转自:https://www.cnblogs.com/rjzheng/p/9721765.html
一
引言
为什么写这篇文章?
大家当年在学 MySQL 的时候,为了能够迅速就业,一般是学习一下 MySQL 的基本语法,差不多就出山找工作了。水平稍微好一点的童鞋呢还会懂一点存储过程的编写,又或者是懂一点索引的创建和使用。但是呢,基本上大家都忽略了对底层知识的学习。为什么呢?因为工作中很少用到嘛。然后呢,市面上流传的大部分这种底层的知识,又比较偏运维,研发懂这么多意义也不是太大,很多知识可能这辈子都不会用到。
因此,我整理了一部分相关的知识,希望大家有所收获。
研发究竟要懂哪些?
主要分为两个部分
- binlog 的相关概念
- 怎么解析 binlog
计划分上下两个部分来叙述。上部分讲述 binlog 的相关概念这部分的知识,我们不需要像运维懂的那么深,我会列举一些常见概念和常见配置,大家匆匆扫一眼,有个概念即可。这样大家以后和运维讨论问题的时候,也不会一脸的懵逼。正所谓
懵逼树上懵逼果,懵逼树下你和我。
懵逼树前排排坐,一人一个懵逼果。
博主一个人默默的把懵逼果收走独享就好,各位读者还是懂点基本概念,以后方便和运维沟通。下半部分讲怎么解析 binlog。
另外,这篇文章是给研发大大看的,可能有些概念我理解的也不对,请运维大大轻喷。
正文
记得我的“一个定义,两个误解,三个用途,四个常识”
一个定义
先从定义开始讲起
binlog 是记录所有数据库表结构变更(例如 CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。
binlog 不会记录 SELECT 和 SHOW 这类操作,因为这类操作对数据本身并没有修改,但你可以通过查询通用日志来查看 MySQL 执行过的所有语句。
多说一句,如果 update 操作没有造成数据变化,也是会记入 binlog。
两个误解
误解一:binlog 只是一类记录操作内容的日志文件
因为 binlog 称之为二进制日志,很多研发会把这个二进制日志和我们平时在代码里写的代码日志联系在一起。因为我们的代码日志,只有一类记录操作容的文件,并不包含索引文件。然而,这个二进制日志包括两类文件:
- 索引文件(文件名后缀为.index)用于记录哪些日志文件正在被使用
- 日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
这么说可能还有一点抽象,假设文件 my.cnf 中有这么三条配置
1 | log_bin:on 打开binlog日志 |
那么你会在文件目录 /var/log/mysql/ 下面发现两个文件 mysql-bin.000001 和 mysql-bin.index。
mysql-bin.index 就是我们所说的索引文件,打开瞅瞅,内容是下面这样,记录哪些文件是日志文件。
1 | ./mysql-bin.000001 |
那么说到日志文件。在 innodb 里其实又可以分为两部分,一部分在缓存中,一部分在磁盘上。这里业内有一个词叫做刷盘,就是指将缓存中的日志刷到磁盘上。跟刷盘有关的参数有两个:sync_binlog 和 binlog_cache_size。这两个参数作用如下
1 | binlog_cache_size: 二进制日志缓存部分的大小,默认值32k |
注意两点:
- binlog_cache_size 设过大,会造成内存浪费。binlog_cache_size 设置过小,会频繁将缓冲日志写入临时文件。具体怎么设,有兴趣自行查询,我觉得研发大大根本没机会去设这个值的,了解即可。
- sync_binlog=0:表示刷新 binlog 时间点由操作系统自身来决定,操作系统自身会每隔一段时间就会刷新缓存数据到磁盘,这个性能最好。sync_binlog=1,代表每次事务提交时就会刷新 binlog 到磁盘。sync_binlog=N,代表每 N 个事务提交会进行一次 binlog 刷新。
另外,这里存在一个一致性问题,sync_binlog=N,数据库在操作系统宕机的时候,可能数据并没有同步到磁盘,于是再次重启数据库,会带来数据丢失问题。
当sync_binlog=1,事务在 commit 的时候,数据写入 binlog,但是还没写入事务日志(redo log和undo log)。此时宕机,重启数据库,数据被回滚。但是 binlog 里已经记录,这里存在不一致问题。这个事务日志和 binlog 一致性的问题,大家可以查询 mysql 的内部 XA 协议,该协议就是解决这个一致性问题的。
误解二:binlog 是 InnoDb 独有的
binlog 是以事件形式记录的,这句话通俗点说,就是 binlog 的内容都是一个个的事件。这块具体的我会在下一篇讲,这篇记住 binlog 的内容就是一个个事件就行。
注意了,这里的用词,是一个个事件,而不是事务。大家应该知道 Innodb 和 mysiam 最显著的区别就是一个支持事务,一个不支持事务。
因此你可以说,binlog 是基于事务来记录二进制日志,比如 sync_binlog=1,每提交一次事务,就写入 binlog。你却不能说 binlog 是事务日志,binlog 不仅记录 innodb 日志,在 myisam 中,也一样存在 binlog。
三个用途
这三个用途,出自《MySQL技术内幕 InnoDB存储引擎》一书,分别为 恢复、复制、审计。这三个用途,研发大大们了解一下即可,比如数据恢复,你碰到同事删库的机会实在太少。假如真的有同事舍己为人,冒着离职的风险给你提供做数据恢复的机会,大把运维工程师待命在那,轮不到你的。所以,这三个功能了解即可。
恢复:这里网上有大把的文章指导你,如何利用 binlog 日志恢复数据库数据。如果你真的觉得自己很有时间,就自己去创建个库,然后删了,再去恢复一下数据,练练手吧。
复制: 如图所示(图片不是自己画的,偷懒了)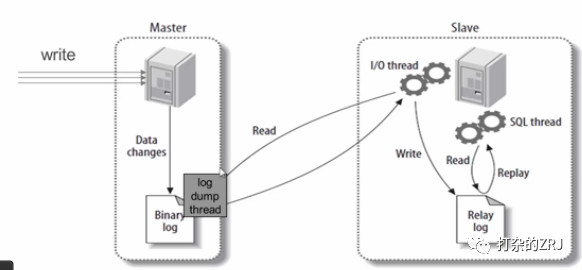
主库有一个 log dump 线程,将 binlog 传给从库
从库有两个线程,一个 I/O 线程,一个 SQL 线程,I/O 线程读取主库传过来的 binlog 内容并写入到 relay log,SQL 线程从 relay log 里面读取内容,写入从库的数据库。
审计:用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入攻击。
四个常识
常识一:binlog 常见格式
这块知识我用一个表格来表示,没必要啰嗦一大堆。
| format | 定义 | 优点 | 缺点 |
|---|---|---|---|
| statement | 记录的是修改SQL语句 | 日志文件小,节约IO,提高性能 | 准确性差,对一些系统函数不能准确复制或不能复制,如now()、uuid()等 |
| row | 记录的是每行实际数据的变更 | 准确性强,能准确复制数据的变更 | 日志文件大,较大的网络IO和磁盘IO |
| mixed | statement和row模式的混合 | 准确性强,文件大小适中 | 有可能发生主从不一致问题 |
业内目前推荐使用的是 row 模式,准确性高,虽然说文件大,但是现在有 SSD 和万兆光纤网络,这些磁盘 IO 和网络 IO 都是可以接受的。
那么,大家一定想问,为什么不推荐使用 mixed 模式,理由如下
假设 master 有两条记录,而 slave 只有一条记录。
master的数据为
1 | +----+------------------------------------------------------+ |
slave的数据为
1 | +----+-------------------------------------------------------+ |
当在 master上 更新一条从库不存在的记录时,也就是 id=2 的记录,你会发现 master 是可以执行成功的。而 slave 拿到这个 SQL 后,也会照常执行,不报任何异常,只是更新操作不影响行数而已。并且你执行命令 show slave status,查看输出,你会发现没有异常。但是,如果你是 row 模式,由于这行根本不存在,是会报1062错误的。
常识二:怎查看 binlog
binlog 本身是一类二进制文件。二进制文件更省空间,写入速度更快,是无法直接打开来查看的。
因此 mysql 提供了命令 mysqlbinlog 进行查看。
一般的 statement 格式的二进制文件,用下面命令就可以
1 | mysqlbinlog mysql-bin.000001 |
如果是 row 格式,加上 -v 或者 -vv 参数就行,如
1 | mysqlbinlog -vv mysql-bin.000001 |
常识三:怎么删 binlog
删 binlog 的方法很多,有三种是常见的
- 使用 reset master,该命令将会删除所有日志,并让日志文件重新从 000001 开始。
- 使用命令 例如
1
PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr }
将会清空 00000X 之前的所有日志文件。1
purge master logs to "binlog_name.00000X"
- 使用 –expire_logs_days=N 选项指定过了多少天日志自动过期清空。
常识四:binlog 常见参数
常见参数,列举如下,有个印象就好。
| 参数名 | 含义 |
|---|---|
| log_bin = {on | off |
| sql_log_bin ={ on | off } |
| expire_logs_days | 指定自动删除二进制日志的时间,即日志过期时间 |
| log_bin_index | 指定mysql-bin.index文件的路径 |
| binlog_format = { mixed | row |
| max_binlog_size | 指定二进制日志文件最大值 |
| binlog_cache_siz | 指定事务日志缓存区大小 |
| max_binlog_cache_size | 指定二进制日志缓存最大大小 |
| sync_binlog = { 0 | n } |
思考题
请问,我说的
- 一个定义
- 两个误解
- 三个用途
- 四个常识
说的是什么呢?
另外,我会在下一篇进行介绍,怎么用代码解析binlog日志。
转自:https://www.cnblogs.com/rjzheng/p/9745551.html
二
引言
这篇是《研发应该懂的binlog知识(上)》的下半部分。在本文,我会阐述一下 binlog 的结构,以及如何使用 java 来解析 binlog。
不过,话说回来,其实严格意义上来说,研发应该还需要懂如何监听 binlog 的变化。我本来也想写这块的知识,但是后来发现,这块讲起来篇幅过长,需要从mysql的通讯协议开始讲起,实在是不适合放在这篇文章讲,所以改天抽时间再写一篇监听 binlog 变化的文章。
说到这里,大家可能有一个疑问:
研发为什么要懂得如何解析 binlog?
说句实在话,如果在实际项目中遇到,我确实推荐使用现成的jar包来解析,比如 mysql-binlog-connector-java 或者 open-replicator 等。但是呢,这类 jar 包解析 binlog 的原理都是差不多的。因为我有一个怪癖,我用一个 jar 包,都会去溜几眼,看一下大致原理,所以想在这个部分把如何解析 binlog 的实质性原理讲出来,希望大家有所收获。大家懂一个大概的原理即可,不需要自己再去造轮子。另外,注意了,本文教你的是解析 binlog 的方法,不可能每一个事件带你解析一遍。能达到举一反三的效果,就是本文的目的。
什么,你还没碰到过解析 binlog 的需求?没事,那先看着,就当学习一下,将来一定会遇到。
正文
先说一下,binlog 的结构。
文件头由一个四字节 Magic Number 构成,其值为 1852400382,在内存中就是”0xfe,0x62,0x69,0x6e”。这个 Magic Number 就是来验证这个 binlog 文件是否有效 。
引一个题外话
java 里头的 class 文件,头四个字节 的Magic Number 是多少?
回答:”0xCAFEBABE。”这个数字可能比较难记,记(咖啡宝贝)就好。
下面写个程序,读一份 binlog 文件,给大家 binlog 看看头四个字节是否为”0xfe,0x62,0x69,0x6e”,代码如下
1 | public class MagicParser { |
输出如下
1 | 魔数\xfe\x62\x69\x6e是否正确:true |
在文件头之后,跟随的是一个一个事件依次排列。在《binlog二进制文件解析》一文中,将其分为三个部分:通用事件头(common-header)、私有事件头(post-header)和事件体(event-body)。本文修改了一下,只用两个 Java 类来修饰 binlog 中的事件,即 EventHeader 和 EventData。可以理解为下述的对应关系:
1 | EventHeader --> 通用事件头(common-header) |
于是,你们可以把 Binlog 的文件结构像下面这么理解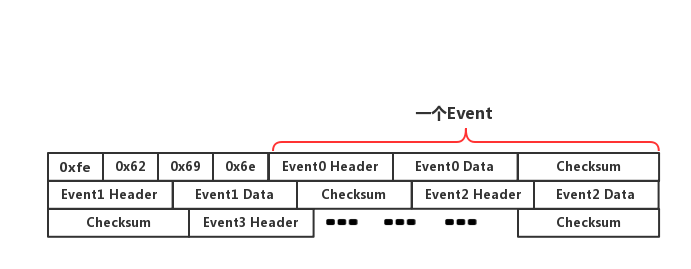
说一下这个 Checksum,在获取 event 内容的时候,会增加 4 个额外字节做校验用。mysql5.6.5 以后的版本中binlog_checksum=crc32,而低版本都是 binlog_checksum=none。如果不想校验,可以使用 set 命令设置 set binlog_checksum=none。说得再通俗一点,Checksum 要么为 4 个字节,要么为 0 个字节。
下面说一下通用事件头的结构,如下所示
| 属性 | 字节数 | 含义 |
|---|---|---|
| timestamp | 4 | 包含了该事件的开始执行时间 |
| eventType | 1 | 事件类型 |
| serverId | 4 | 标识产生该事件的MySQL服务器的server-id |
| eventLength | 4 | 该事件的长度(Header+Data+CheckSum) |
| nextPosition | 4 | 下一个事件在binlog文件中的位置 |
| flags | 2 | 标识产生该事件的MySQL服务器的server-id。 |
从上表可以看出,EventHeader 固定为 19 个字节,为此我们构造下面的类,来解析这个通用事件头
1 | public class EventHeader { |
OK,接下来,我们来一段代码试着解析一下第一个事件的 EventHeader,代码如下所示
1 | public class HeaderParser { |
输出如下
1 | EventHeader{timestamp=1536487335000, eventType=15, serverId=1, eventLength=119, nextPosition=123, flags=1} |
注意看,两个参数
1 | eventLength=119 |
下一个事件从 123 字节开始。这是怎么算的呢,当前事件长度是是 119 字节,算上最开始 4 个字节的魔数占位符,那么下一个事件自然是,119+4=123,从 123 字节开始。再强调一次,这个 119 字节,是包含EventHeader、EventData、Checksum,三个部分的长度为 119。
最重要的一个参数
1 | eventType=15 |
我们去下面的地址
https://dev.mysql.com/doc/internals/en/binlog-event-type.html
查询一下,15 对应的事件类型为 FORMAT_DESCRIPTION_EVENT。我们接下来,需要知道 FORMAT_DESCRIPTION_EVENT 所对应 EventData 的结构。在下面的地址
https://dev.mysql.com/doc/internals/en/format-description-event.html
查询得到 EventData 的结构对应如下表所示
| 属性 | 字节数 | 含义 |
|---|---|---|
| binlogVersion | 2 | binlog版本 |
| serverVersion | 50 | 服务器版本 |
| timestamp | 4 | 该字段指明该binlog文件的创建时间。 |
| headerLength | 1 | 事件头长度,为19 |
| headerArrays | n | 一个数组,标识所有事件的私有事件头的长度 |
ps:这个 n 其实我们可以推算出,为 39。事件长度为 119 字节,减去事件头 19 字节,减去末位的 4 字节(末位四个字节循环校验码),减去 2 个字节的 binlog 版本,减去 50 个字节的服务器版本号,减去 4 个字节的时间戳,减去 1 个字节的事件头长度。得到如下算式
$119−19−4−2−50−4−1=39$
不过,我们还是假装不知道n是多少吧。
根据上表结构 ,我们给出一个JAVA类如下所示
1 | public class FormatDescriptionEventData { |
那如何解析呢,如下所示
1 | public class HeaderParser { |
至于输出,就不给大家看了,没啥意思。大家看 headerArrays 的值即可,如下所示
1 | headerArrays=[56, 13, 0, 8, 0, 18, 0, 4, 4, 4, 4, 18, 0, 0, 95, 0, 4, 26, 8, 0, 0, 0, 8, 8, 8, 2, 0, 0, 0, 10, 10, 10, 42, 42, 0, 18, 52, 0, 1] |
其实他所输出的值,可以在地址 https://dev.mysql.com/doc/internals/en/format-description-event.html
查询到,该页有一个表格如下所示,其中我红圈的地方,就是私有事件头的长度,即
总结
关于其他事件的结构体,大家可以自行去网站查询,解析原理都是一样的。