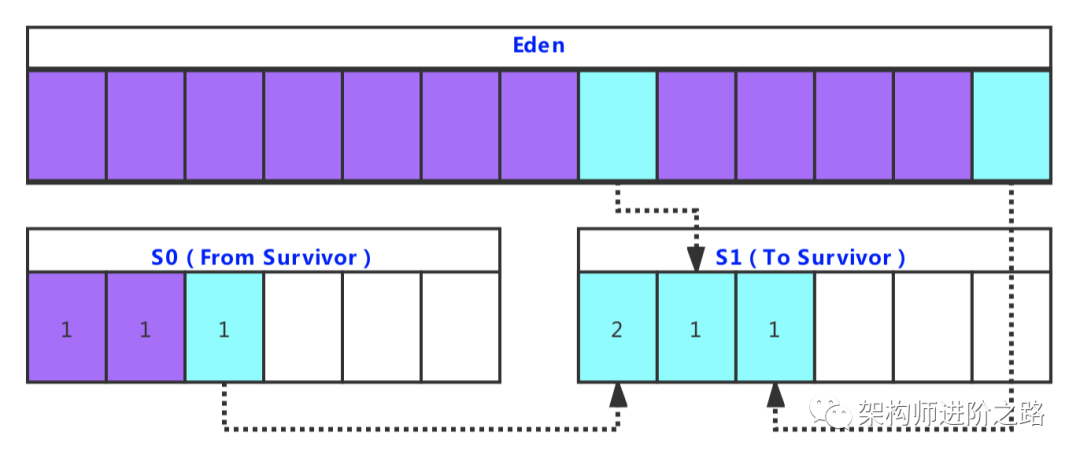
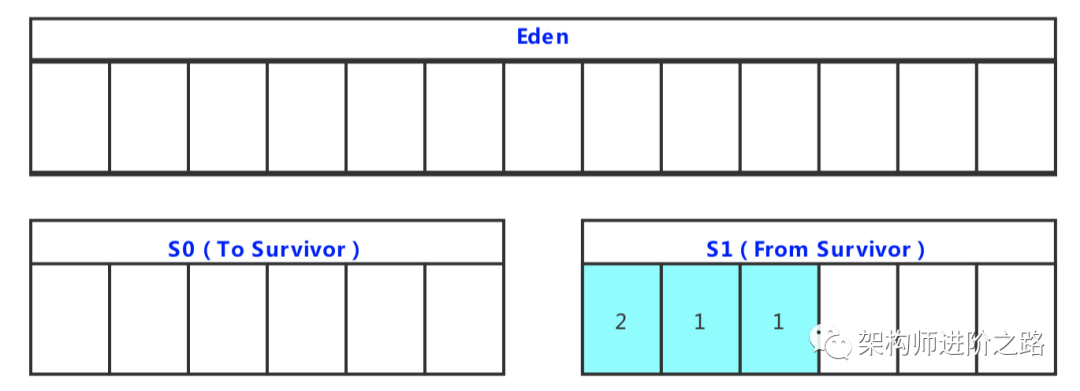
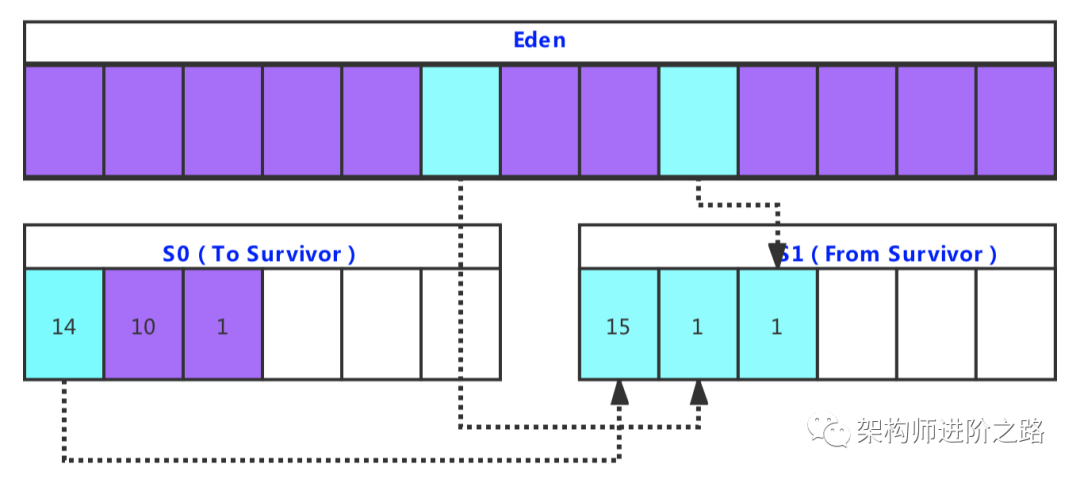
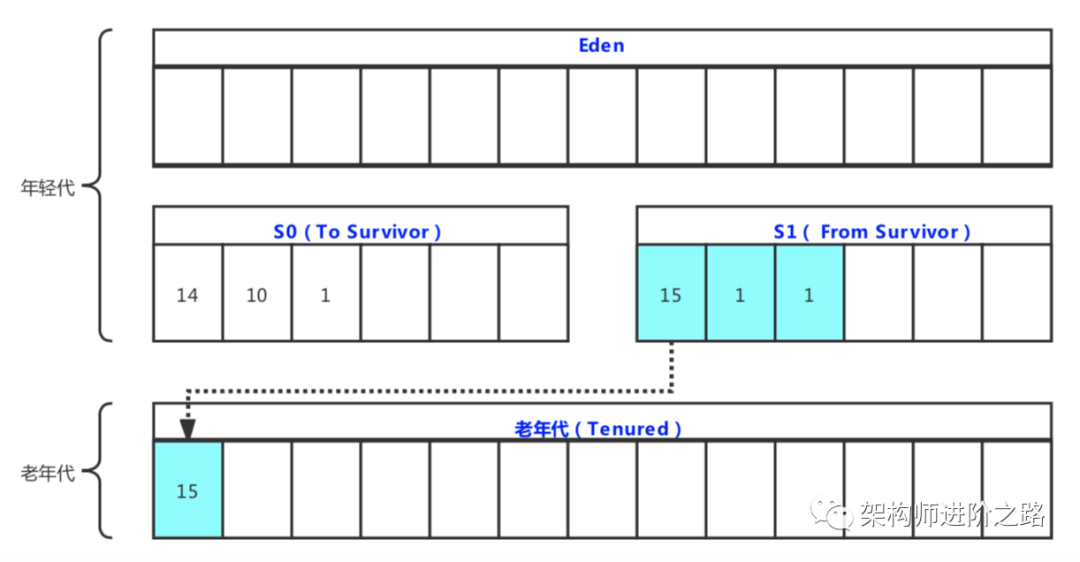
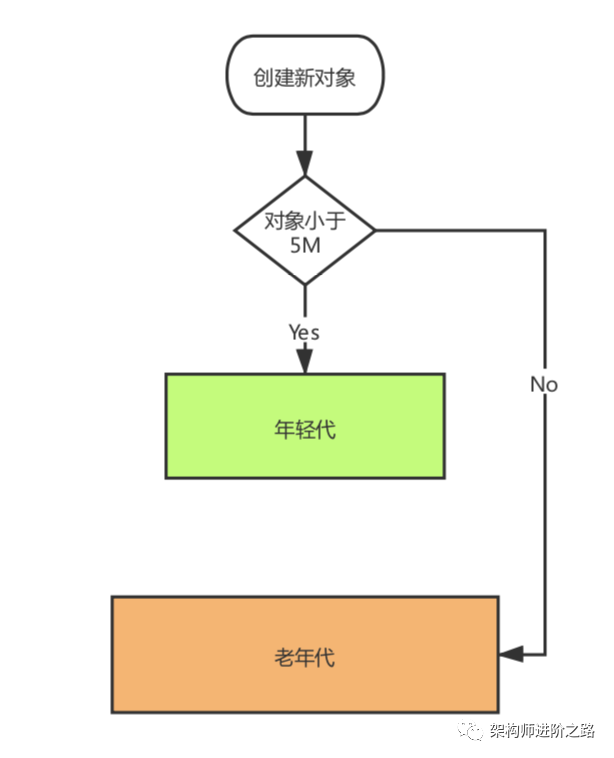
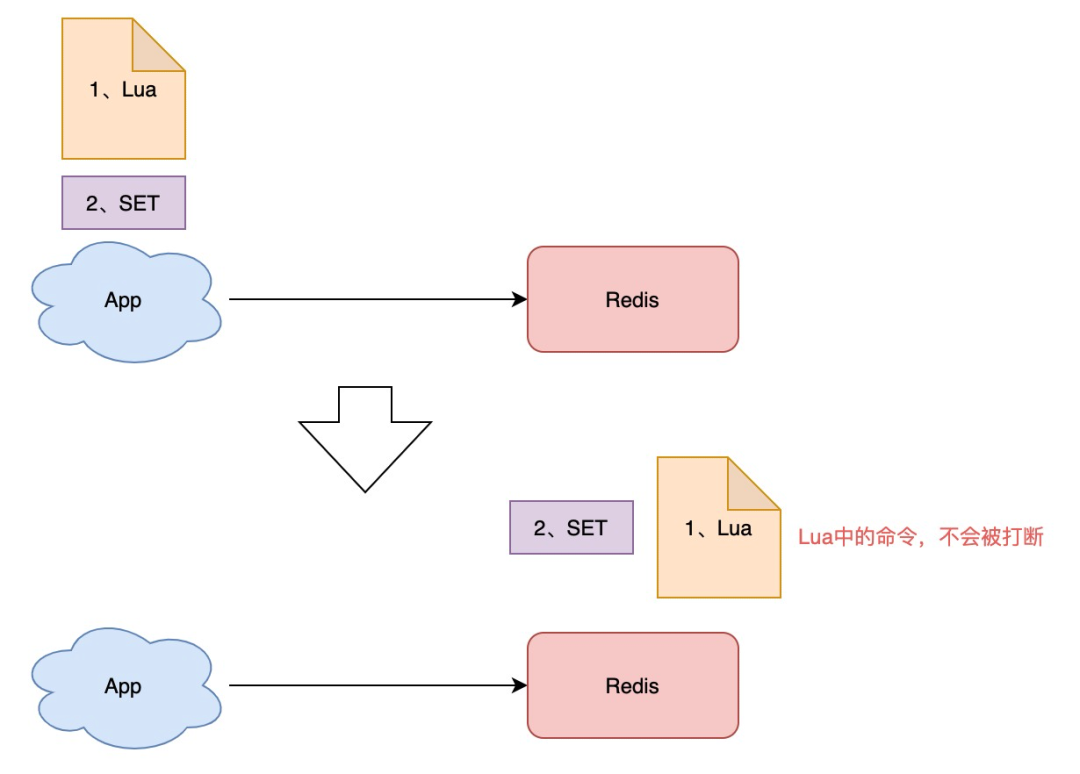
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
对查询进行优化,应尽量避免全表扫描,首先应考虑在 WHERE 及 ORDER BY 涉及的列上建立索引。
应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,创建表时 NULL 是默认值,但大多数时候应该使用 NOT NULL,或者使用一个特殊的值,如 0,-1 作为默认值。
应尽量避免在 WHERE 子句中使用 != 或 <> 操作符。MySQL 只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的 LIKE。
应尽量避免在 WHERE 子句中使用 OR 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,可以使用 UNION 合并查询:select id from t where num=10 union all select id from t where num=20。
IN 和 NOT IN 也要慎用,否则会导致全表扫描。对于连续的数值,能用 BETWEEN 就不要用 IN:select id from t where num between 1 and 3。
下面的查询也将导致全表扫描:select id from t where name like‘%abc%’ 或者 select id from t where name like‘%abc’ 若要提高效率,可以考虑全文检索。而 select id from t where name like‘abc%’ 才用到索引。
如果在 WHERE 子句中使用参数,也会导致全表扫描。
应尽量避免在 WHERE 子句中对字段进行表达式操作,应尽量避免在 WHERE 子句中对字段进行函数操作。
很多时候用 EXISTS 代替 IN 是一个好的选择:select num from a where num in(select num from b)。用下面的语句替换:select num from a where exists(select 1 from b where num=a.num)。
当服务器的内存够多时,配制线程数量 = 最大连接数+5,这样能发挥最大的效率;否则使用配制线程数量< 最大连接数,启用 SQL SERVER 的线程池来解决,如果还是数量 = 最大连接数+5,严重的损害服务器的性能。
查询的关联同写的顺序:
select a.personMemberID, * from chineseresume a,personmember b where personMemberID = b.referenceid and a.personMemberID = 'JCNPRH39681' (A = B, B = '号码')
select a.personMemberID, * from chineseresume a,personmember b where a.personMemberID = b.referenceid and a.personMemberID = 'JCNPRH39681' and b.referenceid = 'JCNPRH39681' (A = B, B = '号码', A = '号码')
select a.personMemberID, * from chineseresume a,personmember b where b.referenceid = 'JCNPRH39681' and a.personMemberID = 'JCNPRH39681' (B = '号码', A = '号码')
久而久之性能总会变化,避免在整个表上使用 count(*),它可能锁住整张表,使查询保持一致以便后续相似的查询可以使用查询缓存,在适当的情形下使用 GROUP BY 而不是 DISTINCT,在 WHERE、GROUP BY 和 ORDER BY 子句中使用有索引的列,保持索引简单,不在多个索引中包含同一个列。
有时候 MySQL 会使用错误的索引,对于这种情况使用 USE INDEX,检查使用 SQL_MODE=STRICT 的问题,对于记录数小于5的索引字段,在 UNION 的时候使用LIMIT不是是用OR。
为了避免在更新前 SELECT,使用 INSERT ON DUPLICATE KEY 或者 INSERT IGNORE;不要用 UPDATE 去实现,不要使用 MAX;使用索引字段和 ORDER BY子句 LIMIT M,N 实际上可以减缓查询在某些情况下,有节制地使用,在 WHERE 子句中使用 UNION 代替子查询,在重新启动的 MySQL,记得来温暖你的数据库,以确保数据在内存和查询速度快,考虑持久连接,而不是多个连接,以减少开销。
基准查询,包括使用服务器上的负载,有时一个简单的查询可以影响其他查询,当负载增加在服务器上,使用 SHOW PROCESSLIST 查看慢的和有问题的查询,在开发环境中产生的镜像数据中测试的所有可疑的查询。
AtomicInteger 的值保存在 value 中,通过 volatile 保证操作的可见性,通过一个静态代码块来保证,类被加载时 valueOffset 已经有值了
Unsafe 是一个不安全的类,提供了一些对底层的操作,我们是不能使用这个类的,valueOffset 是 AtomicInteger 对象 value 成员变量在内存中的偏移量
1 2 3
public final int getAndIncrement() { return unsafe.getAndAddInt(this, valueOffset, 1); }
1 2 3 4 5 6 7 8 9 10 11 12 13
//第一个参数为当前这个对象,如count.getAndIncrement(),则这个参数则为count这个对象 //第二个参数为AtomicInteger对象value成员变量在内存中的偏移量 //第三个参数为要增加的值 public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { //调用底层方法得到value值 var5 = this.getIntVolatile(var1, var2); //通过var1和var2得到底层值,var5为当前值,如果底层值=当前值,则将值设为var5+var4,并返回true,否则返回false } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5; }
这个方法是由其他语言实现的,就不再分析
1
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
并发比较低的时候用 CAS 比较合适,并发比较高用 synchronized 比较合适
CAS的缺点
只能保证对一个变量的原子性操作 当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁来保证原子性。
长时间自旋会给 CPU 带来压力 我们可以看到 getAndAddInt 方法执行时,如果 CAS 失败,会一直进行尝试。如果 CAS 长时间一直不成功,可能会给 CPU 带来很大的开销。
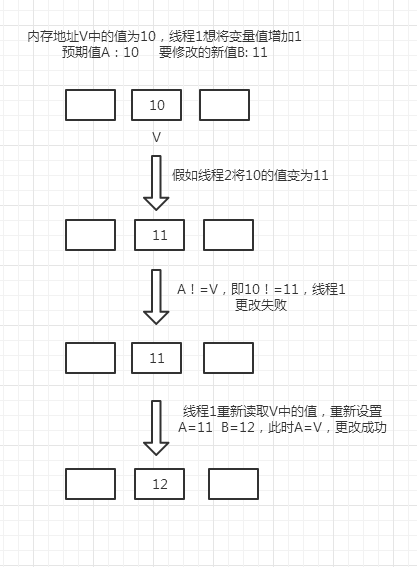
ABA 问题 如果内存地址V初次读取的值是A,并且在准备赋值的时候检查到它的值仍然为 A,那我们就能说它的值没有被其他线程改变过了吗?
如果在这段期间它的值曾经被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。这个漏洞称为 CAS 操作的“ABA”问题。Java 并发包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的版本来保证 CAS 的正确性。因此,在使用 CAS 前要考虑清楚“ABA”问题是否会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
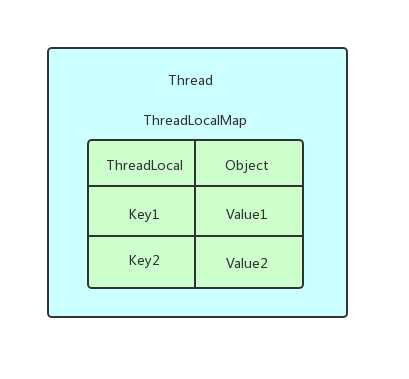
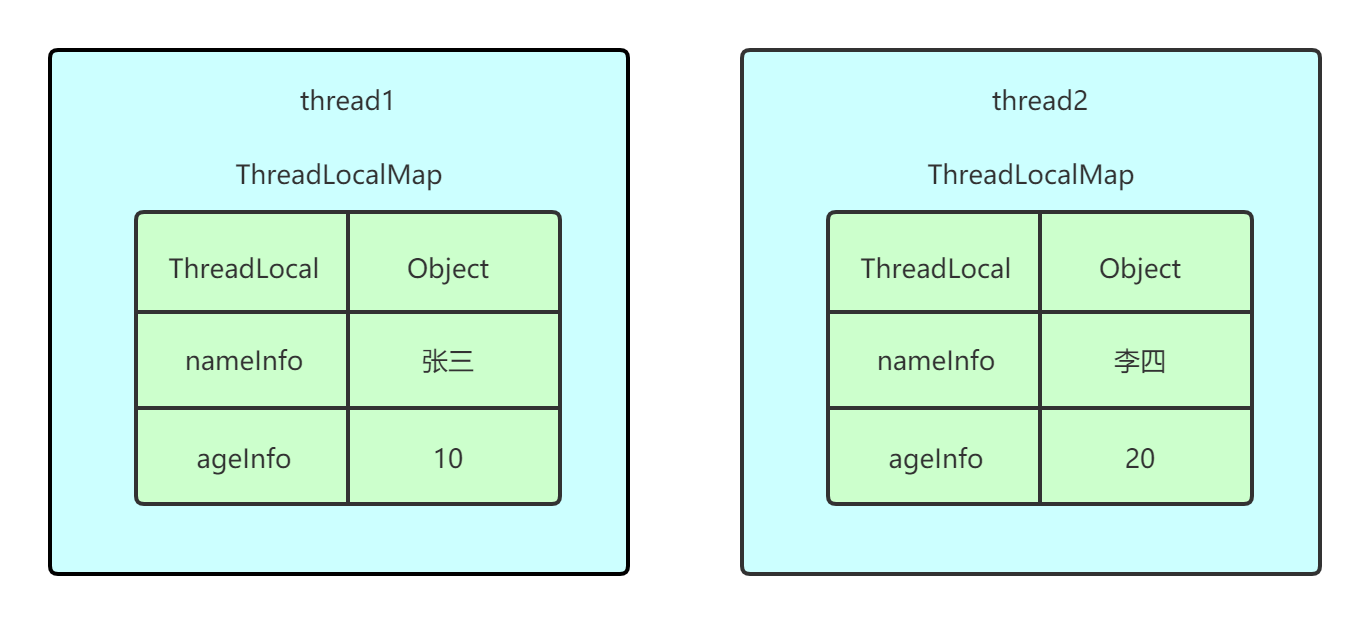
public class Thread implements Runnable { ThreadLocal.ThreadLocalMap threadLocals = null; }
往 ThreadLocalMap 里面放值`
1 2 3 4 5 6 7 8 9
// ThreadLocal类里面的方法,将源码整合了一下 public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = t.threadLocals; if (map != null) map.set(this, value); else t.threadLocals = new ThreadLocalMap(this, firstValue); }
从 ThreadLocalMap 里面取值
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// ThreadLocal类里面的方法,将源码整合了一下 public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = t.threadLocals; if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); }
从 ThreadLocalMap 里面删除值
1 2 3 4 5 6
// ThreadLocal类里面的方法,将源码整合了一下 public void remove() { ThreadLocalMap m = Thread.currentThread().threadLocals; if (m != null) m.remove(this); }