基础
三范式
- 第一范式:确保每列的原子性
- 第二范式:非主键列不存在对主键的部分依赖(要求每个表只描述一件事情)
- 第三范式:满足第二范式,并且表中的列不存在对非主键列的传递依赖
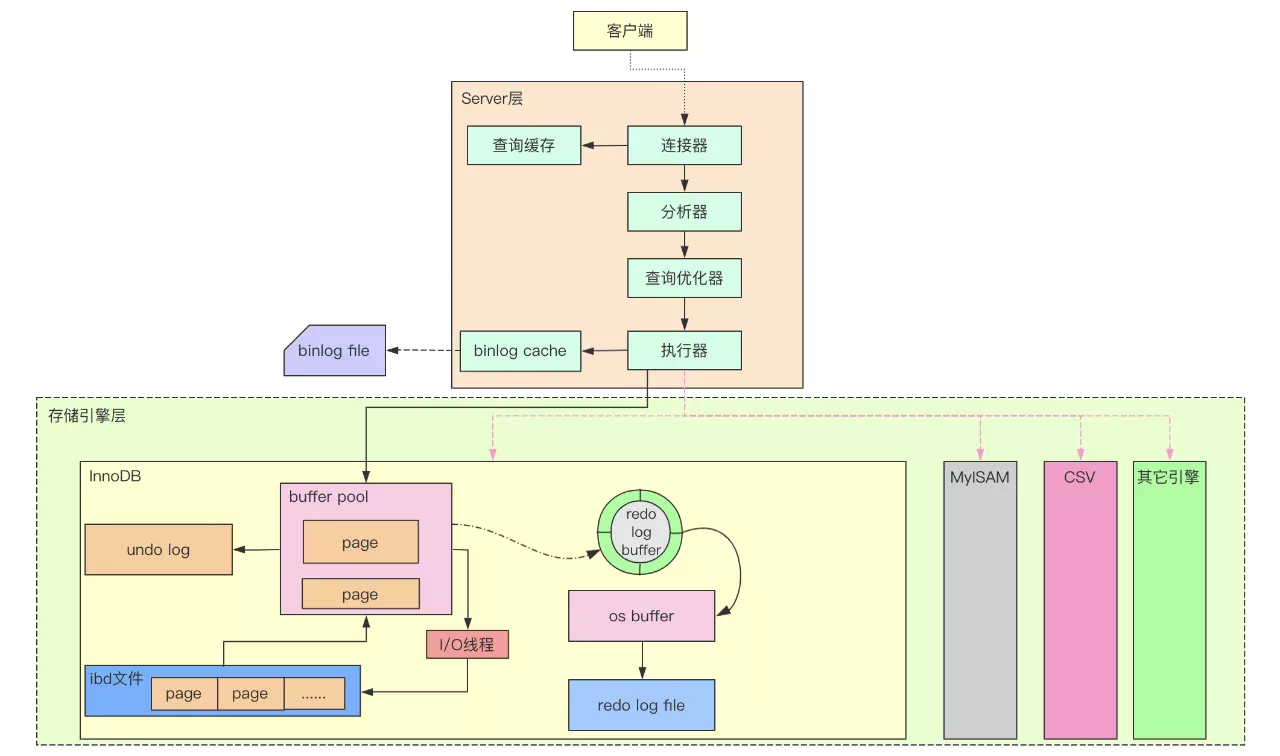
SQL
- 分类
- DQL
- Data Query Language,数据查询语言
- 最常用的为保留字 SELECT,并且常与 FROM 子句、WHERE 子句组成查询 SQL 查询语句。
- DML
- Data Manipulation Language,数据操纵语言
- 主要用来对数据库的数据进行一些操作,常用的就是 INSERT、UPDATE、DELETE。
- DPL
- 事务处理语言
- 事务处理语句能确保被 DML 语句影响的表的所有行及时得以更新。DPL 语句包括 BEGIN TRANSACTION、COMMIT 和 ROLLBACK。
- DCL
- 数据控制语言
- 通过 GRANT 和 REVOKE,确定单个用户或用户组对数据库对象的访问权限。
- DDL
- 数据定义语言
- 常用的有 CREATE 和 DROP,用于在数据库中创建新表或删除表,以及为表加入索引等。
- CCL
- 指针控制语言
- 它的语句,像 DECLARE CURSOR、FETCH INTO 和 UPDATE WHERE CURRENT 用于对一个或多个表单独行的操作。
- DQL
引擎
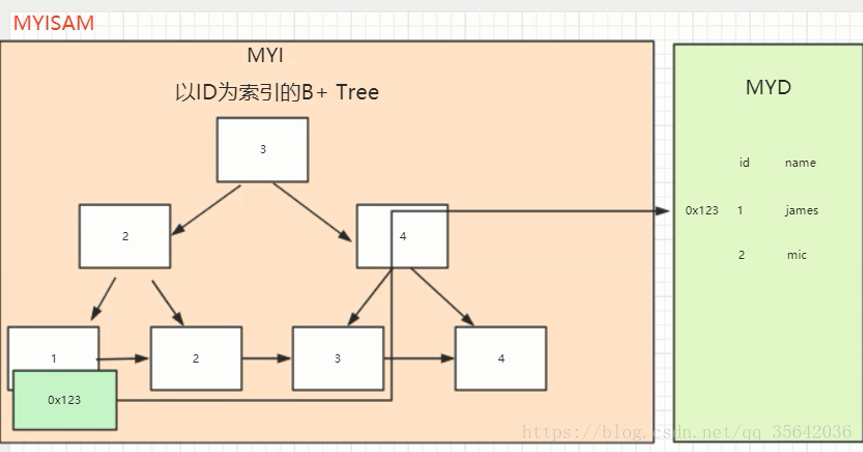
- MyISAM
- 不支持事务
- 不支持外键
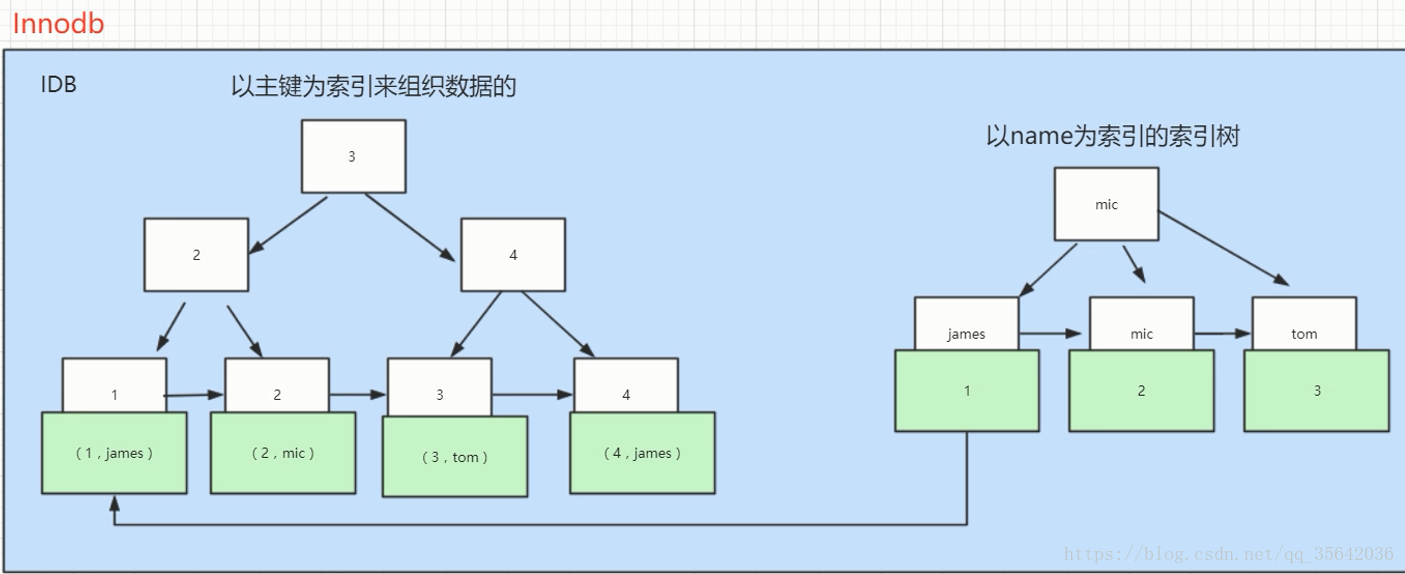
- 是非聚集索引,也是使用 B+ Tree 作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- 用一个变量保存了整个表的行数
- 支持全文索引
- 支持表级锁
- 可以没有唯一索引
- Myisam 存储文件有 frm、MYD、MYI
- frm 是表定义文件
- myd 是数据文件
- myi 是索引文件
- InnoDB
- 支持事务
- 支持外键
- 是聚集索引,使用 B+ Tree 作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按 B+ Tree 组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
- 相关问题
- 为什么 MySQL 用 B+ 树做索引而不用 B-树或红黑树?
- 在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘 IO 读写过于频繁,进而导致效率低下的情况。
- 磁盘读写 IO 跟树的深度有关系,磁盘一次 IO 读取的数据多能做的事也将更多。(我们知道要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘 IO 频繁读写。)根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B 树可以有多个子女,从几十到上千,但是降低树的高度。
- 数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次 I/O 就可以完全载入。为了达到这个目的,在实际实现 B-Tree 还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个 node 只需一次 I/O。
- B-Tree 有许多变种,其中最常见的是 B+Tree,例如 MySQL 就普遍使用 B+Tree 实现其索引结构。
- 在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘 IO 读写过于频繁,进而导致效率低下的情况。
- 为什么 MySQL 用 B+ 树做索引而不用 B-树或红黑树?
- 不保存表的具体行数,执行
select count(*) from table时需要全表扫描- 想逛问题
- 为什么 InnoDB 没有保存行数呢?
- 因为 InnoDB 的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的,因此 count 统计会计算对于当前事务而言可以统计到的行数,而不是将总行数储存起来方便快速查询。
- 为什么 InnoDB 没有保存行数呢?
- 想逛问题
- 不支持全文索引(5.7以后的InnoDB支持全文索引了)
- 支持表、行(默认)级锁
- 须有唯一索引(如主键)(用户没有指定的话会自己找/生产一个隐藏列 Row_id 来充当默认主键)
- Innodb 存储文件有 frm、ibd
- frm 是表定义文件
- ibd 是数据文件
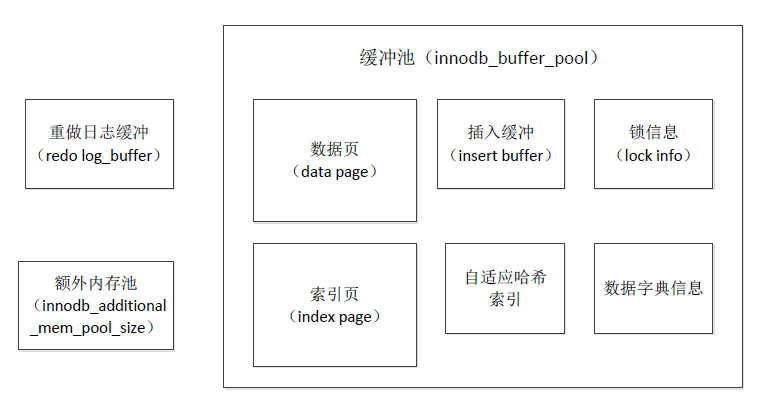
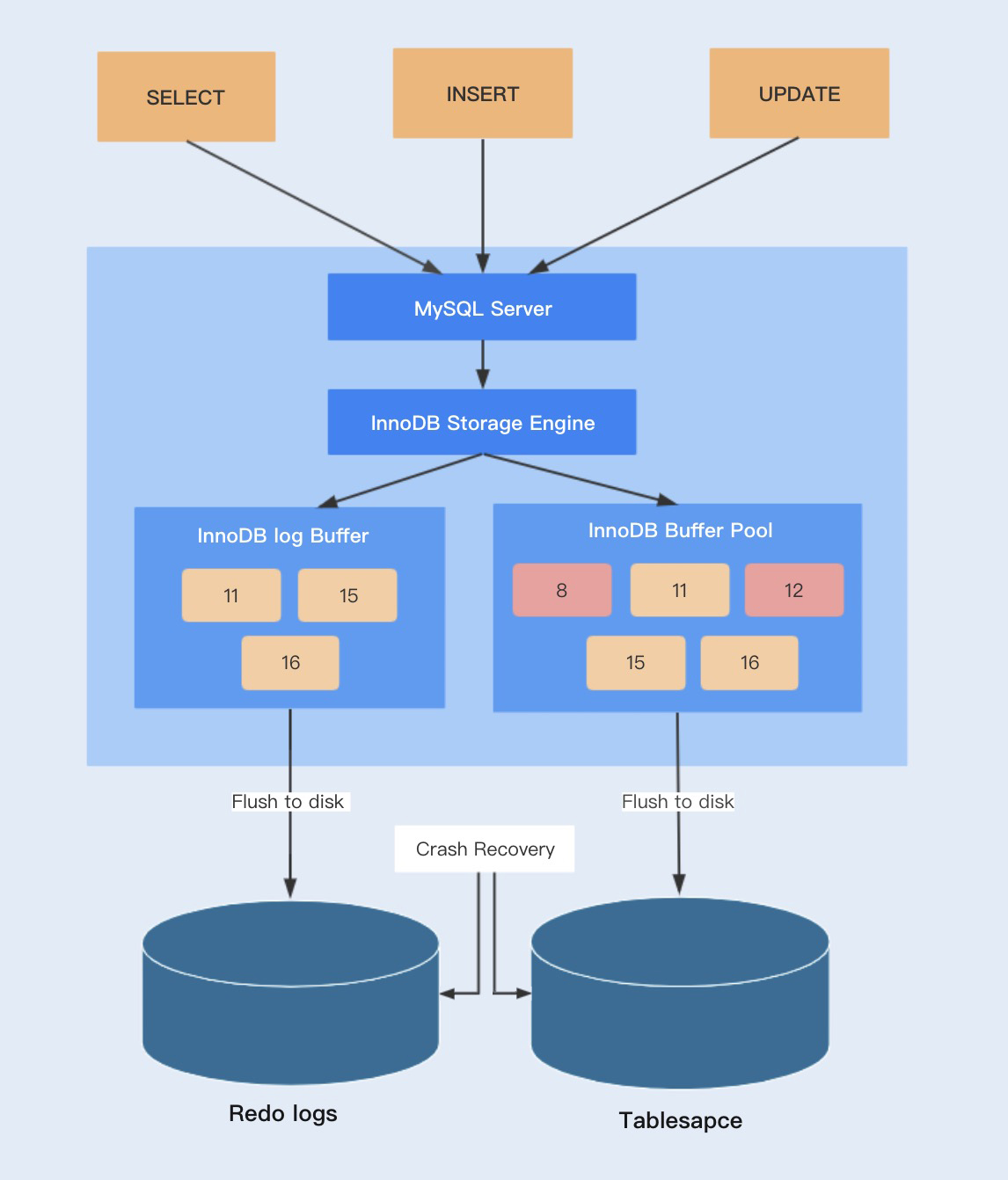
- InnoDB 的内存结构和磁盘结构
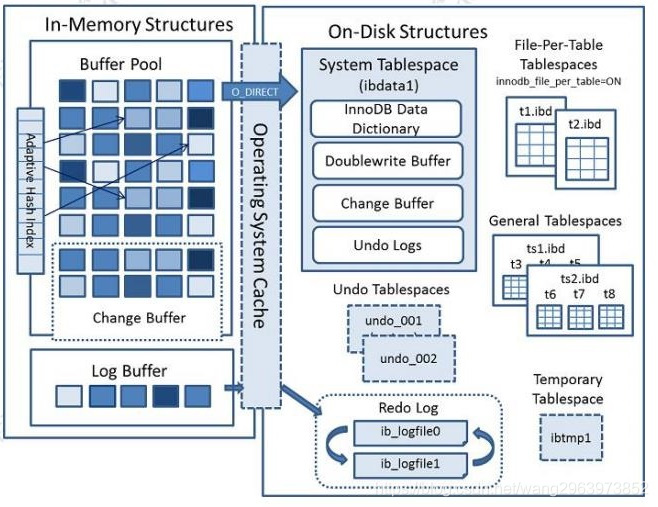
- 内存结构
- 主要分为:Buffer Pool、Change Buffer、Adaptive HashIndex、(redo)log buffer
- Innodb buffer pool
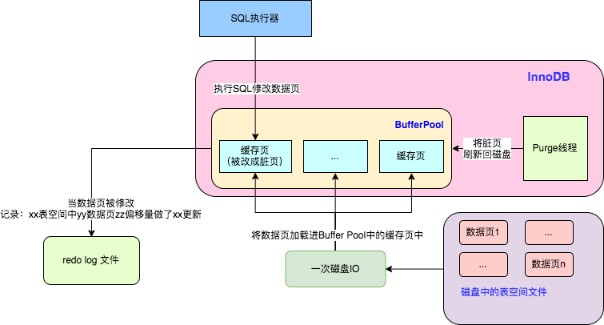
- MySQL InnoDB 缓冲池,CPU 读取或者写入数据时,不直接和低速的磁盘打交道,直接和缓冲区进行交互,从而解决了因为磁盘性能慢导致的数据库性能差的问题,弥补了两者之间的速度差异。
- Buffer Pool 中更新的数据未刷新到磁盘中,该内存页称之为脏页。最终脏页的数据会刷新到磁盘中,将磁盘中的数据覆盖。
- Buffer Pool 预热
- MySQL 在重启后,Buffer Pool 里面没有什么数据,这个时候业务上对数据库的数据操作,MySQL 就只能从磁盘中读取数据到内存中,这个过程可能需要很久才能是内存中的数据是业务频繁使用的。Buffer Pool 中数据从无到业务频繁使用热数据的过程称之为预热。所以在预热这个过程中,MySQL 数据库的性能不会特别好,并且 Buffer Pool 越大,预热过程越长。
- 为了减短这个预热过程,在 MySQL 关闭前,把 Buffer Pool 中的页面信息保存到磁盘,等到 MySQL 启动时,再根据之前保存的信息把磁盘中的数据加载到 Buffer Pool 中即可。
- 结构
- Change Buffer
- 在更新数据的时候,如果这个数据页不是唯一索引(索引的值不允许重复),也就不需要从磁盘加载索引页判断数据是不是重复(唯一性检查)。这种情况下可以先把修改记录在内存的缓冲池中,从而提升更新语句(Insert、Delete、Update)的执行速度。
- 这一块区域就是 Change Buffer。5.5 之前叫 Insert Buffer 插入缓冲,现在也能支持 delete 和 update,最后把 Change Buffer 记录到数据页的操作叫做 merge。
- 相关问题
- 什么时候发生 merge?
- 在访问这个数据页的时候、或者通过后台线程、或者数据库 shut down、redo log 写满时触发
- 什么时候发生 merge?
- 相关问题
- Adaptive Hash Index
- InnoDB 存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive)的。自适应哈希索引通过缓冲池的 B+ 树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB 存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
- (redo)Log Buffer
- 如果 Buffer Pool 里面的脏页还没有刷入磁盘时,数据库宕机或者重启,这些数据丢失。如果写操作写到一半,甚至可能会破坏数据文件导致数据库不可用,怎么办?
- 为了避免这个问题,InnoDB 把所有的修改操作专门写入一个日志文件,并且在数据库启动时从这个文件进行恢复操作(实现 crash-safe)——用它来实现事务的持久性。
- 这个文件就是磁盘的 redo log(叫做重做日志)。
- 磁盘结构
- 系统表空间 system tablespace
- 独占表空间 file-per-table tablespaces
- 我们可以让每张表独占一个表空间。这个开关通过 innodb_file_per_table 设置,默认开启。
- 通用表空间 general tablespaces
- 通用表空间也是一种共享的表空间,跟 ibdata1 类似。可以创建一个通用的表空间,用来存储不同数据库的表,数据路径和文件可以自定义
- 临时表空间 temporary tablespaces
- 存储临时表的数据,包括用户创建的临时表,和磁盘的内部临时表。对应数据目录下的 ibtmp1 文件。当数据服务器正常关闭时,该表空间被删除,下次重新产生。
- redo log
- undo Log
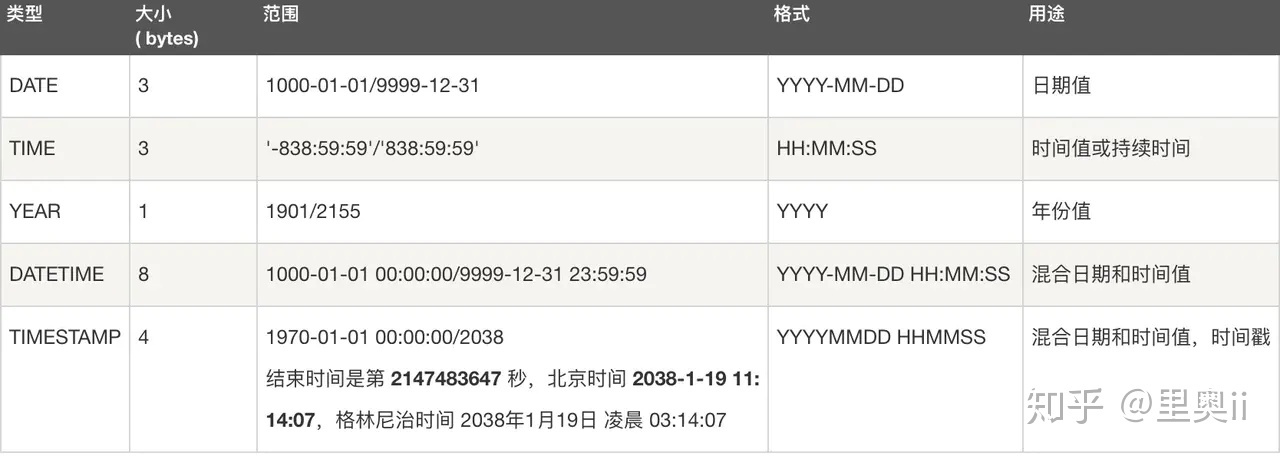
数据类型
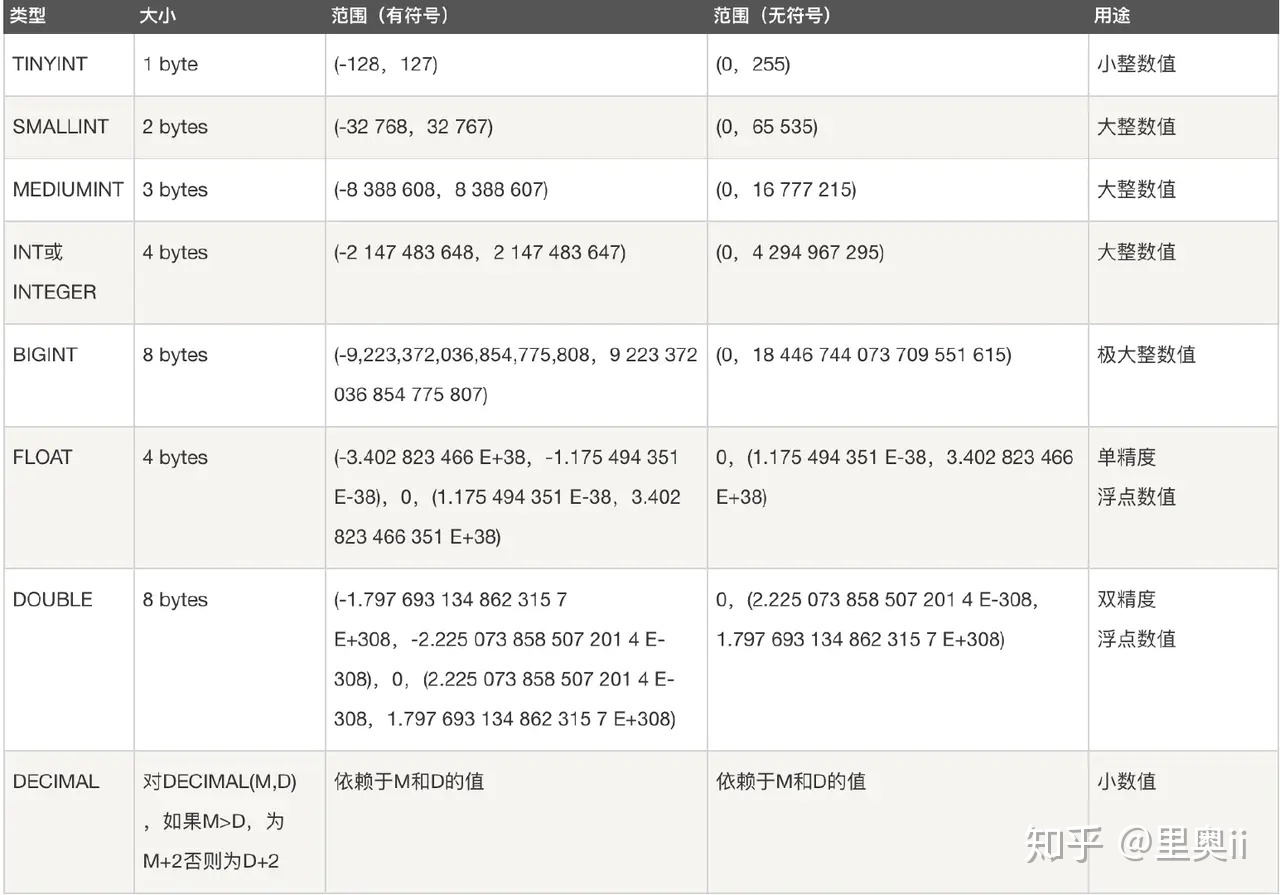
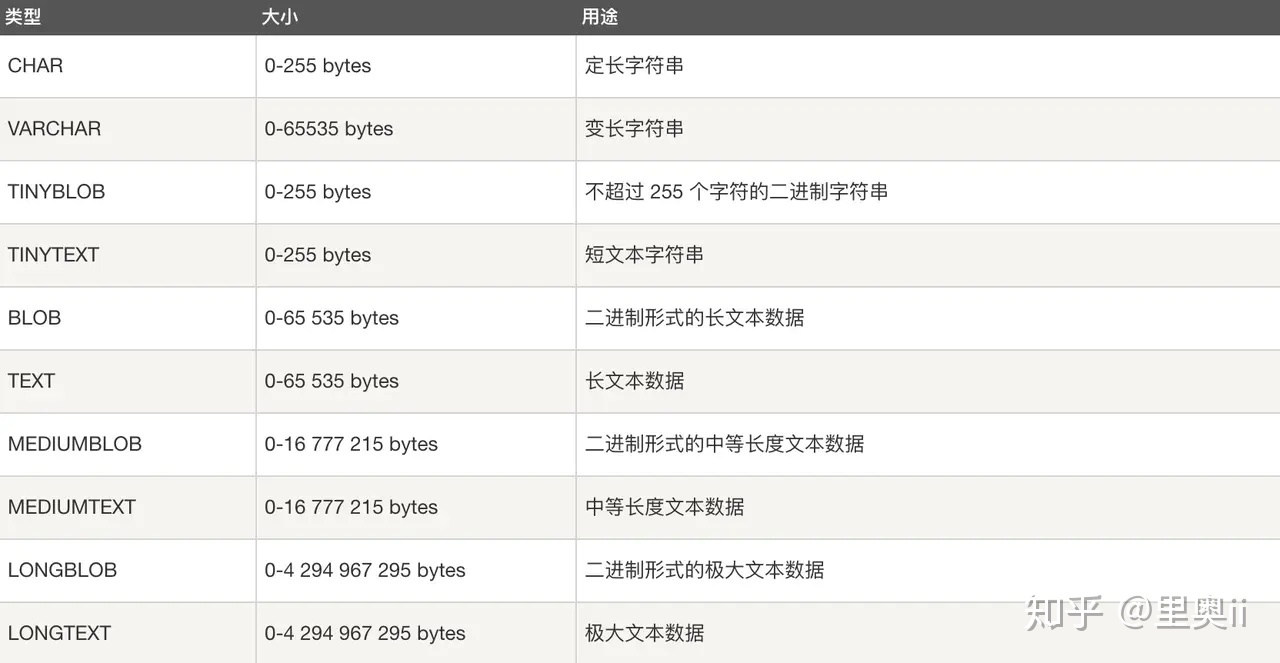
- 五大类
- 整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、INT、BIG INT
- 浮点数类型:FLOAT、DOUBLE、DECIMAL
- 字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
- 日期类型:Date、DateTime、TimeStamp、Time、Year
- 其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection 等
索引
- InnoDB
- 分类
- 物理分类
- 聚集索引
- 聚集索引就是以主键创建的索引
- 每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放,实际的数据⻚只能按照一颗 B+ 树进行排序
- 表记录的排列顺序和与索引的排列顺序一致
- 聚集索引存储记录是物理上连续存在
- 聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多
- 聚簇索引适合排序,非聚簇索引不适合用在排序的场合,因为聚簇索引叶节点本身就是索引和 数据按相同顺序放置在一起,索引序即是数据序,数据序即是索引序,所以很快。非聚簇索引叶节点是保留了一个指向数据的指针,索引本身当然是排序的,但是数据并未排序,数据查询的时候需要消耗额外更多的 I/O,所以较慢
- 更新聚集索引列的代价很高,因为会强制 innodb 将每个被更新的行移动到新的位置
- 非聚集索引
- 除了主键以外的索引
- 聚集索引的叶节点就是数据节点,而非聚簇索引的叶节点仍然是索引节点,并保留一个链接指向对应数据块
- 聚簇索引适合排序,非聚簇索引不适合用在排序的场合
- 聚集索引存储记录是物理上连续存在,非聚集索引是逻辑上的连续。
- 聚集索引
- 逻辑分类
- 唯一索引
- 主键索引
- 普通索引
- 全文索引
- 联合索引
- 最左匹配原则
- 索引覆盖
- 在查询里,联合索引已经“覆盖了”我们的查询需求,故称为覆盖索引。从辅助索引中就能直接得到查询结果,而不需要回表到聚簇索引中进行再次查询,所以可以减少搜索次数(不需要从辅助索引树回表到聚簇索引树),或者说减少IO操作(通过辅助索引树可以一次性从磁盘载入更多节点),从而提升性能。
- 索引下推
- 例子
- 在开始之前先先准备一张用户表(user),其中主要几个字段有:id、name、age、address。建立联合索引(name,age)。
- 执行
SELECT * from user where name like '陈%' and age=20
- MySQL5.6 之前的版本
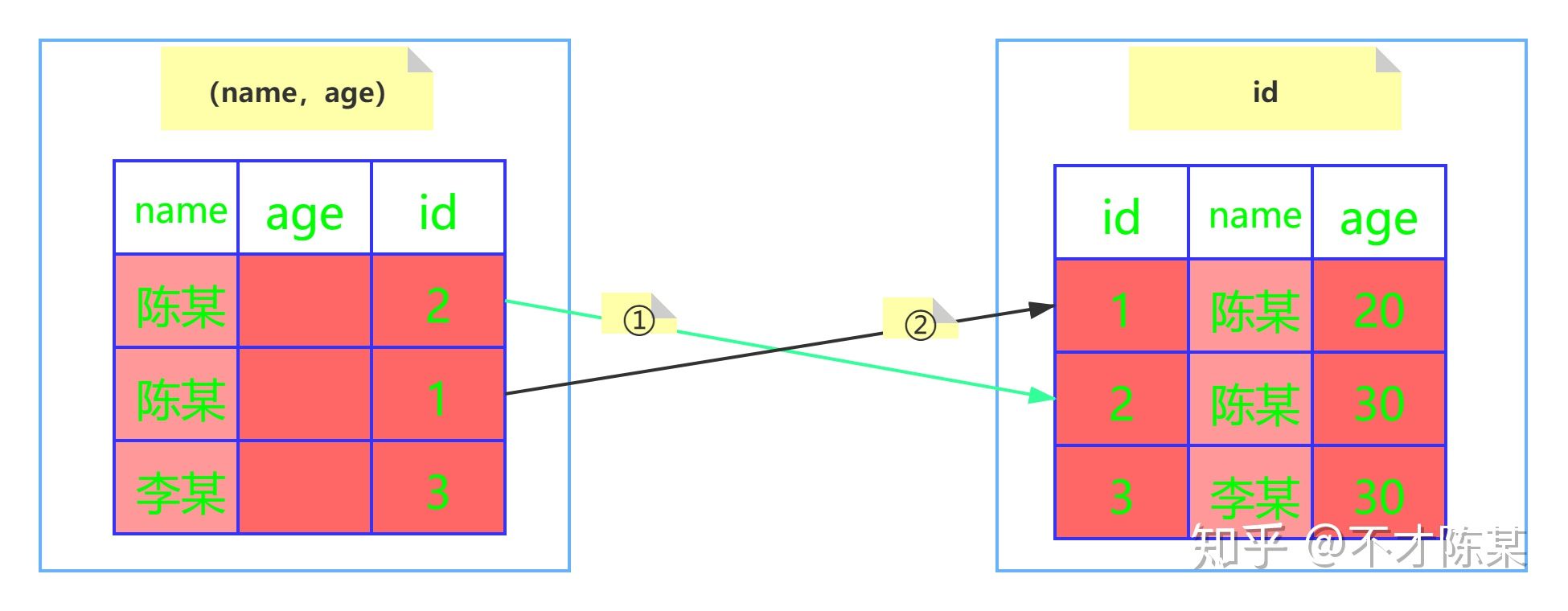
- 会忽略 age 这个字段,直接通过 name 进行查询,在索引课树上查找到了两个结果,id 分别为 2、1,然后拿着取到的 id 值一次次的回表查询,因此这个过程需要回表两次。
- MySQL5.6 及之后版本
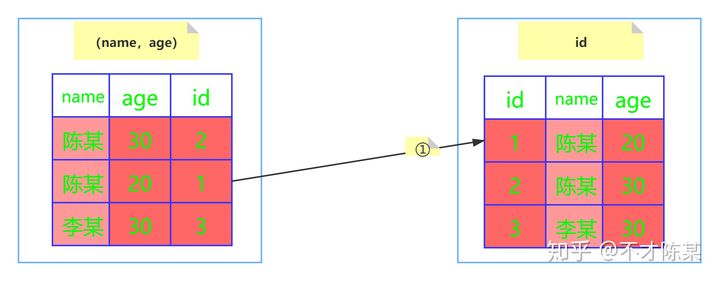
- 并没有忽略 age 这个字段,而是在索引内部就判断了 age 是否等于 20,对于不等于 20 的记录直接跳过,因此在 (name,age) 这棵索引树中只匹配到了一个记录,此时拿着这个 id 去主键索引树中回表查询全部数据,这个过程只需要回表一次。
- 例子
- 物理分类
- 优化使用
- 对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
- 不在索引上进行任何操作
- 索引上进行计算、函数、类型转换等操作都会导致索引从当前位置(联合索引多个字段,不影响前面字段的匹配)失效,可能会进行全表扫描。
- 隐式类型转换
- 在查询时一定要注意字段类型问题,比如a字段时字符串类型的,而匹配参数用的是int类型,此时就会发生隐式类型转换,相当于相当于在索引上使用函数。
- 只查询需要的列
- 查询无用的列在数据传输和解析绑定过程中会增加网络 IO,以及 CPU 的开销
- 会使得覆盖索引”失效”,这里的失效并非真正的不走索引。覆盖索引的本质就是在索引中包含所要查询的字段,而
select *将使覆盖索引失去意义,仍然需要进行回表操作
- 应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
- 应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
- 分类
事务
- 事务特点(ACID)
- 原子性(atomicity)
- MySQL 怎么保证原子性的?
- 利用 Innodb 的undo log。
- undo log 名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的 sql 语句,他需要记录你要回滚的相应日志信息。
- 例如
- 当你 delete 一条数据的时候,就需要记录这条数据的信息,回滚的时候,insert 这条旧数据
- 当你 update 一条数据的时候,就需要记录之前的旧值,回滚的时候,根据旧值执行 update 操作
- 当你 insert 一条数据的时候,就需要这条记录的主键,回滚的时候,根据主键执行 delete 操作
- undo log 记录了这些回滚需要的信息,当事务执行失败或调用了 rollback,导致事务需要回滚,便可以利用 undo log 中的信息将数据回滚到修改之前的样子。
- MySQL 怎么保证原子性的?
- 一致性(consistency)
- MySQL 怎么保证一致性的?
- 这个问题分为两个层面来说。
- 从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说 ACID 四大特性之中,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。数据库必须要实现 AID 三大特性,才有可能实现一致性。例如,原子性无法保证,显然一致性也无法保证。
- 但是,如果你在事务里故意写出违反约束的代码,一致性还是无法保证的。例如,你在转账的例子中,你的代码里故意不给 B 账户加钱,那一致性还是无法保证。因此,还必须从应用层角度考虑。
- 从应用层面,通过代码判断数据库数据是否有效,然后决定回滚还是提交数据!
- 这个问题分为两个层面来说。
- MySQL 怎么保证一致性的?
- 隔离性(isolation)
- MySQL 怎么保证隔离性的?
- 利用的是锁和 MVCC 机制。
- MySQL 怎么保证隔离性的?
- 持久性(durability)
- MySQL 怎么保证持久性的?
- 是利用 Innodb 的 redo log。MySQL 是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再刷回磁盘上。如果此时突然宕机,内存中的数据就会丢失。怎么解决这个问题?简单啊,事务提交前直接把数据写入磁盘就行啊。这么做有什么问题?
- 只修改一个页面里的一个字节,就要将整个页面刷入磁盘,太浪费资源了。毕竟一个页面 16kb 大小,你只改其中一点点东西,就要将 16kb 的内容刷入磁盘,听着也不合理。
- 毕竟一个事务里的 SQL 可能牵涉到多个数据页的修改,而这些数据页可能不是相邻的,也就是属于随机 IO。显然操作随机 IO,速度会比较慢。
- 于是,决定采用 redo log 解决上面的问题。当做数据修改的时候,不仅在内存中操作,还会在 redo log 中记录这次操作。当事务提交的时候,会将 redo log 日志进行刷盘(redo log一部分在内存中,一部分在磁盘上)。当数据库宕机重启的时候,会将 redo log 中的内容恢复到数据库中,再根据 undo log 和 binlog 内容决定回滚数据还是提交数据。
- 采用 redo log 的好处?
- 好处就是将 redo log 进行刷盘比对数据页刷盘效率高,具体表现如下
- redo log 体积小,毕竟只记录了哪一页修改了啥,因此体积小,刷盘快。
- redo log 是一直往末尾进行追加,属于顺序 IO。效率显然比随机 IO 来的快。
- 好处就是将 redo log 进行刷盘比对数据页刷盘效率高,具体表现如下
- 采用 redo log 的好处?
- 是利用 Innodb 的 redo log。MySQL 是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再刷回磁盘上。如果此时突然宕机,内存中的数据就会丢失。怎么解决这个问题?简单啊,事务提交前直接把数据写入磁盘就行啊。这么做有什么问题?
- MySQL 怎么保证持久性的?
- 原子性(atomicity)
- 实现方式
- 通过预写日志方式实现的,redo 和 undo 机制是数据库实现事务的基础
- redo 日志用来在断电/数据库崩溃等状况发生时重演一次刷数据的过程,把 redo 日志里的数据刷到数据库里,保证了事务的持久性(Durability)
- undo 日志是在事务执行失败的时候撤销对数据库的操作,保证了事务的原子性
- 事务的离级别
- Read Uncommitted(读未提交)
- 所有事务都可以看到其他未提交事务的执行结果
- 会产生脏读(Dirty Read)
- Read Committed(读已提交)
- 一个事务只能看⻅已经提交事务所做的改变
- 会产生不可重复读(Nonrepeatable Read)
- 通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了脏读(Dirty Read)问题
- 每次发起查询,都重新生成一个 ReadView
- Repeatable Read(可重读)
- MySQL 的默认事务隔离级别
- 确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
- 会产生幻读(Phantom Read)
- 幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影”行。
- 通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了不可重复读(Nonrepeatable Read)问题
- 创建事务 trx 结构的时候,就生成了当前的 global read view。使用 trx_assign_read_view 函数创建,一直维持到事务结束。在事务结束这段时间内每一次查询都不会重新重建 Read View,从而实现了可重复读。
- Serializable(串行化)
- 通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。在每个读的数据行上加上共享锁
- Read Uncommitted(读未提交)
并发控制
- LBCC
- 基于锁的并发控制 Lock Based Concurrency Control(LBCC)
- MVCC
- 多版本的并发控制 Multi Version Concurrency Control(MVCC)
- 在 Mysql 的 InnoDB 引擎中就是指在读已提交(READ COMMITTD)和可重复读(REPEATABLE READ)这两种隔离级别下的事务对于 SELECT 操作会访问版本链中的记录的过程。
- 当前读、快照读
- 当前读
- 像 select lock in share mode(共享锁),select for update、update、insert、delete(排他锁) 这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
- 快照读
- 不加锁的 select 操作就是快照读
- 当前读
- 实现原理
- 通过 Undo 日志中的版本链和 ReadView 一致性视图来实现的。
- 每行记录的隐藏字段:

- DB_TRX_ID
- 6byte,最近修改(修改/插入)事务 ID:记录创建这条记录/最后一次修改该记录的事务ID
- DB_ROLL_PTR
- 7byte,回滚指针,指向这条记录的上一个版本(存储于rollback segment里)
- DB_ROW_ID
- 6byte,隐含的自增ID(隐藏主键),如果数据表没有主键,InnoDB会自动以DB_ROW_ID产生一个聚簇索引
- 实际还有一个删除 flag 隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除 flag 变了
- Undo 日志
- undo log 主要分为两种:
- insert undo log
- 代表事务在 insert 新记录时产生的 undo log,只在事务回滚时需要,并且在事务提交后可以被立即丢弃
- update undo log
- 事务在进行 update 或 delete 时产生的 undo log;不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被 purge 线程统一清除
- purge
- 更新或者删除操作都只是设置一下老记录的 deleted_bit,并不真正将过时的记录删除。
- 为了节省磁盘空间,InnoDB 有专门的 purge 线程来清理 deleted_bit 为 true 的记录。为了不影响 MVCC 的正常工作,purge 线程自己也维护了一个 read view(这个 read view 相当于系统中最老活跃事务的 read view);如果某个记录的 deleted_bit 为 true,并且 DB_TRX_ID 相对于 purge 线程的 read view 可见,那么这条记录一定是可以被安全清除的。
- purge
- 事务在进行 update 或 delete 时产生的 undo log;不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被 purge 线程统一清除
- insert undo log
- 插入数据时流程
- 举例
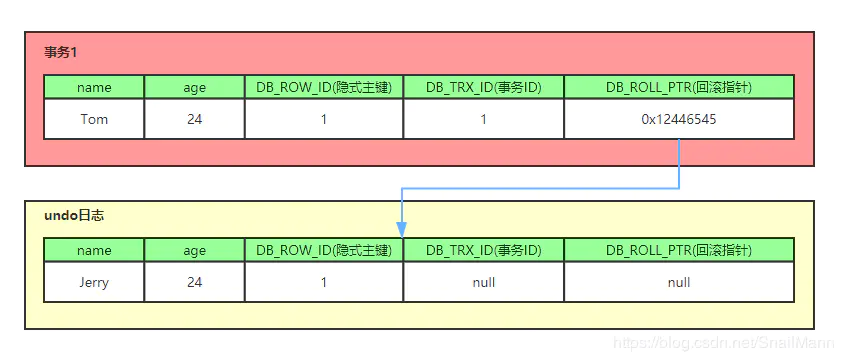
- 比如一个有个事务插入 person 表插入了一条新记录,记录如下,name 为 Jerry, age 为 24 岁,隐式主键是 1,事务 ID 和回滚指针,我们假设为 NULL
- 现在来了一个事务 1 对该记录的 name 做出了修改,改为 Tom
- 在事务 1 修改该行(记录)数据时,数据库会先对该行加排他锁
- 然后把该行数据拷贝到 undo log 中,作为旧记录,既在 undo log 中有当前行的拷贝副本
- 拷贝完毕后,修改该行 name 为 Tom,并且修改隐藏字段的事务 ID 为当前事务 1 的 ID, 我们默认从 1 开始,之后递增,回滚指针指向拷贝到 undo log 的副本记录,既表示我的上一个版本就是它
- 事务提交后,释放锁
- 又来了个事务 2 修改 person 表的同一个记录,将 age 修改为 30 岁
- 在事务 2 修改该行数据时,数据库也先为该行加锁
- 然后把该行数据拷贝到 undo log 中,作为旧记录,发现该行记录已经有 undo log 了,那么最新的旧数据作为链表的表头,插在该行记录的 undo log 最前面
- 修改该行 age 为 30 岁,并且修改隐藏字段的事务 ID 为当前事务 2 的 ID, 那就是 2,回滚指针指向刚刚拷贝到 undo log 的副本记录
- 事务提交,释放锁
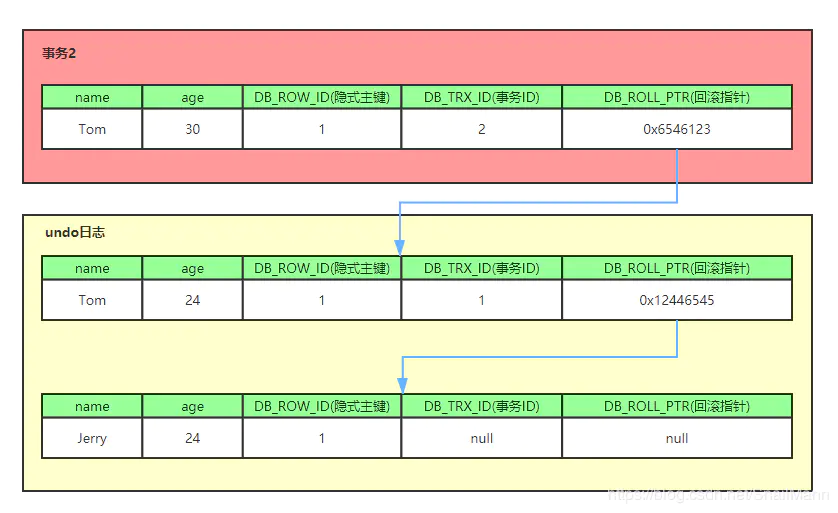
- 从上面,我们就可以看出,不同事务或者相同事务的对同一记录的修改,会导致该记录的 undo log 成为一条记录版本线性表,既链表,undo log 的链首就是最新的旧记录,链尾就是最早的旧记录(当然就像之前说的该 undo log 的节点可能是会 purge 线程清除掉,向图中的第一条 insert undo log,其实在事务提交之后可能就被删除丢失了,不过这里为了演示,所以还放在这里)
- 比如一个有个事务插入 person 表插入了一条新记录,记录如下,name 为 Jerry, age 为 24 岁,隐式主键是 1,事务 ID 和回滚指针,我们假设为 NULL
- 举例
- undo log 主要分为两种:
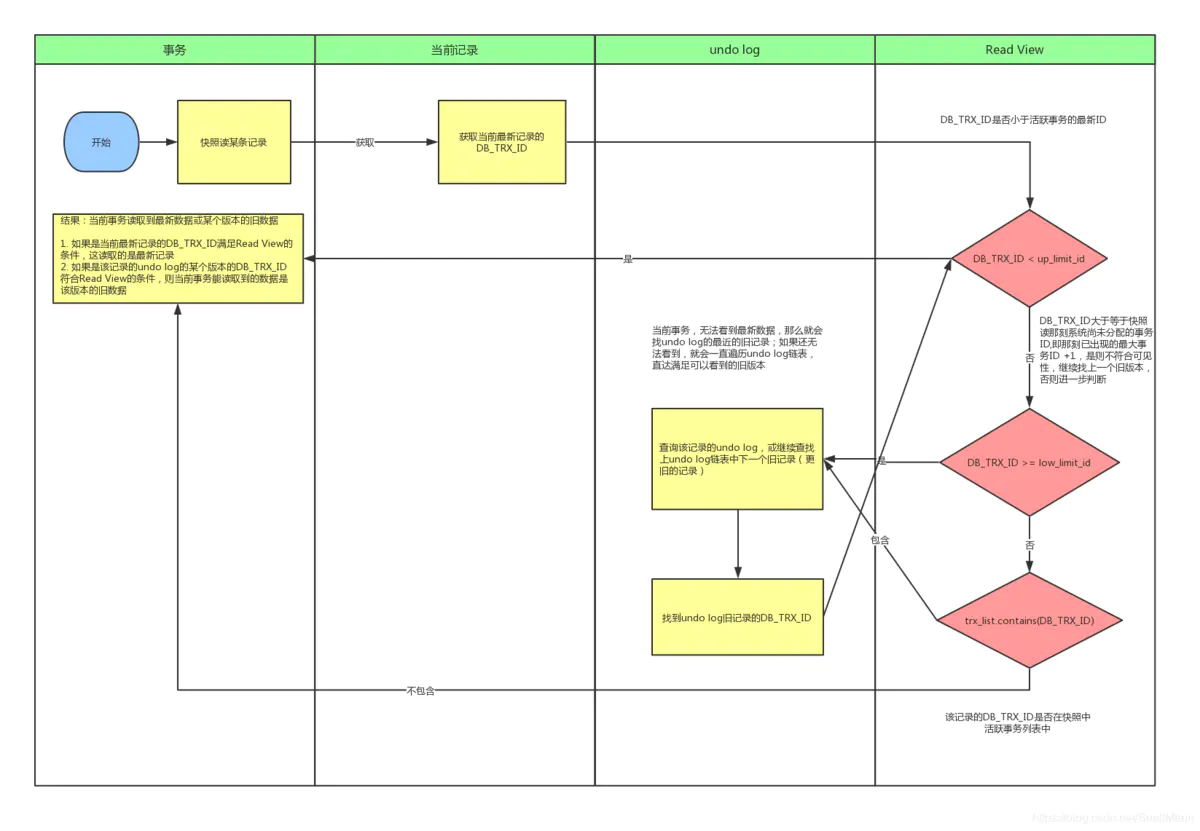
- Read View(读视图)
- Read View 就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照。
- 流程
- 三个全局属性
- trx_list
- 一个数值列表,用来维护 Read View 生成时刻系统正活跃的事务 ID
- up_limit_id
- 记录 trx_list 列表中事务 ID 最小的ID
- low_limit_id
- ReadView 生成时刻系统尚未分配的下一个事务 ID,也就是目前已出现过的事务 ID 的最大值+1
- trx_list
- 流程
- 首先比较 DB_TRX_ID < up_limit_id, 如果小于,则当前事务能看到 DB_TRX_ID 所在的记录,如果大于等于进入下一个判断
- 接下来判断 DB_TRX_ID >= low_limit_id , 如果大于等于则代表 DB_TRX_ID 所在的记录在 Read View 生成后才出现的,那对当前事务肯定不可见,如果小于则进入下一个判断
- 判断 DB_TRX_ID 是否在活跃事务之中,
trx_list.contains(DB_TRX_ID),如果在,则代表我 Read View 生成时刻,你这个事务还在活跃,还没有 Commit,你修改的数据,我当前事务也是看不见的;如果不在,则说明,你这个事务在 Read View 生成之前就已经 Commit 了,你修改的结果,我当前事务是能看见的
- 三个全局属性
日志
- undo log
- 基本概念
- undo log 有两个作用
- 提供回滚
- 多个行版本控制(MVCC)
- undo log 和 redo log 记录物理日志不一样,它是逻辑日志。可以认为当 delete 一条记录时,undo log 中会记录一条对应的 insert 记录,反之亦然,当 update 一条记录时,它记录一条对应相反的 update 记录。
- 当执行 rollback 时,就可以从 undo log 中的逻辑记录读取到相应的内容并进行回滚。有时候应用到行版本控制的时候,也是通过 undo log 来实现的:当读取的某一行被其他事务锁定时,它可以从 undo log 中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
- undo log 是采用段(segment)的方式来记录的,每个 undo 操作在记录的时候占用一个 undo log segment。
- 另外,undo log 也会产生 redo log,因为 undo log 也要实现持久性保护。
- undo log 有两个作用
- 存储方式
- innodb 存储引擎对undo的管理采用段的方式。rollback segment 称为回滚段,每个回滚段中有 1024 个 undo log segment。
- 版本区别
- 老版本,只支持 1 个 rollback segment,这样就只能记录 1024 个 undo log segment。
- MySQL5.5 可以支持 128 个 rollback segment,即支持 128*1024 个 undo 操作,还可以通过变量 innodb_undo_logs(5.6 版本以前该变量是 innodb_rollback_segments)自定义多少个 rollback segment,默认值为 128。
- 版本区别
- innodb 存储引擎对undo的管理采用段的方式。rollback segment 称为回滚段,每个回滚段中有 1024 个 undo log segment。
- delete/update 操作的内部机制
- insert 操作无需分析,就是插入行而已
- delete 操作实际上不会直接删除,而是将 delete 对象打上 delete flag,标记为删除,最终的删除操作是 purge 线程完成的。
- update 分为两种情况:update 的列是否是主键列。
- 如果不是主键列,在 undo log 中直接反向记录是如何 update 的。即 update 是直接进行的。
- 如果是主键列,update 分两部执行:先删除该行,再插入一行目标行。
- 基本概念
- redo log
- 出现原因
- 在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。这么做会有严重的性能问题,主要体现在两个方面:
- 因为 Innodb 是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
- 一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机 I/O 写入性能太差!
- 在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。这么做会有严重的性能问题,主要体现在两个方面:
- redo log 是重做日志,提供再写入操作,实现事务的持久性。日志记录事务对数据页做了哪些修改。
- redo log 又包括了内存中的日志缓冲(redo log buffer)以及保存在磁盘的重做日志文件(redo log file)
- 前者存储在内存中,容易丢失,后者持久化在磁盘中,不会丢失。
- 底层原理
- 结构
- InnoDB 的 redo log 的大小是固定的,分别有多个日志文件采用循环方式组成一个循环闭环,当写到结尾时,会回到开头循环写日志。
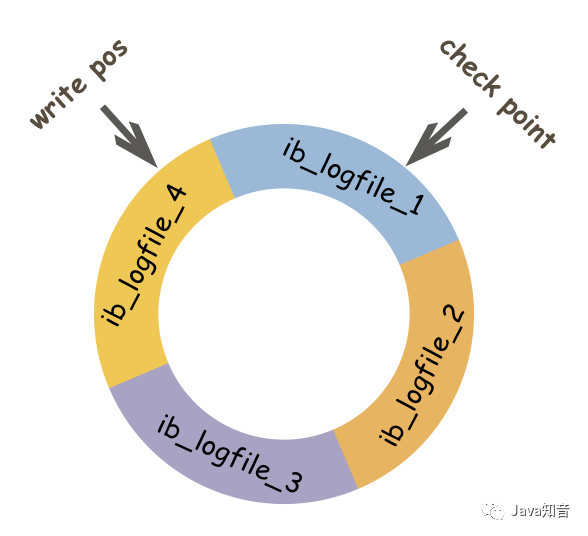
- write pos 表示 redo log 当前记录的 LSN(逻辑序列号)位置,check point 表示数据页更改记录刷盘后对应 redo log 所处的 LSN(逻辑序列号)位置。
- write pos 到 check point 之间的部分是 redo log 空着的部分,用于记录新的记录;check point 到 write pos 之间是 redo log 待落盘的数据页更改记录。当 write pos 追 上check point 时,会先推动 check point 向前移动,空出位置再记录新的日志。
- InnoDB 的 redo log 的大小是固定的,分别有多个日志文件采用循环方式组成一个循环闭环,当写到结尾时,会回到开头循环写日志。
- 日志块(log block)
- innodb 存储引擎中,redo log 以块为单位进行存储的,每个块占 512 字节,这称为 redo log block。所以不管是 log buffer 中还是 os buffer 中以及 redo log file on disk 中,都是这样以 512 字节的块存储的。
- 每个 redo log block 由 3 部分组成:日志块头、日志块尾和日志主体。其中日志块头占用 12 字节,日志块尾占用 8 字节,所以每个 redo log block 的日志主体部分只有 512-12-8=492 字节。
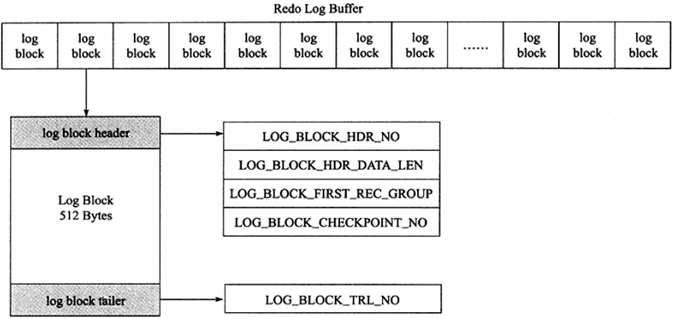
- 日志块头包含 4 部分:
- log_block_hdr_no:(4 字节)该日志块在 redo log buffer 中的位置 ID。
- log_block_hdr_data_len:(2 字节)该 log block 中已记录的 log 大小。写满该 log block 时为 0x200,表示 512 字节。
- log_block_first_rec_group:(2 字节)该 log block 中第一个 log 的开始偏移位置。
- 因为有时候一个数据页产生的日志量超出了一个日志块,这是需要用多个日志块来记录该页的相关日志。例如,某一数据页产生了 552 字节的日志量,那么需要占用两个日志块,第一个日志块占用 492 字节,第二个日志块需要占用 60个字节,那么对于第二个日志块来说,它的第一个 log 的开始位置就是 73 字节(60+12)。如果该部分的值和 log_block_hdr_data_len 相等,则说明该 log block 中没有新开始的日志块,即表示该日志块用来延续前一个日志块。
- lock_block_checkpoint_no:(4 字节)写入检查点信息的位置。
- 日志尾只有一个部分:log_block_trl_no,该值和块头的 log_block_hdr_no 相等。
- 因为 redo log 记录的是数据页的变化,当一个数据页产生的变化需要使用超过 492 字节的 redo log 来记录,那么就会使用多个 redo log block 来记录该数据页的变化。
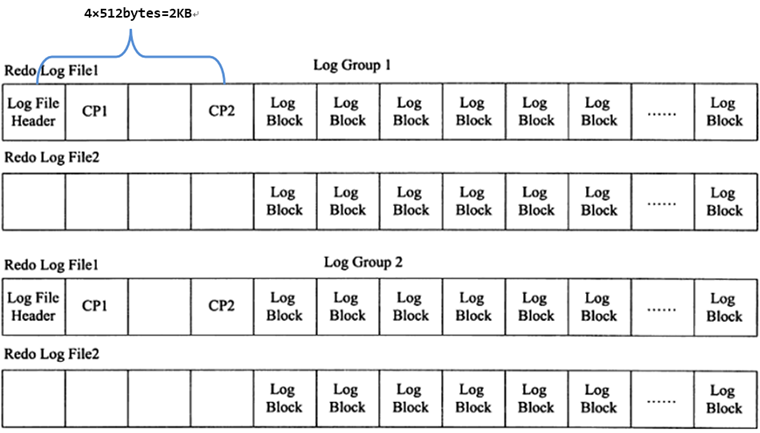
- log group 和 redo log file
- log group 表示的是 redo log group,一个组内由多个大小完全相同的 redo log file 组成。这个组是一个逻辑的概念,并没有真正的文件来表示这是一个组。
- 写入方式
- 在 innodb 将 log buffer 中的 redo log block 刷到这些 log file 中时,会以追加写入的方式循环轮训写入。即先在第一个 log file(即 ib_logfile0)的尾部追加写,直到满了之后向第二个 log file(即 ib_logfile1)写。当第二个 log file 满了会清空一部分第一个 log file 继续写入。
- 结构
- 在每个组的第一个 redo log file 中,前 2KB 记录 4 个特定的部分,从 2KB 之后才开始记录 log block。除了第一个 redo log file 中会记录,log group 中的其他 log file 不会记录这 2KB,但是却会腾出这 2KB 的空间。
- 在每个组的第一个 redo log file 中,前 2KB 记录 4 个特定的部分,从 2KB 之后才开始记录 log block。除了第一个 redo log file 中会记录,log group 中的其他 log file 不会记录这 2KB,但是却会腾出这 2KB 的空间。
- redo log file 的大小对 innodb 的性能影响非常大,设置的太大,恢复的时候就会时间较长,设置的太小,就会导致在写 redo log 的时候循环切换 redo log file。
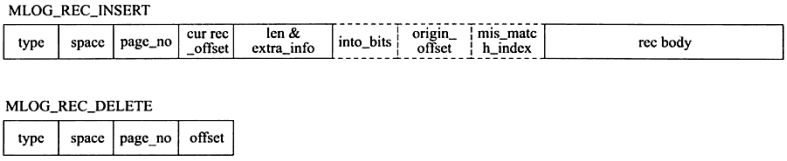
- redo log 的格式
- 因为 innodb 存储引擎存储数据的单元是页(和 SQL Server 中一样),所以 redo log 也是基于页的格式来记录的。默认情况下,innodb 的页大小是 16KB,一个页内可以存放非常多的 log block(每个 512 字节),而 log block 中记录的又是数据页的变化。
- 其中 log block 中 492 字节的部分是 log body,该 log body 的格式分为 4 部分:
- redo_log_type:占用 1 个字节,表示 redo log 的日志类型。
- space:表示表空间的 ID,采用压缩的方式后,占用的空间可能小于 4 字节。
- page_no:表示页的偏移量,同样是压缩过的。
- redo_log_body 表示每个重做日志的数据部分,恢复时会调用相应的函数进行解析。
- 例如 insert 语句和 delete 语句写入 redo log 的内容是不一样的。
- 结构
- 流程
- InnoDB 的更新操作采用的是 Write Ahead Log 策略。
- WAL 即 Write Ahead Log,WAL 的主要意思是说在将元数据的变更操作写入磁盘之前,先预先写入到一个 log 文件中。
- 可以将对数据文件的随机写转换为堆 redo log 的顺序写,提高了性能。
- 只有当 redo log 日志满了的情况下,才会主动触发脏页刷新到磁盘,而脏页不仅只有 redo log 日志满了的情况才会刷新到磁盘,以下几种情况同样会触发脏页的刷新:
- 系统内存不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘;
- MySQL 认为空闲的时间,这种情况没有性能问题;
- MySQL 正常关闭之前,会把所有的脏页刷入到磁盘,这种情况也没有性能问题。
- 启动、宕机时的写入
- 启动 InnoDB 的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为 redo log 记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如 binlog)要快很多。
- 重启 InnoDB 时,首先会检查磁盘中数据页的 LSN,如果数据页的 LSN 小于日志中的 LSN,则会从 checkpoint 开始恢复。
- 还有一种情况,在宕机前正处于 checkpoint 的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的 LSN 大于日志中的 LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
- 写入机制
- MySQL 支持用户自定义在 commit 时如何将 log buffer 中的日志刷 log file 中。这种控制通过变量 innodb_flush_log_at_trx_commit 的值来决定。该变量有 3 种值:0、1、2,默认为 1。但注意,这个变量只是控制 commit 动作是否刷新 log buffer 到磁盘。
- 当设置为 1 的时候,事务每次提交都会将 log buffer 中的日志写入 os buffer 并调用
fsync()刷到 log file on disk 中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO 的性能较差。 - 当设置为 0 的时候,事务提交时不会将 log buffer 中日志写入到 os buffer,而是每秒写入 os buffer 并调用
fsync()写入到 log file on disk 中。也就是说设置为 0 时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失 1 秒钟的数据。 - 当设置为 2 的时候,每次提交都仅写入到 os buffer,然后是每秒调用
fsync()将 os buffer 中的日志写入到 log file on disk。【一般建议选择取值 2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失 1 秒的事务提交数据。】 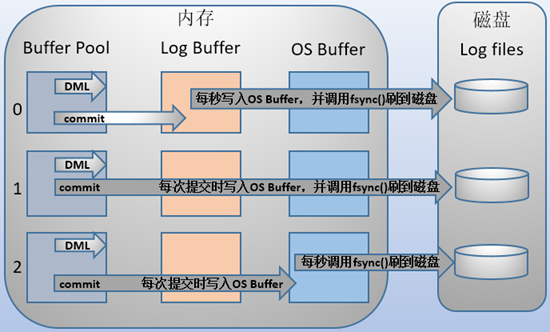
- 当设置为 1 的时候,事务每次提交都会将 log buffer 中的日志写入 os buffer 并调用
- MySQL 支持用户自定义在 commit 时如何将 log buffer 中的日志刷 log file 中。这种控制通过变量 innodb_flush_log_at_trx_commit 的值来决定。该变量有 3 种值:0、1、2,默认为 1。但注意,这个变量只是控制 commit 动作是否刷新 log buffer 到磁盘。
- 相关问题
- redo log 与 binlog 的区别?
- redo log 是在 InnoDB 存储引擎层产生,而 binlog 是 MySQL 数据库的上层产生的,并且二进制日志不仅仅针对 INNODB 存储引擎,MySQL 数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。
- 两种日志记录的内容形式不同。MySQL 的 binlog 是逻辑日志,其记录是对应的 SQL 语句。而 innodb 存储引擎层面的重做日志是物理日志。
- 两种日志与记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而 innodb 存储引擎的重做日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
- 二进制日志仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于 innodb 存储引擎的重做日志,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志写入是并发的,并非在事务提交时写入,其在文件中记录的顺序并非是事务开始的顺序。
- binlog 不是循环使用,在写满或者重启之后,会生成新的 binlog 文件,redo log 是循环使用。
- binlog 可以作为恢复数据使用,主从复制搭建,redo log 作为异常宕机或者介质故障后的数据恢复使用。
- redo log 与 binlog 的区别?
- 出现原因
- binlog
- binlog 是二进制日志文件,用于记录 MySQL 的数据更新或者潜在更新(比如 DELETE 语句执行删除而实际并没有符合条件的数据),在 MySQL 主从复制中就是依靠的 binlog。
- binlog 是 MySQL 的逻辑日志,并且由 Server 层进行记录,使用任何存储引擎的 MySQL 数据库都会记录 binlog 日志。
- 逻辑日志:可以简单理解为记录的就是 sql 语句。
- 物理日志:因为 MySQL 数据最终是保存在数据页中的,物理日志记录的就是数据页变更。
- binlog 是通过追加的方式进行写入的,可以通过 max_binlog_size 参数设置每个 binlog 文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
- binlog 的三种工作模式:
- Row level
- 简介:日志中会记录每一行数据被修改的情况,然后在 slave 端对相同的数据进行修改。
- 优点:能清楚的记录每一行数据修改的细节
- 缺点:数据量太大
- Statement level(默认)
- 简介:每一条被修改数据的 sql 都会记录到 master 的 bin-log 中,slave 在复制的时候 sql 进程会解析成和原来 master 端执行过的相同的 sql 再次执行。在主从同步中一般是不建议用 statement 模式的,因为会有些语句不支持,比如语句中包含 UUID 函数,以及 LOAD DATA IN FILE 语句等
- 优点:解决了 Row level 的缺点,不需要记录每一行的数据变化,减少 bin-log 日志量,节约磁盘 IO,提高新能
- 缺点:容易出现主从复制不一致
- Mixed
- 简介:在 Mixed 模式下,一般的语句修改使用 statment 格式保存 binlog,如一些函数,statement 无法完成主从复制的操作,则采用 row 格式保存 binlog,MySQL 会根据执行的每一条具体的 sql 语句来区分对待记录的日志形式,也就是在 Statement 和 Row 之间选择一种。
- Row level
- 写入机制
- 事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
- binlog cache
- 系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
- binlog cache
- 一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。
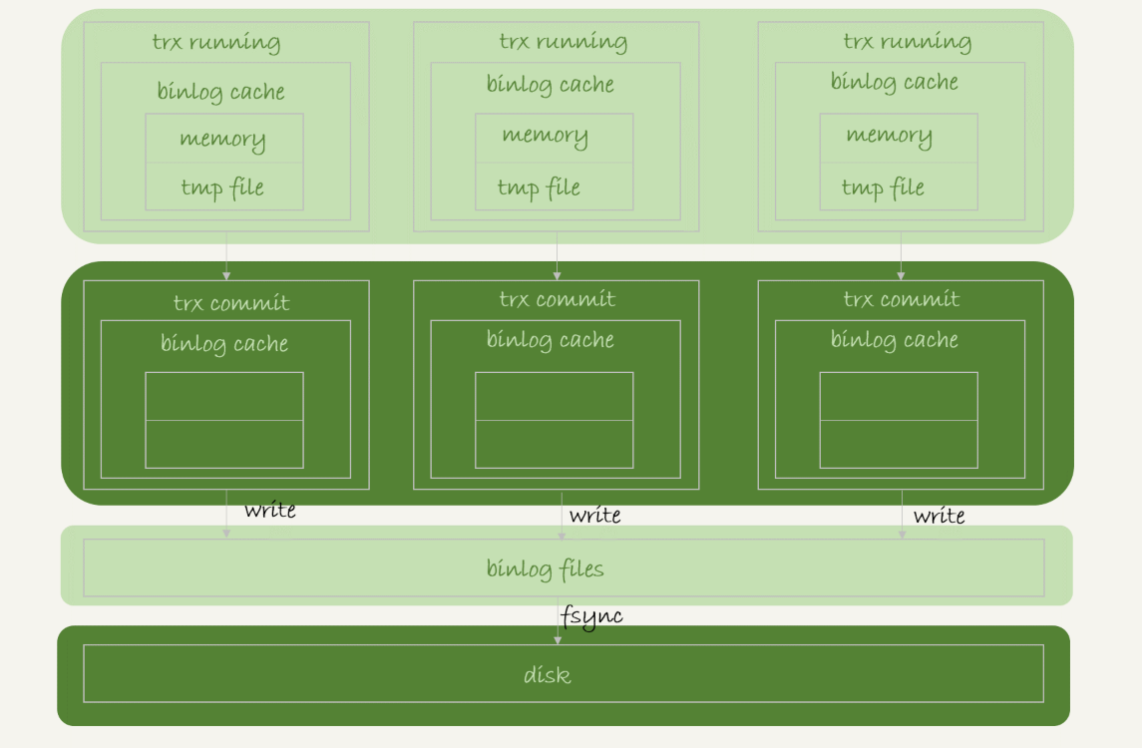
- 可以看到,每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
- 图中的 write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。
- 图中的 fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁盘的 IOPS(Input/Output Operations Per Second)。
- write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- 0:表示每次提交事务都只 write,不 fsync;
- 1:表示每次提交事务都会执行 fsync;(默认值)
- N:表示每次提交事务都 write,但累积 N 个事务后才 fsync。
- 事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
- 两阶段提交
- MySQL 最开始是没有 InnoDB 引擎的,binlog 日志位于 Server 层,只是用于归档和主从复制,本身不具备 crash safe 的能力。而 InnoDB 依靠 redo log 具备了 crash safe 的能力,redo log 和 binlog 同时记录,就需要保证两者的一致性。
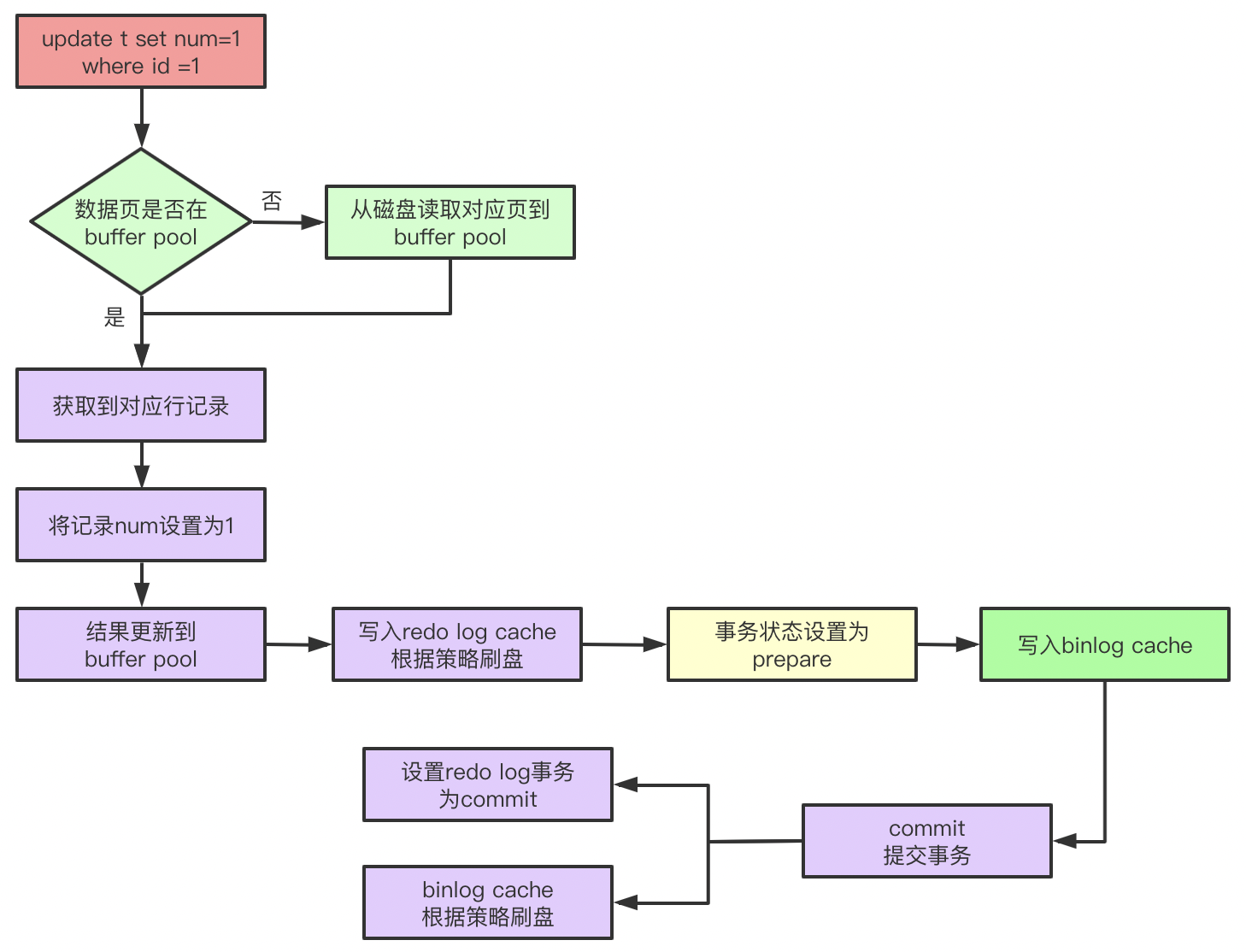
- 提交过程
- prepare 阶段
- 此阶段负责:
- 在 Innodb 层获取独占模式的 prepare_commit_mutex,将事务的 trx_id 写入 redo log(redo 日志的写机制为 WAL 所以在事务修改前就会写 redo buffer 而不是 commit 时一次性写入)。
- 此阶段负责:
- commit 阶段
- 第一步,写 binlog
- 此阶段调用两个方法
write()和fsync(),前者负责将 binlog 从 binlog cache 写入文件系统缓存,后者负责将文件系统缓存中的 binlog 写入 disk,后者的调用机制是由 sync_binlog 参数控制的。 - 注意 binlog 也是有 cache 的,在事务执行过程中生成的 binlog 会被存储在 binlog cache 中,此 cache 大小由 binlog_cache_size,这个 size 是 session 级别的,即每个会话都有一个 binlog cache。
- 此阶段调用两个方法
- 第二步,innodb 进行 commit
- 在 Innodb 层写入 commit flag,调用 write 和 fsync 将 commit 信息的 redo 写入磁盘,然后释放 prepare_commit_mutex。
- 引擎层将 redo log buffer 中的 redo 写入文件系统缓存(write),然后将文件系统缓存中的 redo log 写入 disk(fsync),写入机制取决于 innodb_flush_log_at_trx_commit 参数。
- 第一步,写 binlog
- redo log 和 binlog 是两种不同的日志,就类似于分布式中的多节点提交请求,需要保证事务的一致性。redo log 和 binlog 有一个公共字段 XID,代表事务 ID。当参数 innodb_support_xa 打开时,在执行事务的第一条 SQL 时候会去注册 XA,根据第一条 SQL 的 query id 拼凑 XID 数据,然后存储在事务对象中。
- 如果两个日志单纯的分开提交,则可能会引发一些问题,如果简单分开提交,那么对于一条更新语句执行,有两种情况:
- 先写 binlog,后写 redo log:如果 binlog 写入了,在写 redo log 之前数据库宕机。那么在重启恢复的时候,通过 binlog 恢复了数据没问题。但是由于 redo log 没有写入,这个事务应该无效,也就是原库中就不应该有这条语句对应的更新。但是通过 binlog 恢复数据后,数据库中就多了这条更新
- 先写 redo log,后写 binlog:如果 redo log 写入了,在写 binlog 之前数据库宕机。那么在重启恢复的时候,通过 binlog 恢复从库,那么相对于主库来说,从库就少了这条更新
- 采取了两段提交之后,怎么做 crash 恢复呢?
- 如果在写入 binlog 之前宕机了,那么事务需要回滚;如果事务 commit 之前宕机了,那么此时 binlog cache 中的数据可能还没有刷盘,那么验证 binlog 的完整性:到 redo log 中找到最近事务的 XID,根据这个 XID 到 binlog 中去找(XID Event),如果找到了,说明在 binlog 中对应事务已经提交,那么提交 redo log 中事务即可;否则需要回滚事务。
主从复制
- 主从复制、读写分离就是为了数据库能支持更大的并发。
- 原理
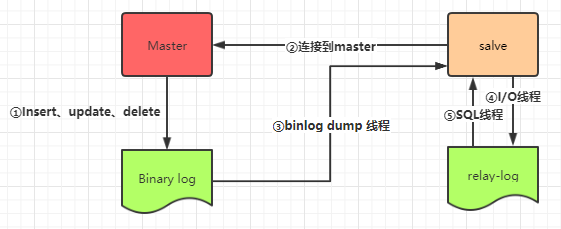
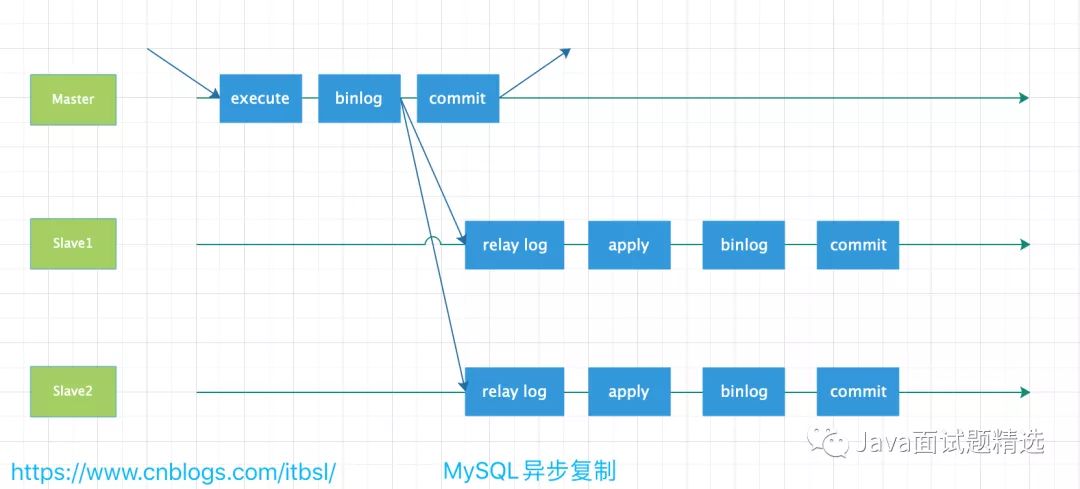
- 当 Master 节点进行 insert、update、delete 操作时,会按顺序写入到 binlog 中。
- salve 从库连接 master 主库,Master 有多少个 slave 就会创建多少个 binlog dump 线程。
- 当 Master 节点的 binlog 发生变化时,binlog dump 线程会通知所有的 salve 节点,并将相应的 binlog 内容推送给 slave 节点。
- I/O 线程接收到 binlog 内容后,将内容写入到本地的 relay-log。
- SQL 线程读取 I/O 线程写入的 relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。
- 同步策略
- 「同步策略」:Master 会等待所有的 Slave 都回应后才会提交,这个主从的同步的性能会严重的影响。
- 「半同步策略」:Master 至少会等待一个 Slave 回应后提交。
- 从 MySQL5.5 开始,引入了半同步复制,此时的技术暂且称之为传统的半同步复制。技术发展到 MySQL5.7后,已经演变为增强半同步复制(也成为无损复制)。
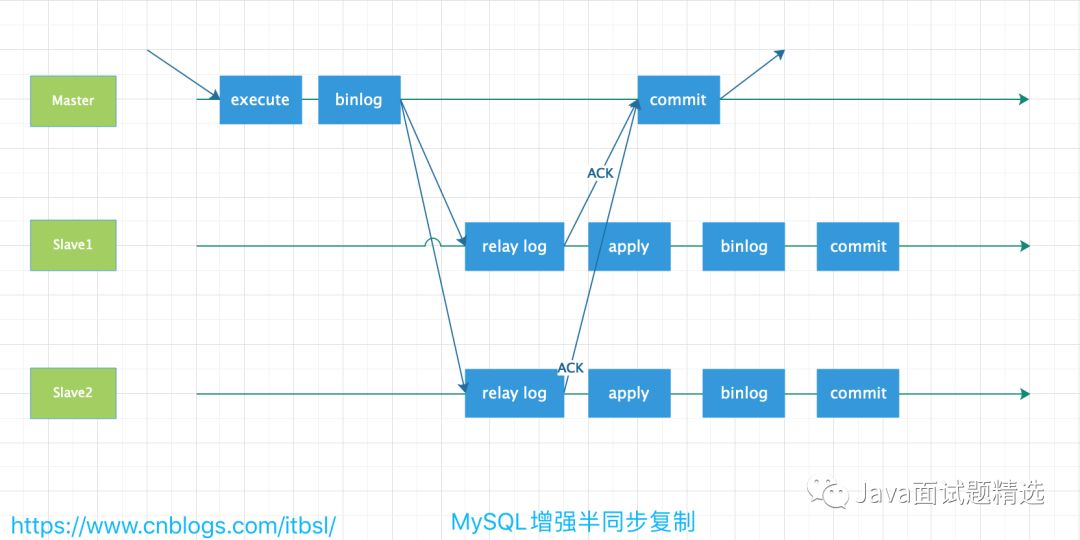
- 传统的半同步复制
- 在传统的半同步复制中,主库写数据到 BINLOG,且执行 Commit 操作后,会一直等待从库的 ACK,即从库写入 Relay Log 后,并将数据落盘,返回给主库消息,通知主库可以返回前端应用操作成功,这样会出现一个问题,就是实际上主库已经将该事务 Commit 到了事务引擎层,应用已经可以可以看到数据发生了变化,只是在等待返回而已,如果此时主库宕机,有可能从库还没能写入 Relay Log,就会发生主从库不一致。
- 增强半同步复制就
- 增强半同步复制就是为了解决这个问题,做了微调,即主库写数据到 BINLOG 后,就开始等待从库的应答 ACK,直到至少一个从库写入 Relay Log 后,并将数据落盘,然后返回给主库消息,通知主库可以执行 Commit 操作,然后主库开始提交到事务引擎层,应用此时可以看到数据发生了变化。
- 传统的半同步复制
- 半同步复制模式下,假如在传送 BINLOG 日志到从库时,从库宕机或者网络延迟,导致 BINLOG 并没有及时地传送到从库上,此时主库上的事务会等待一段时间(时间长短由参数 rpl_semi_sync_master_timeout 设置的毫秒数决定),如果 BINLOG 在这段时间内都无法成功发送到从库上,则 MySQL 自动调整复制为异步模式,事务正常返回提交结果给客户端。
- 从 MySQL5.5 开始,引入了半同步复制,此时的技术暂且称之为传统的半同步复制。技术发展到 MySQL5.7后,已经演变为增强半同步复制(也成为无损复制)。
- 「异步策略」:Master 不用等待 Slave 回应就可以提交。
- 「延迟策略」:Slave 要落后于 Master 指定的时间。
- 缺点
- 从机是通过 binlog 日志从 master 同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现 master 写入数据后,slave 读取数据不一定能马上读出来。
- 主从不同步的可能情况
- 网络延迟
- 由于 MySQL 主从复制是基于 binlog 的一种异步复制,通过网络传送 binlog 文件,理所当然网络延迟是主从不同步的绝大多数的原因,特别是跨机房的数据同步出现这种几率非常的大,所以做读写分离,注意从业务层进行前期设计。
- 主从两台机器的负载不一致
- 由于 MySQL 主从复制是主数据库上面启动 1 个 io 线程,而从上面启动 1 个 sql 线程和 1 个 io 线程,当中任何一台机器的负载很高,忙不过来,导致其中的任何一个线程出现资源不足,都将出现主从不一致的情况。
- max_allowed_packet 设置不一致
- 主数据库上面设置的 max_allowed_packet 比从数据库大,当一个大的 sql 语句,能在主数据库上面执行完毕,从数据库上面设置过小,无法执行,导致的主从不一致。
- 自增键不一致
- key 自增键开始的键值跟自增步长设置不一致引起的主从不一致。
- 同步参数设置问题
- MySQL 异常宕机情况下,如果未设置 sync_binlog=1 或者 innodb_flush_log_at_trx_commit=1 很有可能出现 binlog 或者 relaylog 文件出现损坏,导致主从不一致。
- 主库 binlog 格式为 Statement,同步到从库执行后可能造成主从不一致。
- 主库执行更改前有执行
set sql_log_bin=0,会使主库不记录 binlog,从库也无法变更这部分数据。 - 从节点未设置只读,误操作写入数据。
- 主库或从库意外宕机,宕机可能会造成 binlog 或者 relaylog 文件出现损坏,导致主从不一致
- 主从实例版本不一致,特别是高版本是主,低版本是从的情况下,主数据库上面支持的功能从数据库上面可能不支持
- 网络延迟
- 关于事务
- 在同一事务内,读写操作应该均走主库,用于保证数据一致性。
- 主从一致性检查
- 利用 percona-toolkit 工具
- 主库增加或者修改数据即往 MQ 里面放入消息,异步验证一致性
语句执行顺序
- MySQL 的语句一共分为 11 步,最先执行的总是 FROM 操作,最后执行的是 LIMIT 操作。其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入,只是这些虚拟的表对用户来说是透明的,但是只有最后一个虚拟的表才会被作为结果返回。如果没有在语句中指定某一个子句,那么将会跳过相应的步骤。
- 步骤
- FROM: 对 FROM 的左边的表和右边的表计算笛卡尔积。产生虚表 VT1。
- ON: 对虚表 VT1 进行 ON 筛选,只有那些符合
<join-condition>的行才会被记录在虚表 VT2 中。 - JOIN: 如果指定了 OUTER JOIN(比如 left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表 VT2 中,产生虚拟表 VT3, rug from 子句中包含两个以上的表的话,那么就会对上一个 join 连接产生的结果 VT3 和下一个表重复执行步骤 1~3 这三个步骤,一直到处理完所有的表为止。
- WHERE: 对虚拟表 VT3 进行WHERE条件过滤。只有符合
<where-condition>的记录才会被插入到虚拟表 VT4 中。 - GROUP BY: 根据 group by 子句中的列,对 VT4 中的记录进行分组操作,产生 VT5。
- CUBE | ROLLUP: 对表 VT5 进行 cube 或者 rollup 操作,产生表 VT6。使用聚集函数进行计算。
- HAVING: 对虚拟表 VT6 应用 having 过滤,只有符合
<having-condition>的记录才会被插入到虚拟表 VT7 中。 - SELECT: 执行 select 操作,选择指定的列,插入到虚拟表 VT8 中。
- DISTINCT: 对 VT8 中的记录进行去重。产生虚拟表 VT9。
- ORDER BY: 将虚拟表 VT9 中的记录按照
<order_by_list>进行排序操作,产生虚拟表 VT10。 - LIMIT:取出指定行的记录,产生虚拟表 VT11, 并将结果返回。
命令
- 事务
- MySQL 默认是开启事务的(自动提交)
select @@autocommit;(autocommit=1)
- 事务开启
- 修改默认提交
set autocommit=0; begin;或start transaction;- 事务手动提交:
commit; - 事务手动回滚:
rollback;
- 修改默认提交
- MySQL 默认是开启事务的(自动提交)