转自:http://www.2cto.com/database/201503/385669.html
Innodb 引擎
Innodb 引擎提供了对数据库 ACID 事务的支持,并且实现了 SQL 标准的四种隔离级别。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于 MySQL 后台的完整数据库系统,MySQL 运行时 Innodb 会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持 FULLTEXT 类型的索引,而且它没有保存表的行数,当 SELECT COUNT(*) FROM TABLE 时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个 SQL 语句时 MySQL 不能确定要扫描的范围,InnoDB表同样会锁全表。
MyIASM 引擎
MyIASM 是 MySQL 默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当 INSERT(插入)或 UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和 Innodb 不同,MyIASM 中存储了表的行数,于是 SELECT COUNT(*) FROM TABLE 时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么 MyIASM 也是很好的选择。
两种引擎的选择
大尺寸的数据集趋向于选择 InnoDB 引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB 可以利用事务日志进行数据恢复,这会比较快。主键查询在 InnoDB 引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题,关于这个问题我会在下文中讲到。大批的 INSERT 语句(在每个 INSERT 语句中写入多行,批量插入)在 MyISAM 下会快一些,但是 UPDATE 语句在 InnoDB 下则会更快一些,尤其是在并发量大的时候。
Index——索引
索引(Index)是帮助MySQL高效获取数据的数据结构。MyIASM 和 Innodb 都使用了树这种数据结构做为索引。下面我接着讲这两种引擎使用的索引结构,讲到这里,首先应该谈一下 B-Tree 和 B+Tree。
B-Tree 和 B+Tree
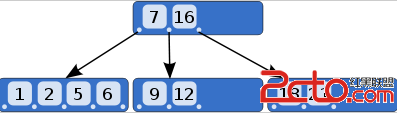
B+Tree 是 B-Tree 的变种,那么我就先讲 B-Tree 吧,相信大家都知道红黑树。其实红黑树类似2,3-查找树,这种树既有 2 叉结点又有 3 叉结点。B-Tree 也与之类似,它的每个结点做多可以有 d 个分支(叉),d 称为 B-Tree 的度,如下图所示,它的每个结点可以有 4 个元素,5 个分支,于是它的度为 5。B-Tree 中的元素是有序的,比如图中元素 7 左边的指针指向的结点中的元素都小于 7,而元素 7 和 16 之间的指针指向的结点中的元素都处于 7 和 16 之间,正是满足这样的关系,才能高效的查找:首先从根节点进行二分查找,找到就返回对应的值,否则就进入相应的区间结点递归的查找,直到找到对应的元素或找到 null 指针,找到 null 指针则表示查找失败。这个查找是十分高效的,其时间复杂度为 $O(logN)$(以 d 为底,当 d 很大时,树的高度就很低),因为每次检索最多只需要检索树高 h 个结点。
接下来就该讲 B+Tree 了,它是 B-Tree 的变种,如下面两张图所示:
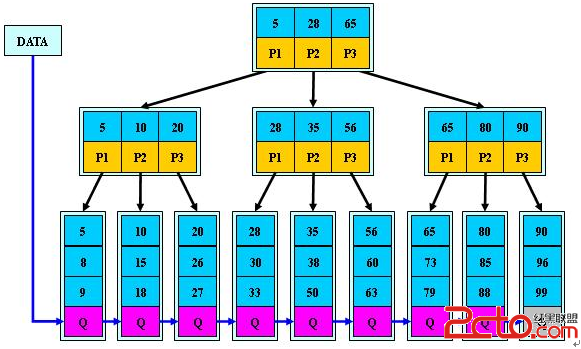
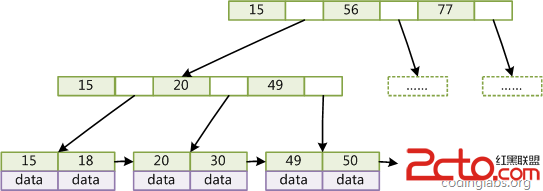
从图中就可以看出,B+Tree 的内部结点不存储数据,只存储指针,而叶子结点则只存储数据,不存储指针。并且在其每个叶子节点上增加了一个指向 MyISAM 引擎的索引结构
MyISAM 引擎的索引结构为 B+Tree,其中 B+Tree 的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。
Innodb 引擎的索引结构
MyISAM 引擎的索引结构同样也是 B+Tree,但是 Innodb 的索引文件本身就是数据文件,即 B+Tree 的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的 key 就是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
因为 InnoDB 的数据文件本身要按主键聚集,所以 InnoDB 要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则 MySQL 系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则 MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,这个字段长度为 6 个字节,类型为长整形。
并且和 MyISAM 不同,InnoDB 的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以 Innodb 不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样 B+Tree 的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
转自:https://www.zhihu.com/question/20596402/answer/211492971
时间:2021/07/13 01:57:48
区别:
- InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
- InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
- InnoDB 是聚集索引,MyISAM 是非聚集索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB 不保存表的具体行数,执行
select count(*) from table时需要全表扫描。而 MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快; - InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
如何选择:
- 是否要支持事务,如果要请选择 InnoDB,如果不需要可以考虑 MyISAM;
- 如果表中绝大多数都只是读查询,可以考虑 MyISAM,如果既有读写也挺频繁,请使用 InnoDB。
- 系统奔溃后,MyISAM 恢复起来更困难,能否接受,不能接受就选 InnoDB;
- MySQL5.5 版本开始 Innodb 已经成为 MySQL 的默认引擎(之前是 MyISAM),说明其优势是有目共睹的。如果你不知道用什么存储引擎,那就用 InnoDB,至少不会差。