accuracy、查准率、查全率
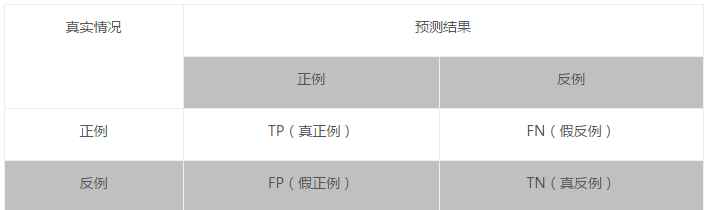
- 准确率(accuracy):= 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN)
- 查准率(precision):P=TP/(TP+FP)(预测结果和真实结果都为正的样本占总的预测结果为正的样本的比例)(挑出的西瓜种有多少比例是好瓜)
- 查全率(recall):R=TP/(TP+FN)(预测结果和真实结果都为正的样本占总的正样本的比例)(所有好瓜中有多少比例被挑了出来)
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。在信息检索中,查准率就是检索出的信息有多少比例是用户感兴趣的;查全率则是用户感兴趣的信息有多少被检索出来。查准率分母中就包含了那些不是用户感兴趣的信息,但仍被预测为是用户感兴趣的而被检索出来;查全率分母中则包含了那些是用户感兴趣的信息,但为被预测为用户感兴趣而被抛弃未检索出来。
对于差准率和查全率的使用是需要按情况来确定那个更重要,例如地震的预测查全率更重要,不希望遗漏哪一次地震,但是对于给用户推荐的广告查准率更重要,要推荐给用户更愿意点击的广告。
P-R曲线
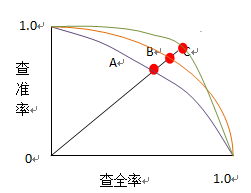
可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为最可能是正例的样本,排在最后的则是学习器认为最不可能是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率,并以查准率为纵轴、查全率为横轴构造查准率-查全率曲线,简称P-R曲线。
P-R曲线是非单调、不平滑的。P-R曲线可用来评估学习器的优劣。若一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则后者的性能优于前者。如果两个学习器的曲线发生交叉,则通过二者面积的大小来比较,面积大的表示查全率和查准率双高比较优秀,但不太容易计算曲线(不平滑)的面积,因此通过平衡点(Break-Even Point,简称BEP)来度量。BEP是坐标上查准率等于查全率时的点,平衡点值越大,学习器越优秀。
用了简单的图来说明,红色的点就是三条P-R曲线的BEP点,学习器A的曲线被C包住,C比较优秀,而C和B交叉,用面积计算难以估算,但C的BEP值大于B,所以C比较优秀。
BEP过于简化,定义F1常量来比较学习器P-R曲线的性能:
- F1度量:
F1=(2*P*R)/(P+R)=2*TP/(样例总数+TP-TN)
F1是基于查准率与查全率的调和平均(harmonic mean)定义的:1/F1=1/2*(1/P+1/R)
更一般的形式:Fβ=(1+β^2)*P*R/((β^2*P)+R)
其中β>0度量了查全率对查准率的相对重要性;β=1时就是标准的F1;β>1时偏好查全率;β<1时偏好查准率。
Fβ则是加权调和平均:1/Fβ=(1/P+β^2/R)/(1+β^2)
ROC、AUC
ROC和AUC类似,也是通过绘制两个变量的概率图像来解释分类器效果的评判准则,ROC曲线的纵轴是“真正例率”TPR,横轴是“假正例率”FPR。其中:
- 真正例率(True Postive Rate)TPR:
TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。Sensitivity - 假正例率(False Postive Rate)FPR:
FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。1-Specificity - 真负例率(True Negative Rate)TNR:
TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。Specificity
AUC的几何意义ROC曲线下的面积。
概率学上的意义:随机选取一个正例和一个负例,分类器给正例的打分大于分类器给负例的打分的概率。