转自:https://segmentfault.com/a/1190000011440752
Redis提供了 5 种数据结构,但除此之外,Redis 还提供了注入慢查询分析、Redis Shell、Pipeline、事务、与Lua 脚本、Bitmaps、HyperLogLog、PubSub、GEO 等附加功能,这些功能可以在某些场景发挥很重要的作用。
Pipeline
Pipeline 概念
Redis 客户端执行一条命令分为以下四个步骤:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
其中,第一步+第四步称为 Round Trip Time(RTT,往返时间).
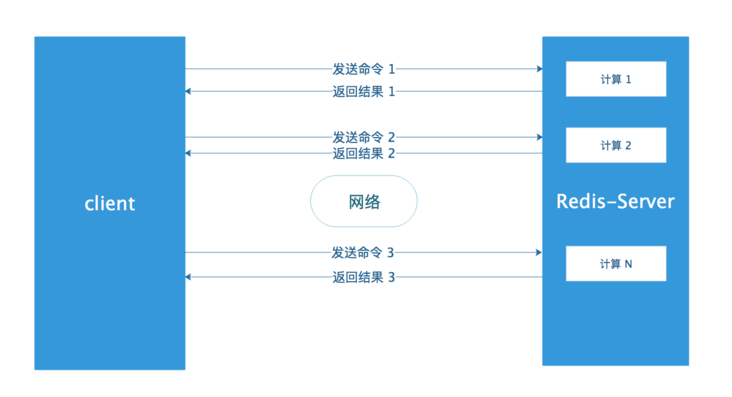
Redis 提供了批量操作命令(例如 mget、mset 等),有效的节约 RTT。但大部分命令是不支持批量操作的,例如要执行 n 次 hgetall 命令,并没有 mhgetall 存在,需要消耗 n 次 RTT。Redis 的客户端和服务端可能不是在不同的机器上。例如客户端在北京,Redis 服务端在上海,两地直线距离为 1300 公里,那么 1 次 $RTT时间=1300×2/(300000×2/3)=13毫秒$(光在真空中传输速度为每秒 30 万公里,这里假设光纤的速度为光速的 2/3),那么客户端在 1 秒内大约只能执行 80 次左右的命令,这个和 Redis 的高并发高吞吐背道而驰。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis 命令进行组装,通过一次 RTT 传输给 Redis,再将这组 Redis 命令按照顺序执行并装填结果返回给客户端。上图未使用 Pipeline 执行了 n 次命令,整个过程需要 n 个 RTT。
Pipeline 并不是什么新的技术和机制,很多技术上都使用过。而且 RTT 在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢。Redis 命令真正执行的时间通常在微秒级别,所以才会有 Redis 性能瓶颈是网络这样的说法。
原生批量命令与 Pipeline 对比
可以使用 Pipeline 模拟出批量操作的效果,但是在使用时需要质疑它与原生批量命令的区别,具体包含几点:
- 原生批量命令是原子性,Pipeline 是非原子性的。
- 原生批量命令是一个命令对应多个 key,Pipeline 支持多个命令。
- 原生批量命令是 Redis 服务端支持实现的,而 Pipeline 需要服务端与客户端的共同实现。
Pipeline 总结
Pipeline 虽然好用,但是每次 Pipeline 组装的命令个数不能没有节制,否则一次组装 Pipeline 数据量过大,一方面会增加客户端的等待时机,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的 Pipeline 拆分成多次较小的 Pipeline 来完成。
Pipeline 只能操作一个 Redis 实例,但即使在分布式 Redis 场景中,也可以作为批量操作的重要优化方法.
事务
为了保证多条命令组合的原子性,Redis 提供了简单的事务以及集成 Lua 脚本来解决这个问题。
熟悉关系型数据库的开发者应该对事务比较了解,简单地说,事务表示一组动作,要么全部成功,要不全部不成功。例如在在电商网站中用户购买商品A那么需要将商品A的库存 -1,并创建一个订单。这两个操作要么远不执行成功,要么全部执行不成功,否则会出现数据不一致的情况。
Redis 提供了简单的功能,将一组需要一起执行的命令放到 multi 和 exec 两个命令之间。multi 命令代表事务的开始,exec 命令代表事务结束,他们之间的命令是原子顺序执行的。
例如上述的用户购买商品问题:
1 | 127.0.0.1:6379> multi |
可以看到数据操作命令返回的结果是 QUEUE,代表命令并没有真正执行,而是暂时保存在 Redis 中。如果此时另一个客户端执行 llen user:1:orders 返回结果为 0。
1 | 127.0.0.1:6379> llen user:1:orders |
只有当 exec 执行后,用户购买商品的行为才算完成,如下两个结果对应 hincrby 和 rpush 命令。
1 | 127.0.0.1:6379> exec |
如果要停止事务的执行,可以使用 discard 命令替代 exec 命令即可.
1 | 127.0.0.1:6379> discard |
如果事务中的命令出现错误,Redis 的处理机制也不尽相同.
命令错误
例如下面操作错将 set 写成了 sett,属于语法错误,会造成整个事务无法执行,key 和 counter 的值未发生变化:
1 | 127.0.0.1:6379> mget key counter |
运行时错误
例如用户购买商品,误把 rpush 写成了 zadd
1 | 127.0.0.1:6379> multi |
可以看到 Redis 并不支持回滚功能,hincrby commodity:a:detail stock -1 命令已经执行成功,开发者需要自己修改这类问题。