转自:https://www.cnblogs.com/deeper/p/7565571.html
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件。
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法或不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
- 也不能复制一个迭代器。如果要再次(或者同时)迭代同一个对象,只能去创建另一个迭代器对象。enumerate()的返回值就是一个迭代器,我们以enumerate为例:结果:
1
2
3
4
5
6a = enumerate(['a','b'])
for i in range(2): #迭代两次enumerate对象
for x, y in a:
print(x,y)
print(''.center(50,'-'))1
2
3
40 a
1 b
--------------------------------------------------
--------------------------------------------------
可以看到再次迭代enumerate对象时,没有返回值;
我们可以用linux的文件处理命令vim和cat来理解一下:
- 读取很大的文件时,vim需要很久,cat是毫秒级;因为vim是一次性把文件全部加载到内存中读取;而cat是加载一行显示一行
- vim读写文件时可以前进,后退,可以跳转到任意一行;而cat只能向下翻页,不能倒退,不能直接跳转到文件的某一页(因为读取的时候这个“某一页“可能还没有加载到内存中)
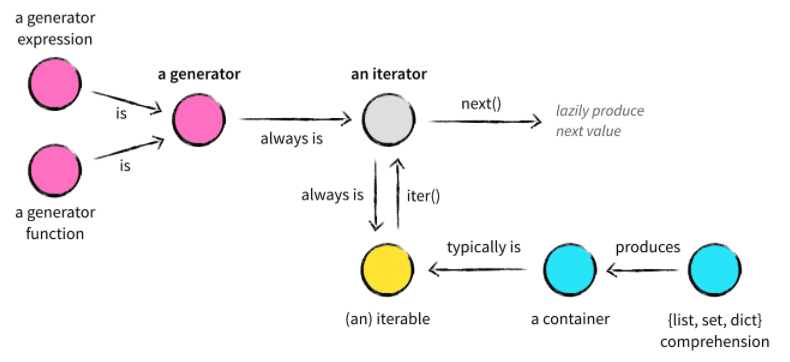
正式进入python迭代器之前,我们先要区分两个容易混淆的概念:可迭代对象和迭代器;
- 可以直接作用于for循环的对象统称为 __可迭代对象(Iterable)__。
- 可以被next()函数调用并不断返回下一个值的对象称为 __迭代器(Iterator)__。
所有的Iterable均可以通过内置函数iter()来转变为Iterator。
可迭代对象
首先,可迭代对象是一个对象,不是一个函数;是一个什么样的对象呢?就是只要它定义了可以返回一个迭代器的__iter__方法,或者定义了可以支持下标索引的__getitem__方法,那么它就是一个可迭代对象。
python中大部分对象都是可迭代的,比如list,tuple等。如果给一个准确的定义的话,看一下list,tuple类的源码,都有__iter__(self)方法。
常见的可迭代对象:
- 集合数据类型,如list、tuple、dict、set、str等;
- generator,包括生成器和带yield的generator function。
注意:生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator
如何判断一个对象是可迭代对象呢?可以通过collections模块的Iterable类型判断:
1 | >>> from collections import Iterable |
迭代器
一个可迭代对象是不能独立进行迭代的,Python中,迭代是通过for … in来完成的。
for循环在迭代一个可迭代对象的过程中都做了什么呢?
- 当for循环迭代一个可迭代对象时,首先会调用可迭代对象的
__iter__()方法,然我们看看源码中关于list类的__iter__()方法的定义:1
2
3def __iter__(self, *args, **kwargs): # real signature unknown
""" Implement iter(self). """
pass__iter__()方法调用了iter(self)函数,我们再来看一下iter()函数的定义:
1 | def iter(source, sentinel=None): # known special case of iter |
iter()函数的参数是一个可迭代对象,最终返回一个迭代器
- for循环会不断调用迭代器对象的
__next__()方法(python2.x中是next()方法),每次循环,都返回迭代器对象的下一个值,直到遇到StopIteration异常。
1 | >>> lst_iter = iter([1,2,3]) |
这里注意:这里的__next__()方法和内置函数next(iterator, default=None)不是一个东西;(内置函数next(iterator, default=None)也可以返回迭代器的下一个值)
- 而for循环可以捕获StopIteration异常并结束循环;
总结一下:
- for….in iterable,会通过调用
iter(iterable)函数(实际上,首先调用的对象的__iter__()方法),返回一个迭代器iterator; - 每次循环,调用一次对象的
__next__(self),直到最后一个值,再次调用会触发StopIteration - for循环捕捉到StopIteration,从而结束循环
上面说了这么多,到底什么是迭代器Iterator呢?
任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值;
既然知道了什么迭代器,那我们自定义一个迭代器玩玩:
1 | class Iterator_test(object): |
如何判断一个对象是一个迭代器对象呢?两个方法:
- 通过内置函数next(iterator, default=None),可以看到next的第一个参数必须是迭代器;所以迭代器也可以认为是可以被next()函数调用的对象
- 通过collection中的Iterator类型判断
1
2
3
4
5
6
7
8
9>>> from collections import Iterator
>>>
>>> isinstance([1,2,3], Iterator)
False
>>> isinstance(iter([1,2,3]), Iterator)
True
>>> isinstance([1,2,3].__iter__(), Iterator)
True
>>>
这里大家会不会有个疑问:
对于迭代器而言,看上去作用的不就是__next__方法嘛,__iter__好像没什么卵用,干嘛还需要__iter__方法呢?
我们知道,python中迭代是通过for循环实现的,而for循环的循环对象必须是一个可迭代对象Iterable,而Iterable必须是一个实现了__iter__方法的对象;知道为什么需要__iter__魔术方法了吧;
那么我就是想自定义一个没有实现__iter__方法的迭代器可以吗?可以,像下面这样:
1 | class Iterable_test(object): |
先定义一个可迭代对象(包含__iter__方法),然后该对象返回一个迭代器;这样看上去是不是很麻烦?是不是同时带有__iter__和__next__魔术方法的迭代器更好呢!
同时,这里要纠正之前的一个迭代器概念:只要__next__()(python2中实现next())方法的对象都是迭代器;
既然这样,只需要迭代器Iterator接口就够了,为什么还要设计可迭代对象Iterable呢?
这个和迭代器不能重复使用有关,下面统一讲解:
总结和一些重要知识点
如何复制迭代器
之前在使用enumerate时,我们说过enumerate对象通过for循环迭代一次后就不能再被迭代:
1 | >>> e = enumerate([1,2,3]) |
这是因为enumerate是一个迭代器;
迭代器是一次性消耗品,当循环以后就空了。不能再次使用;通过深拷贝可以解决;
1 | >>> import copy |
为什么不只保留Iterator的接口而还需要设计Iterable呢?
因为迭代器迭代一次以后就空了,那么如果list,dict也是一个迭代器,迭代一次就不能再继续被迭代了,这显然是反人类的;所以通过__iter__每次返回一个独立的迭代器,就可以保证不同的迭代过程不会互相影响。而生成器表达式之类的结果往往是一次性的,不可以重复遍历,所以直接返回一个Iterator就好。让Iterator也实现Iterable的兼容就可以很灵活地选择返回哪一种。
总结说,Iterator实现的__iter__是为了兼容Iterable的接口,从而让Iterator成为Iterable的一种实现。
另外,迭代器是惰性的,只有在需要返回下一个数据时它才会计算。就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。所以,Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
通过__getitem__来实现for循环
前面关于可迭代对象的定义是这样的:定义了可以返回一个迭代器的__iter__方法,或者定义了可以支持下标索引的__getitem__方法,那么它就是一个可迭代对象。
但是如果对象没有__iter__,但是实现了__getitem__,会改用下标迭代的方式。
1 | class NoIterable(object): |
当for发现没有__iter__但是有__getitem__的时候,会从0开始依次读取相应的下标,直到发生IndexError为止,这是一种旧的迭代方法。iter方法也会处理这种情况,在不存在__iter__的时候,返回一个下标迭代的iterator对象来代替。
一张图总结迭代器
使用迭代器来实现一个斐波那契数列
1 | class Fib(object): |