工程及解决方案
面向对象
- SOLID 原则
- The Single Responsibility Principle
- 单一责任原则
- 当需要修改某个类的时候原因有且只有一个(THERE SHOULD NEVER BE MORE THAN ONE REASON FOR A CLASS TO CHANGE)。换句话说就是让一个类只做一种类型责任,当这个类需要承当其他类型的责任的时候,就需要分解这个类。
- The Open Closed Principle
- 开放封闭原则
- 一个软件实体,如类、模块和函数应该对扩展开放,对修改关闭
- The Liskov Substitution Principle
- 里氏替换原则
- 所有引用基类的地方必须能透明地使用其子类的对象
- The Dependency Inversion Principle
- 依赖倒置原则
- 高层模块不应该依赖于低层模块,二者都应该依赖于抽象
- 抽象不应该依赖于细节,细节应该依赖于抽象
- The Interface Segregation Principle
- 接口分离原则
- 不能强迫用户去依赖那些他们不使用的接口。换句话说,使用多个专门的接口比使用单一的总接口总要好。
- The Single Responsibility Principle
解决方案
- 防止超卖
- 解决方案
- 使用 MySQL 的事务加排他锁来解决
- 乐观锁
select version from goods WHERE id = 1001update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(上面查到的version);
- 使用文件锁实现
- 当用户抢到一件促销商品后先触发文件锁,防止其他用户进入,该用户抢到促销品后再解开文件锁,放其他用户进行操作。这样可以解决超卖的问题,但是会导致文件得 I/O 开销很大。
- 使用了 Redis 的队列来实现
- 将要促销的商品数量以队列的方式存入 Redis 中,每当用户抢到一件促销商品则从队列中删除一个数据,确保商品不会超卖。这个操作起来很方便,而且效率极高,最终我们采取这种方式来实现。
- 解决方案
- 流量削峰
- 由来
- 春节火车票抢购,大量的用户需要同一时间去抢购;以及大家熟知的阿里双 11 秒杀, 短时间上亿的用户涌入,瞬间流量巨大(高并发),比如:200 万人准备在凌晨 12:00 准备抢购一件商品,但是商品的数量缺是有限的 100-500 件左右。
- 服务器的处理资源是有限的,所以出现峰值的时候,很容易导致服务器宕机,用户无法访问的情况出现。
- 解决方案
- 消息队列解决削峰
- 流量削峰漏斗:层层削峰
- 对请求进行分层过滤,从而过滤掉一些无效的请求。

- 核心思想
- 通过在不同的层次尽可能地过滤掉无效请求。
- 通过 CDN 过滤掉大量的图片,静态资源的请求。
- 再通过类似 Redis 这样的分布式缓存,过滤请求等就是典型的在上游拦截读请求。
- 基本原则
- 对写数据进行基于时间的合理分片,过滤掉过期的失效请求。
- 对写请求做限流保护,将超出系统承载能力的请求过滤掉。
- 涉及到的读数据不做强一致性校验,减少因为一致性校验产生瓶颈的问题。
- 对写数据进行强一致性校验,只保留最后有效的数据。
- 消息队列解决削峰
- 由来
- 密码存储
- 在注册时,根据用户设置的登录密码,生成其消息认证码,然后存储用户名和消息认证码,不存储原始密码。每次用户登录时,根据登录密码,生成消息认证码,与数据库中存储的消息认证码进行比对,以确认是否为有效用户,这样即使网站被脱库,用户的原始密码也不会泄露,不会为用户使用的其他网站带来账号风险。
- 当然,使用的消息认证码算法其哈希碰撞的概率应该极低才行,目前一般在 HMAC 算法中使用 SHA256。对于这种方式需要注意一点:防止用户使用弱密码,否则也可能会被暴力破解。现在的网站一般要求用户密码 6 个字符以上,并且同时有数字和大小写字母,甚至要求有特殊字符。
- 另外,也可以使用加入随机 salt 的哈希算法来存储校验用户密码。
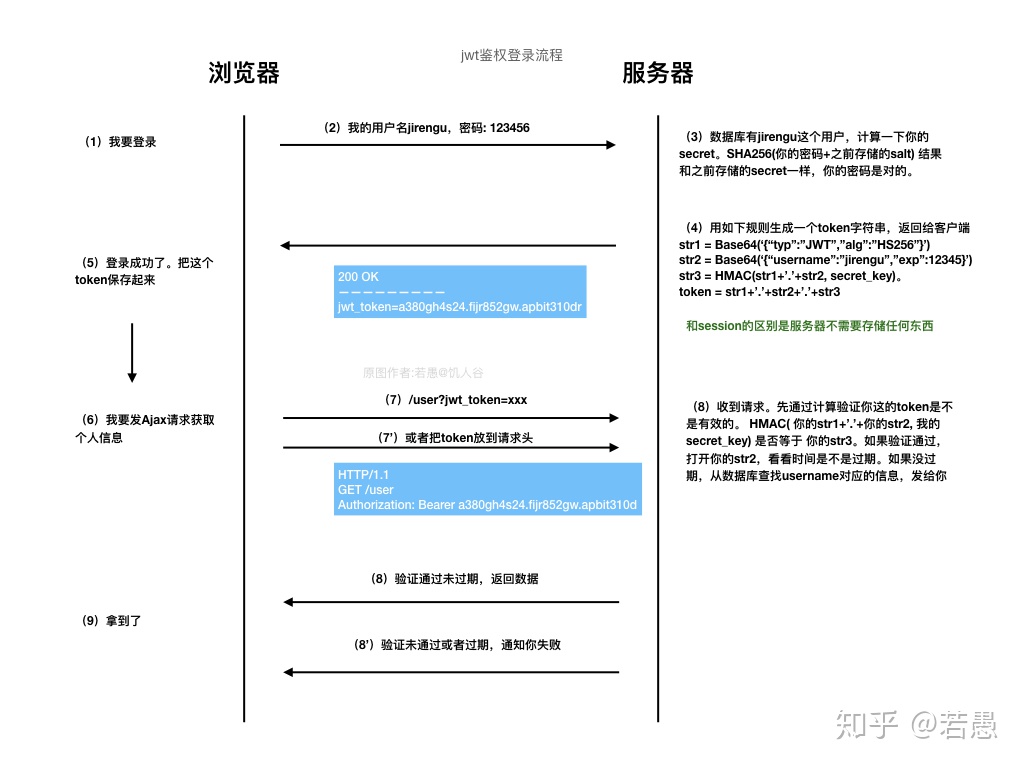
- 登陆
- JWT
- Token
- 生存 UUID 作为 Token
- JWT
性能评估
- TPS、QPS
- TPS
- (Transactions Per Second),即每秒执行的事务总数。
- 首先一个事务包括三个动作,即客户端请求服务端,服务端内部进行处理,服务端对客户端进行响应。
- 将这三个动作看成一个整体,并将之称为一个事务,若在一秒内,服务端可以完成 N 个事务,则这个服务端的 TPS 为 N。
- 一般来说,评价系统的性能主要看系统的 TPS,系统的整体性能取决于性能最低模块的 TPS 值。
- QPS
- (Queries Per Second),及每秒执行的查询总数(每秒有多少的请求响应)
- 客户端请求一个地址时,比如百度首页,其实会产生很多的请求,比如 js、css、png等,像这样的每个单个请求都可以算作查询次数。
- 若在一秒内,客户端请求服务端的首页,服务端返回了 N 个内部链接(js、css、png、html 等),那么服务端的 QPS 就为 N。
- QPS 反映系统的吞吐能力,更偏向于读取文件,查询数据。
- 举例
- 若在一秒内,用户请求了百度首页并看到了首页全貌,这样就形成了一个 TPS,但却形成了多个 QPS。
- 若在一秒内,我们请求一个单调的网页,此网页只有一个 html,不包含任何其他内部链接,此时 TPS=QPS。
- TPS
- 独立访客、综合浏览量
- 网站流量是指网站的访问量,用来描述访问网站的用户数量以及用户所浏览的网页数量等指标,常用的统计指标包括网站的独立用户数量、总用户数量(含重复访问者)、网页浏览数量、每个用户的页面浏览数量、用户在网站的平均停留时间等。
- 网站访问量的常用衡量标准:独立访客(UV)和 综合浏览量(PV),一般以日为单位来衡量和计算。
- 独立访客(UV):指一定时间范围内相同访客多次访问网站,只计算为 1 个独立访客。
- 综合浏览量(PV):指一定时间范围内页面浏览量或点击量,用户每次刷新即被计算一次。
- PV 计算带宽
- 计算带宽大小需要关注两个指标:峰值流量和页面的平均大小。
- 举个例子:
假设网站的平均日 PV:10w 的访问量,页面平均大小 0.4 M 。
网站带宽 =
10w / (24 * 60 * 60)* 0.4M * 8 =3.7 Mbps具体的计算公式是:
网站带宽 = PV / 统计时间(换算到s)* 平均页面大小(单位KB)* 8
- 在实际的网站运行过程中,我们的网站必须要在峰值流量时保持正常的访问,假设,峰值流量是平均流量的 5 倍,按照这个计算,实际需要的带宽大约在
3.7 Mbps * 5=18.5 Mbps。 - PS:
- 字节的单位是 Byte,而带宽的单位是 bit,1Byte=8bit,所以转换为带宽的时候,要乘以 8。
- 在实际运行中,由于缓存、CDN、白天夜里访问量不同等原因,这个是绝对情况下的算法。
- PV 与并发
- 具体的计算公式是:
并发连接数 = PV / 统计时间 * 页面衍生连接次数 * http响应时间 * 因数 / web服务器数量; - 解释:
- 页面衍生连接次数:一个页面请求,会有好几次 http 连接,如外部的 css、js、图片等,这个根据实际情况而定。
- http 响应时间:平均一个 http 请求的响应时间,可以使用 1 秒或更少。
- 因数:峰值流量和平均流量的倍数,一般使用 5,最好根据实际情况计算后得出。
- 例子:
- 10w PV 的并发连接数:
(100000PV / 86400秒 * 50个派生连接数 * 1秒内响应 * 5倍峰值) / 1台Web服务器 = 289 并发连接数
- 10w PV 的并发连接数:
- 所以,如果我们能够测试出单机的并发连接数和日 pv 数,那么我们同样也能估算出需要 web 的服务器数量。
- 还有一套通过单机 QPS 计算 pv 和 需要的 web 服务器数量的方法,目前一些公司采用这种计算方法,但是其实计算的原理都是差不多的。
- 具体的计算公式是:
- QPS、PV 和需要部署机器数量计算公式
- QPS = req/sec = 请求数/秒
- QPS统计方式:一般使用 http_load 进行统计
QPS = 总请求数 / (进程总数 * 请求时间)- QPS:单个进程每秒请求服务器的成功次数
- QPS 计算 PV 和机器的方式
- 单台服务器每天 PV 计算
- 公式 1:
每天总 PV = QPS * 3600 * 6 - 公式 2:
每天总 PV = QPS * 3600 * 8
- 公式 1:
- 服务器计算
服务器数量 = (每天总PV / 单台服务器每天总PV)
- 峰值 QPS 和机器计算公式
- 原理:每天 80% 的访问集中在 20% 的时间里,这 20% 时间叫做峰值时间
- 公式:
(总 PV 数 * 80%) / (每天秒数 * 20%) = 峰值时间每秒请求数(QPS) - 机器:
峰值时间每秒 QPS / 单台机器的 QPS = 需要的机器
- 例子:每天 300w PV 的在单台机器上,这台机器需要多少 QPS?
(3000000 * 0.8) / (86400 *0.2) = 139 (QPS)
- 例子:如果一台机器的 QPS 是 58,需要几台机器来支持?
139 / 58 = 3
- 单台服务器每天 PV 计算
测试
- 常见场景
- 新系统上线
- 升级重构
- 容量规划
- 性能探测
- 系统稳定性
- 常见的测试
- 基准测试
- 通过单用户循环调用接口,持续 10 分钟, 统计响应时间的平均值,和 TP90、TP99,了解接口在系统无压力情况下的性能数据。
- 相关概念
- TP90,top percent 90,即 90% 的数据都满足某一条件;
- TP95,top percent 95,即 95% 的数据都满足某一条件;
- TP99,top percent 99,即 99% 的数据都满足某一条件;
- 相关概念
- 通过单用户循环调用接口,持续 10 分钟, 统计响应时间的平均值,和 TP90、TP99,了解接口在系统无压力情况下的性能数据。
- 负载测试
- 从 0 开始逐步增加系统压力,知道系统吞吐量或者系统资源消耗达到预估的标准,了解系统在安全运行下的极限。
- 压力测试
- 从负载测试探测到的系统吞吐量开始继续加压,直到系统错误率超标甚至不可以用,了解系统可服务的极限。
- 缓存穿透
- 了解系统缓存不可以下的吞吐量。
- 扩展性测试
- 扩展应用服务器数量,了解系统扩展能力。
- 基准测试
- 测试工具
- LoadRunner
- Apache JMeter
- Siege
- 常用参数
-c- 并发数量
-r- 重复的次数
-t- 测试时间
-i- 随机访问
-f指定的 url.txt 中的 url 列表项,以此模拟真实的访问情况(随机性)
- 随机访问
-b- –benchmark:基准测试,请求之间没有延迟。
- 常用参数
负载均衡
- 一般负载分为软件负载和硬件负载,比如软件中使用 nginx 等工具实现负载均衡,而 F5 负载均衡器就是硬件网络性能优化设备。
- 硬件
- F5 负载均衡器
- 通俗的讲是将客户端请求量通过 F5 负载到各个服务器,增加吞吐量,从而降低服务器的压力,他不同于交换机、路由器这些网络基础设备,而是建立在现有网络结构上用来增加网络带宽和吞吐量的的硬件设备
- 工作原理
- 客户发出服务请求到 VIP
- BIGIP 接收到请求,将数据包中目的 IP 地址改为选中的后台服务器 IP 地址,然后将数据包发出到后台选定的服务器
- 后台服务器收到后,将应答包按照其路由发回到 BIGIP
- BIGIP 收到应答包后将其中的源地址改回成 VIP 的地址,发回客户端,由此就完成了一个标准的服务器负载平衡的流程
- F5 负载均衡器