转自:http://www.cnblogs.com/antineutrino/p/4213268.html
Java字符串的截取操作可以通过substring来完成。有意思的是,这个方法从jdk1.0开始,一直到1.6都没有变化,但到了1.7实现方式却发生了改变。你可能会认为之所以要对一个成熟且稳定的方法做修改,一定是因为新的实现更好、效率更高吧?然而正好相反,修改后的substring的效率变低了,并且占用了更多的内存,无论是从时间上还是空间上都比不上原有的实现。下面我们来做一个比较,看看到底哪一个更好,以及为什么新版Java中要对其进行修改。
原有实现
我们首先来看看原来的substring方法。前面是对参数进行检查,重点是最后一句:
1 | return ((beginIndex == 0) && (endIndex == count)) ? this : |
这里通过调用下面这个构造方法来创建一个新的字符串:
1 | // Package private constructor which shares value array for speed. |
我们知道,Java的字符串实际上是用一个字符数组来实现的,这个构造方法通过复用字符数组value,省去了数组拷贝的开销,仅通过3个赋值语句就创建了一个新的字符串对象。从注释也可以看出这个构造方法的意图就是为了提升性能。
新的实现
我们再来看看1.7中新的substring实现。前面一堆还是参数检查,直接看最后一句:
1 | return ((beginIndex == 0) && (endIndex == value.length)) ? this |
与原来的差不多,但是请注意,这次调用的是另一个构造方法:
1 | public String(char[], int, int) |
这个公有的构造方法和前面那个很相似(那个是包私有的),从方法签名上看区别仅仅是参数顺序不同。不过这只是表面现象,它们的内部实现却是完全不同的,这个公有的构造方法不会复用char[]数组,而是将其拷贝到一个新数组,从而创建一个新字符串。
1 | this.value = Arrays.copyOfRange(value, offset, offset+count); |
对公有的构造方法来说,必须采用这种方式,如果仍然采用复用数组的方法,就会发生安全性问题,别人就可以对字符串中的字符进行任意的修改。后面会对此进行分析。
复用字符数组有没有安全隐患
Java的字符串是不可变的,原因是作为字符串底层实现的字符数组是私有的,从外面无法访问。另一方面,String类的每一个可以创建新字符串的公有方法(构造方法、valueOf等),如果其接受一个字符数组作为参数,就会对该数组执行拷贝操作,这就进一步保证了只有String对象才会持有它的字符数组,因此断绝了从外部修改数组的一切可能。
如果不这么做就会带来问题,字符串的不可变性也就不复存在了。比如下面这个假想的程序:
1 | char[] arr = new char[] {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'}; |
如果构造方法没有对arr进行拷贝,那么其他人就可以在字符串外部修改该数组,由于它们引用的是同一个数组,因此对arr的修改就相当于修改了字符串。(可以通过反射来真正地实现这个假想的程序)
还有一些方法,比如原来的substring方法,它们没有进行数组拷贝,而是直接复用另一个字符串的内部数组。这样做会导致安全问题吗?答案是不会,因为所有这些方法所执行的操作都是私有操作或包私有操作,属于内部实现,因此只要不对外暴露这些操作的接口就仍然是安全的。
例如对substring来说,由于无论是原字符串还是新字符串,其value数组本身都是String对象的私有属性,从外部是无法访问的,因此对两个字符串来说都很安全。
为何要修改substring
原来的substring在安全上没有问题,而且性能很好,又能共享内部数组节约内存。这么看来,好像并没有什么缺点。那为什么要放弃性能更好的实现方式,而采用性能差很多的数组拷贝的方式呢?难道是Oracle的工程师脑抽才会对substring做出这样的修改吗?
当然不是,原来的方法比新的好只是表面现象,因为虽然性能好,但是有一个严重的问题,那就是有可能会导致内存泄漏。看一个例子,假设一个方法从某个地方(文件、数据库或网络)取得了一个很长的字符串,然后对其进行解析并提取其中的一小段内容,这种情况经常发生在网页抓取或进行日志分析的时候。下面是示例代码。
1 | String aLongString = ...; // a very long string |
在这里aLongString只是临时的,真正有用的是aPart,其长度只有20个字符,但是它的内部数组却是从aLongString那里共享的,因此虽然aLongString本身可以被回收,但它的内部数组却不能(如下图)。这就导致了内存泄漏。如果一个程序中这种情况经常发生有可能会导致严重的后果,如内存溢出,或性能下降。
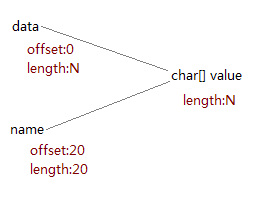
新的实现虽然损失了性能,而且浪费了一些存储空间,但却保证了字符串的内部数组可以和字符串对象一起被回收,从而防止发生内存泄漏,因此新的substring比原来的更健壮。
实际上前面所说的那个包私有的构造方法在1.7中已经被标记为Deprecated,并且实现也修改为直接调用“public String(char[], int, int)”。到了1.8这个构造方法就被删除了。取而代之的是从1.7开始,增加了另一个共享版的构造方法,这个方法也是包私有的:
1 | String(char[] value, boolean share) { |
第二个参数目前没有用到,始终为true,仅仅是为了和另一个公有构造方法“String(char[])”相区别才增加了这么一个参数。这个构造方法用来创建一个和原字符串一模一样的字符串,而不是像以前一样可以创建原字符串的一个子串。在这种情况下,共享数组不会导致内存泄漏问题,只是其用处大打折扣,因为只有很少的情况需要创建一个和原字符串一模一样的字符串,多数情况只需使用原字符串即可。这就像构造方法“String(String)”一样,应该很少有人会使用它来创建字符串吧。
总结
原来的substring性能好,但在一些情况下却可能导致严重的内存泄漏。新的substring没有内存泄漏的隐患,因此健壮性更好,但却是通过牺牲性能换来的。
两种实现孰优孰劣还真不好说,因为在大多数情况下都不会遇到所谓的严重内存泄漏的情况,因此大部分时候新的substring都不如原来的好。但对一个运行库来说,健壮性可能更重要一些,毕竟它需要适用于任何可能遇到的情况。