转自:http://book.51cto.com/art/201112/307016.htm
_id和ObjectId
MongoDB 中存储的文档必须有一个”_id“键。这个键的值可以是任何类型的,默认是个 ObjectId 对象。在一个集合里面,每个文档都有唯一的”_id“值,来确保集合里面每个文档都能被唯一标识。如果有两个集合的话,两个集合可以都有一个值为 123 的”_id“键,但是每个集合里面只能有一个”_id“是 123 的文档。
ObjectId
ObjectId 是”_id“ 的默认类型。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。这是MongoDB 采用ObjectId,而不是其他比较常规的做法(比如自动增加的主键)的主要原因,因为在多个服务器上同步自动增加主键值既费力还费时。MongoDB 从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。后面会看到ObjectId 类型在分片环境中要容易生成得多。
ObjectId 使用 12 字节的存储空间,每个字节两位十六进制数字,是一个 24 位的字符串。由于看起来很长,不少人会觉得难以处理。但关键是要知道这个长长的 ObjectId 是实际存储数据的两倍长。
如果快速连续创建多个 ObjectId,会发现每次只有最后几位数字有变化。另外,中间的几位数字也会变化(要是在创建的过程中停顿几秒钟)。这是ObjectId 的创建方式导致的。12 字节按照如下方式生成:
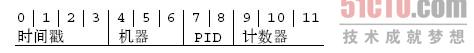
ObjectId 生成规则
4字节:UNIX时间戳
前 4 个字节是从标准纪元开始的时间戳,单位为秒。这会带来一些有用的属性。时间戳,与随后的 5 个字节组合起来,提供了秒级别的唯一性。
由于时间戳在前,这意味着 ObjectId 大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率,但是这个是没有保证的,仅仅是“大致”。
这 4 个字节也隐含了文档创建的时间。绝大多数驱动都会公开一个方法从 ObjectId 获取这个信息。
因为使用的是当前时间,很多用户担心要对服务器进行时间同步。其实没有这个必要,因为时间戳的实际值并不重要,只要其总是不停增加就好了(每秒一次)。
3 字节:表示运行 MongoDB 的机器
接下来的 3 字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以确保不同主机生成不同的 ObjectId,不产生冲突。
2 字节:表示生成此 _id 的进程
为了确保在同一台机器上并发的多个进程产生的 ObjectId 是唯一的,接下来的两字节来自产生 ObjectId 的进程标识符(PID)。
3 字节:由一个随机数开始的计数器生成的值
前 9 字节保证了同一秒钟不同机器不同进程产生的 ObjectId 是唯一的。后 3 字节就是一个自动增加的计数器,确保相同进程同一秒产生的 ObjectId 也是不一样的。同一秒钟最多允许每个进程拥有 2563(16 777 216)个不同的 ObjectId。
自动生成 _id
前面讲到,如果插入文档的时候没有”_id“键,系统会自动帮你创建一个。可以由 MongoDB 服务器来做这件事情,但通常会在客户端由驱动程序完成。理由如下。
虽然 ObjectId 设计成轻量型的,易于生成,但是毕竟生成的时候还是产生开销。在客户端生成体现了 MongoDB 的设计理念:能从服务器端转移到驱动程序来做的事,就尽量转移。这种理念背后的原因是,即便是像 MongoDB 这样的可扩展数据库,扩展应用层也要比扩展数据库层容易得多。将事务交由客户端来处理,就减轻了数据库扩展的负担。
在客户端生成 ObjectId,驱动程序能够提供更加丰富的 API。例如,驱动程序可以有自己的 insert 方法,可以返回生成的 ObjectId,也可以直接将其插入文档。如果驱动程序允许服务器生成 ObjectId,那么将需要单独的查询,以确定插入的文档中的”_id“值。