Java
Basic Java
面向对象
- 三大特性
- 封装
- 指一种将抽象性函式接口的实现细节部分包装、隐藏起来的方法。
- 继承
- 子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
- 访问权限
- public
- protected
- protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
- default
- 包级可见
- private
- 重写与重载
- 重写(Override)
- 存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
- 三个限制(使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。)
- 子类方法的访问权限必须大于等于父类方法;
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
- 在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
this.func(this)super.func(this)this.func(super)super.func(super)
- 重载(Overload)
- 存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
- 应该注意的是,返回值不同,其它都相同不算是重载。
- 重写(Override)
- 多态
- 多态是同一个行为具有多个不同表现形式或形态的能力。
- 封装
- 类
- 抽象类、接口
- 接口
- 接口的属性默认都是 static 和 final 的。
- 版本区别
- 接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
- 从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
- 接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。从 Java 9 开始,允许将方法定义为 private,这样就能定义某些复用的代码又不会把方法暴露出去。
- 抽象类(abstract class)和接口(interface)区别
- 语法上的区别
- 抽象类只能单继承,接口可以多实现。
- 抽象类可以有构造方法,接口中不能有构造方法。
- 抽象类中可以有成员变量,接口中没有成员变量,只能有常量(默认就是 public static final)
- 抽象类中可以包含非抽象的方法,在 Java 7 之前接口中的所有方法都是抽象的,在 Java 8 之后,接口支持非抽象方法:default 方法、静态方法等。Java 9 支持私有方法、私有静态方法。
- 抽象类中的抽象方法类型可以是任意修饰符,Java 8 之前接口中的方法只能是 public 类型,Java 9 支持 private 类型。
- 设计思想的区别
- 接口是自上而下的抽象过程,接口规范了某些行为,是对某一行为的抽象。我需要这个行为,我就去实现某个接口,但是具体这个行为怎么实现,完全由自己决定。
- 抽象类是自下而上的抽象过程,抽象类提供了通用实现,是对某一类事物的抽象。我们在写实现类的时候,发现某些实现类具有几乎相同的实现,因此我们将这些相同的实现抽取出来成为抽象类,然后如果有一些差异点,则可以提供抽象方法来支持自定义实现。
- 语法上的区别
- 接口
- 枚举
- 枚举是一个被命名的整型常数的集合,用于声明一组带标识符的常数。
- 在 JDK 1.5 之前没有枚举类型,那时候一般用接口常量来替代。而使用 Java 枚举类型 enum 可以更贴近地表示这种常量。
- 常见用法
- 常量
- switch
- 向枚举中添加新方法
- 覆盖枚举的方法
- 实现接口
- 使用接口组织枚举
- 枚举集合
- java.util.EnumSet 和 java.util.EnumMap 是两个枚举集合。EnumSet 保证集合中的元素不重复;EnumMap 中的 key 是 enum 类型,而 value 则可以是任意类型。
- 注解
- Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
- 格式
public @interface 注解名称{ 属性列表; }- Java 8 中,做一次 16 位右位移异或混合 - ``` //Java 8中的散列值优化函数 static final int hash(Object key) { int h; int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); //key.hashCode()为哈希算法,返回初始哈希值 }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395- 分类
- 自定义注解
- JDK 内置注解
- 比如 @Override 检验方法重写,@Deprecated 标识方法过期等
- 第三方框架提供的注解
- 比如 SpringMVC 的 @Controller 等
- 使用位置
- 实际开发中,注解常常出现在类、方法、成员变量、形参位置。
- 作用
- 目的是为当前读取该注解的程序提供判断依据。比如程序只要读到加了 @Test 的方法,就知道该方法是待测试方法,又比如 @Before 注解,程序看到这个注解,就知道该方法要放在 @Test 方法之前执行。
- 级别
- 注解和类、接口、枚举是同一级别的。
- 元注解
- 所谓元注解,就是加在注解上的注解。
- 常用元注解
- @Documented
- 用于制作文档
- @Target
- 加在注解上,限定该注解的使用位置。不写的话,好像默认各个位置都是可以的。如果需要限定注解的使用位置,可以在自定义的注解上使用该注解。
- @Retention(注解的保留策略)
- 注解的保留策略有三种:SOURCE/CLASS/RUNTIME
- 注解主要被反射读取
- 反射只能读取内存中的字节码信息
- RetentionPolicy.CLASS 指的是保留到字节码文件,它在磁盘内,而不是内存中。虚拟机将字节码文件加载进内存后注解会消失
- 要想被反射读取,保留策略只能用RUNTIME,即运行时仍可读取
- 注解的读取并不只有反射一种途径。比如 @Override,它由编译器读取(你写完代码 ctrl+s 时就编译了),而编译器只是检查语法错误,此时程序尚未运行。@Override 的保留策略是 SOURCE。
- 属性的数据类型及特别的属性
- value 属性
- 如果注解的属性只有一个,且叫 value,那么使用该注解时,可以不用指定属性名,因为默认就是给 value 赋值。但是注解的属性如果有多个,无论是否叫value,都必须写明属性的对应关系。
- 数组属性
-
- 反射
- 每个类都有一个**Class**对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
- 类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 `Class.forName("com.mysql.jdbc.Driver")` 这种方式来控制类的加载,该方法会返回一个 Class 对象。
- 反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
- 反射的三种方式
- 通过 new 对象实现反射:`obj.getClass()`
- 通过路径实现:`Class.forName()`
- 通过类名实现:`Clazz.class`
- Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- **Field** :可以使用 `get()` 和 `set()` 方法读取和修改 Field 对象关联的字段;
- **Method** :可以使用 `invoke()` 方法调用与 Method 对象关联的方法;
- **Constructor** :可以用 Constructor 的 `newInstance()` 创建新的对象。
- 整体流程
- 准备阶段:编译期装载所有的类,将每个类的元信息保存至 Class 类对象中,每一个类对应一个 Class 对象
- 获取 Class 对象:调用 `x.class/x.getClass()/Class.forName()` 获取 x 的 Class 对象 clz
- 进行实际反射操作:通过 clz 对象获取 Field/Method/Constructor 对象进行进一步操作
- 优点
- **可扩展性**:应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
- **类浏览器和可视化开发环境**:一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
- **调试器和测试工具**:调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
- 缺点
- **性能开销**:反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
- **安全限制**:使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
- **内部暴露**:由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
- 范型
- 泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
- 限定通配符和非限定通配符
- 限定通配符
- `<? extends T>`
- 确保类型必须是T的子类来设定类型的上界
- `<? super T>`
- 确保类型必须是T的父类来设定类型的下界
- 非限定通配符
- `<?>`
- 用任意类型来替代
- 实现原理
- 泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如`List<String>`在运行时仅用一个 List 来表示。这样做的目的,是确保能和 Java5 之前的版本开发二进制类库进行兼容。你无法在运行时访问到类型参数,因为编译器已经把泛型类型转换成了原始类型。
### 关键字
- 保留关键字
- const
- 常量,常数:用于修改字段或局部变量的声明。
- goto
- 转到:指定跳转到标签,找到标签后,程序将处理从下一行开始的命令
- 访问修饰符的关键字
- public (公有的):可跨包
- protected(受保护的):当前包内可用
- private(私有的):当前类可用
- 定义类、接口、抽象类和实现接口、继承类的关键字、实例化对象
- class(类):`public class A(){}` 花括号里是已实现的方法体,类名需要与文件名相同
- interface(接口):`public interface B(){}` 花括号里有方法体,但没有实现,方法体句子后面是英文分号 ; 结尾
- abstract(声明抽象):`public abstract class C(){}` 介于类与接口中间,可以有,也可以没有已经实现的方法体
- implemenst(实现):用于类或接口,实现接口 `public class A interface B(){}`
- extends(继承):用于类继承类 `public class A extends D(){}`
- new(创建新对象):`A a=new A();` A 表示一个类
- 包的关键字
- import(引入包的关键字):当使用某个包的一些类时,仅需要类名
- package(定义包的关键字):将所有相关的类放在一个包类以便查找修改等
- 数据类型的关键字
- byte(字节型):8bit
- char(字节型):16bit
- boolean(布尔型):--
- short(短整型):16bit
- int(整型):32bit
- float(浮点型):32bit
- long(长整型):64bit
- double(双精度):64bit
- void(无返回):`public void A(){}` 其他需要反回的经常与 return 连用
- null(空值)
- true(真)
- false(假)
- 条件循环(流程控制)
- if(如果):if(条件语句{执行代码}如果条件语句成立,就开始执行{}里面的内容
- else(否则,或者):常与 if 连用,用法相同:`if(...){...}else{...}`
- while(当什么时候):while(条件语句){执行代码}
- for(满足三个条件时):`for(初始化循环变量;判断条件;循环变量值){}`
- switch(选择结构):`switch(表达式){case 常量表达式1: 语句1;...case 常量表达式2; 语句2; default:语句;}` default 就是如果没有匹配的 case 就执行它,default 并不是必须的。case 后的语句可以不用大括号。
- case(匹配switch的表达式里的结果):同上
- default(默认):default 就是如果没有匹配的 case 就执行它,default 并不是必须的
- do(运行):通常与 while 连用
- break(跳出循环):直接跳出循环,执行循环体后的代码
- continue(继续):中断本次循环,并开始下一轮循环
- return(返回):return 一个返回值类型
- instanceof(实例):一个二元操作符,和 ==、>、<是 同一类的。测试它左边的对象是否是它右边的类的实例,返回 boolean 类型的数据
- 修饰方法、类、属性和变量
- static(静态的)
- 静态变量
- 对应 *实例变量*
- 静态方法
- 方法中不能有 this 和 super 关键字,因为这两个关键字与具体对象关联。
- 静态语句块
- 静态内部类
- 非静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。而静态内部类不需要。
- 静态内部类不能访问外部类的非静态的变量和方法。
- 静态导包
- 在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
- 初始化顺序
- 静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
- final(最终的不可被改变)
- 数据
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
- 方法
- 不能被子类重写。
- private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
- 类
- 不允许被继承。
- super(调用父类的方法):常见 `public void paint(Graphics g){super.paint(g);...}`
- this(当前类的父类的对象):调用当前类中的方法(表示调用这个方法的对象)`this.addActionListener(al);` 等等
- native(本地)
- strictfp(严格,精准)
- synchronized(线程,同步):一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块
- transient(短暂)
- volatile(易失)
- 可⻅性
- volatile 可⻅性是由指令原子性保证的,在 jmm 中定义了 8 类原子性指令,比如 write、store、read、load。而 volatile 就要求 write-store、load-read 成为一个原子性操作,这样子可以确保在读取的时候都是从主内存读入,写入的时候会同步到主内存中。
- JVM 线程工作时的原子性指令有:
- lock
- 将主内存中的变量锁定,为一个线程所独占。
- unclock
- 将 lock 加的锁定解除,此时其它的线程可以有机会访问此变量。
- read
- 将主内存中的变量值读到工作内存当中。
- load
- 将 read 读取的值保存到工作内存中的变量副本中。
- use
- 将值传递给线程的代码执行引擎。
- assign
- 将执行引擎处理返回的值重新赋值给变量副本。
- store
- 将变量副本的值存储到主内存中。
- write
- 将 store 存储的值写入到主内存的共享变量当中。
- MESI协议:在早期的 CPU 中,是通过在总线加 LOCK #锁的方式实现的,但这种方式开销太大,所以 Intel 开发了缓存一致性协议,也就是 MESI 协议,该解决缓存一致性的思路是:当 CPU 写数据时,如果发现操作的变量是共享变量,即在其他 CPU 中也存在该变量的副本,那么他会发出信号通知其他 CPU 将该变量的缓存行设置为无效状态。当其他 CPU 使用这个变量时,首先会去嗅探是否有对该变量更改的信号,当发现这个变量的缓存行已经无效时,会从新从内存中读取这个变量。
- volatile 内部实现机制就是 MESI 协议,应该是先判断该变量的缓存行状态是否失效,如果失效,才会重新从内存中读取该变量的值,而不是每次都从内存中读取。
- 有序性(防止指令重排序)
- **如何保证线程间可⻅和避免指令重排?**
- 是由内存屏障来保证的,由两个内存屏障:
- 一个是编译器屏障:阻止编译器重排,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
- 第二个是 cpu 屏障:sfence 保证写入,lfence 保证读取,lock 类似于锁的方式。java 多执行了一个 `load addl $0x0, (%esp)` 操作,这个操作相当于一个 lock 指令,就是增加一个完全的内存屏障指令。
- 保障变量单次读,写操作的原子性,但不能保证 i++ 这种操作的原子性,因为本质是读、写两次操作
- 错误处理
- catch(处理异常)
- try(捕获异常)
- finally(有没有异常都执行)
- throw(抛出一个异常对象)
- throws(声明一个异常可能被抛出)
- 其他
- enum(枚举)
- assert(断言)
### Java 基本类型
- boolean
- 在 Java 虚拟机中没有任何供 boolean 值专用的字节码指令,Java 语言表达式所操作的 boolean 值,在编译之后都使用 Java 虚拟机中的 int 数据类型来代替,而 boolean 数组将会被编码成 Java 虚拟机的 byte 数组,每个元素 boolean 元素占 8 位。**具体还取决于虚拟机的实现**。
- **那虚拟机为什么要用 int 来代替 boolean 呢?为什么不用 byte 或 short,这样不是更节省内存空间吗。**
- 经过查阅资料发现,使用 int 的原因是,对于当下 32 位的处理器(CPU)来说,一次处理数据是 32 位(这里不是指的是 32/64 位系统,而是指 CPU 硬件层面),32 位 CPU 使用 4 个字节是最为节省的,哪怕你是 1 个 bit 他也是占用 4 个字节。因为 CPU 寻址系统只能 32 位 32 位地寻址,具有高效存取的特点。
- byte
- 8 位带符号二进制数的取值范围是 `[-128, 127]`
- 计算时候将他们提升为 int 类型,再进行计算
- short
- 16 位
- int
- 32 位
- long
- 64 位
- float
- 32 位
- double
- 64 位
- **自动类型转换规则**
- 基本就是先转换为高位数据类型,再参加运算,结果也是最高位的数据类型;
1. 如操作数之一为 double,则另一个操作数先被转化为 double,再参与算术运算。
2. 如两操作数均不为 double,当操作数之一为 float,则另一操作数先被转换为 float,再参与运算。
3. 如两操作数均不为 double 或 float,当操作数之一为 long,、则另一操作数先被转换为 long,再参与算术运算。
4. 如两操作数均不为 double、float 或 long,则两操作数先被转换为 int,再参与运算。
- byte short char 运算会转换为 int;
- **当运算符为自动递增运算符(++)或自动递减运算符(--)时,如果操作数为 byte,short 或 char 类型不发生改变。**
- **如采用 ++、--、+=、*= 等缩略形式的运算符,系统会自动强制将运算结果转换为目标变量的类型。**
- 基本类型对应的缓冲池如下【在使用这些基本类型对应的包装类型时,如果该数值范围在缓冲池范围内,就可以直接使用缓冲池中的对象。】:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
### 语法
- switch
- 从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
- switch 不支持 long、float、double,是因为 switch 的设计初衷是对那些只有少数几个值的类型进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
### 内置对象
#### Object
- Object 通用方法
- `public native int hashCode()`
- `public boolean equals(Object obj)`
- `protected native Object clone() throws CloneNotSupportedException`
- `clone()` 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 c`lone()` 方法,就会抛出 CloneNotSupportedException。
- `public String toString()`
- `public final native Class<?> getClass()`
- `protected void finalize() throws Throwable {}`
- 子类可以覆盖该方法以实现资源清理工作,GC 在回收对象之前调用该方法。
- 与C++中的析构函数不是对应的。C++ 中的析构函数调用的时机是确定的(对象离开作用域或 delete 掉),但 Java 中的 finalize 的调用具有不确定性
- 不建议用 finalize 方法完成“非内存资源”的清理工作,但建议用于:
- 清理本地对象(通过JNI创建的对象);
- 作为确保某些非内存资源(如 Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法。
- finalize 的问题
- 一些与 finalize 相关的方法,由于一些致命的缺陷,已经被废弃了,如 `System.runFinalizersOnExit()` 方法、`Runtime.runFinalizersOnExit()` 方法
- `System.gc()` 与 `System.runFinalization()` 方法增加了 finalize 方法执行的机会,但不可盲目依赖它们
- Java 语言规范并不保证 finalize 方法会被及时地执行、而且根本不会保证它们会被执行
- finalize 方法可能会带来性能问题。因为 JVM 通常在单独的低优先级线程中完成 finalize 的执行
- 对象再生问题:finalize 方法中,可将待回收对象赋值给 GC Roots 可达的对象引用,从而达到对象再生的目的
- finalize 方法至多由 GC 执行一次(用户当然可以手动调用对象的 finalize 方法,但并不影响 GC 对 finalize 的行为)
- finalize 的执行过程(生命周期)
- 当对象变成(GC Roots)不可达时,GC 会判断该对象是否覆盖了 finalize 方法,若未覆盖,则直接将其回收。否则,若对象未执行过 finalize 方法,将其放入 F-Queue 队列,由一低优先级线程执行该队列中对象的 finalize 方法。执行 finalize 方法完毕后,GC 会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。
- 一般用途
- 对象复活
- 覆盖 finalize 方法以确保资源释放
- 作为一个补充操作,以防用户忘记“关闭”资源,JDK 中 FileInputStream、FileOutputStream、Connection 类均用了此“技术”
- 版本
- 在 Java 9 中该方法已经被标记为废弃,并添加新的 java.lang.ref.Cleaner,提供了更灵活和有效的方法来释放资源
- `public final native void notify()`
- `public final native void notifyAll()`
- `public final native void wait(long timeout) throws InterruptedException`
- `public final void wait(long timeout, int nanos) throws InterruptedException`
- `public final void wait() throws InterruptedException`
#### String、StringBuilder、StringBuffer
- StringBuilder
- 线程不安全
- StringBuffer
- 线程安全
- String
- String 类是 final 类,也即意味着 String 类不能被继承,并且它的成员方法都默认为 final 方法。
- String 类包含三个成员变量:char value[],int offset,int count,他们分别用来:存储真正的字符数组、存储数组的第一个位置索引、存储字符串中包含的字符个数。
- 在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 `coder` 来标识使用了哪种编码。
- 字符串拼接
- 在字符串拼接的场景下,Java 编译器会自动进行优化,新建一个 StringBuilder 对象,然后调用 append 方法进行字符串的拼接。而在最后,调用了 StringBuilder 的 toString 方法,生成了一个新的字符串对象,而不是引用的常量池中的常量。
- 方法:
- `substring()`
- JDK 6:会创建一个新的 String 对象,但是这个 String 的数组然指向堆中的同一个字符数组。这两个对象中只有 count 和 offset 的值是不同的。
- **存在的问题**:如果有一个很长的字符串,但是你只需要使用很短的一段,于是你使用 substring 进行切割,但是由于你实际上引用了整个字符串,这个很长的字符串无法被回收。往小了说,造成了存储空间的浪费,往大了说,可能造成内存泄漏。
- JDK 7:会在堆中创建一个新的数组
- 相关问题
- **为什么 String 在 Java 是不可更改的?**
- 字符串常量池的需要
- 当一个 string 被创建如果这个 string 已经在内存里面存在了,那个存在的 string 的引用被返回,而不是创建个新的对象和返回它的引用。
- 缓存哈希值
- 在 Java 中,string 的哈希值经常被用。举个例子,在 HashMap 中。保持不变,可以保证总是返回相同的哈希值。所以它可以被缓存而不用担心被改变。这意味这不需要在使用的时候每次都计算哈希值。这将更高效。
- 使其他类的使用更加容易
- 安全
- String 在很多 Java 的类中,网络连接中,打开的文件中经常被作为参数使用。如果 String 是可以改变的,一个连接或者文件将有可能被改变,这将导致严肃的安全威胁。这个方法认为它正连接到一个机器,但是实际上不是。易变的 strings 将在反射或者作为参数将导致安全问题。
- 不变对象是自然线程安全
- 因为不可变对象是不可以改变的,它能够被多个线程自由的共享。这消除了同步。
#### 容器
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
##### Collection
- Set
- TreeSet
- 基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 $O(1)$,TreeSet 则为 $O(logN)$。
- HashSet
- 基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- LinkedHashSet
- 具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
- CopyOnWriteArraySet
- List
- ArrayList
- 用数组实现的存储
- 线程不安全。可以用 Collections.synchronizedList 把一个普通 ArrayList 包装成一个线程安全版本的数组容器。
- 特点
- 查询效率高,增删效率低
- 扩容机制
- 插入数据时,会调用 `ensureCapacityInternal` 方法。
- 扩容后的大小为
- 原来的 1.5 倍
- 版本区别
- JDK 1.7 以前会调用 `this(10)` 才是真正的容量为 10
- 1.7 及本身以后是默认走了空数组,只有第一次 add 的时候容量会变成 10
- LinkedList
- 基于双向链表
- 使用了尾插法的方式,内部维护了链表的⻓度,以及头节点和尾节点,所以获取⻓度不需要遍历
- 特点
- 适合一些插入、删除频繁的情况。
- Vector
- 线程安全。就是把所有的方法统统加上 synchronized 了。
- PriorityQueue
- 基于堆结构实现,可以用它来实现优先队列。
- CopyOnWriteArrayList
- CopyOnWriteArrayList,运用了一种“写时复制”的思想。通俗的理解就是当我们需要修改(增/删/改)列表中的元素时,不直接进行修改,而是先将列表 Copy,然后在新的副本上进行修改,修改完成之后,再将引用从原列表指向新列表。
- 适用于“读多写少”
- 核心方法
- 查询【get 方法】
- get 方法并没有加锁,直接返回了内部数组对应索引位置的值
- 添加【add 方法】
- add 方法首先会进行加锁,保证只有一个线程能进行修改;然后会创建一个新数组(大小为 n+1),并将原数组的值复制到新数组,新元素插入到新数组的最后;最后,将字段 array 指向新数组。
- 删除【remove 方法】
- 删除方法和插入一样,都需要先加锁(所有涉及修改元素的方法都需要先加锁,写-写不能并发),然后构建新数组,复制旧数组元素至新数组,最后将 array 指向新数组。
- 迭代
- CopyOnWriteArrayList 对元素进行迭代时,仅仅返回一个当前内部数组的快照,也就是说,如果此时有其它线程正在修改元素,并不会在迭代中反映出来,因为修改都是在新数组中进行的。
- 存在的一些问题
- 内存的使用
- 由于 CopyOnWriteArrayList 使用了“写时复制”,所以在进行写操作的时候,内存里会同时存在两个 array 数组,如果数组内存占用的太大,那么可能会造成频繁 GC,所以 CopyOnWriteArrayList 并不适合大数据量的场景。
- 数据一致性
- CopyOnWriteArrayList 只能保证数据的最终一致性,不能保证数据的实时一致性——读操作读到的数据只是一份快照。所以如果希望写入的数据可以立刻被读到,那 CopyOnWriteArrayList 并不适合。
- 阻塞队列
- 都是线程安全的
- ArrayBlockingQueue
- 一个由数组结构组成的有界阻塞队列
- 内部用 ReentrantLock 实现线程安全
- 方法
- 入队方法
- `add(E e)`
- 调用 offer 方法,数组满了就抛出异常
- `offer(E e)`
- 如果数组满了就返回 false
- `put(E e)`
- 如果数组满了,用 Lock 的 Condition 实现等待,然后出队列的时候进行唤醒,无返回值
- `offer(E e, long timeout, TimeUnit unit)`
- 如果数组满了,用 Lock 的 Condition 实现等待(有最大等待时常)
- 出队方法
- `remove()`
- 调用 poll 方法,没有返回元素则抛出异常
- `poll()`
- 没有返回元素则返回 null
- `take()`
- 没有返回元素,则用 Lock 的 Condition 实现等待,然后有元素的时候唤醒返回
- `poll(long timeout, TimeUnit unit)`
- 没有返回元素,用 Lock 的 Condition 实现等待(有最大等待时常)
- LinkedBlockingQueue
- 一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue
- 一个支持优先级排序的无界阻塞队列。
- DealyQueue
- 一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue
- 一个不存储元素的阻塞队列。
- LinkedTransferQueue
- 一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque
- 一个由链表结构组成的双向阻塞队列。
##### Map
- 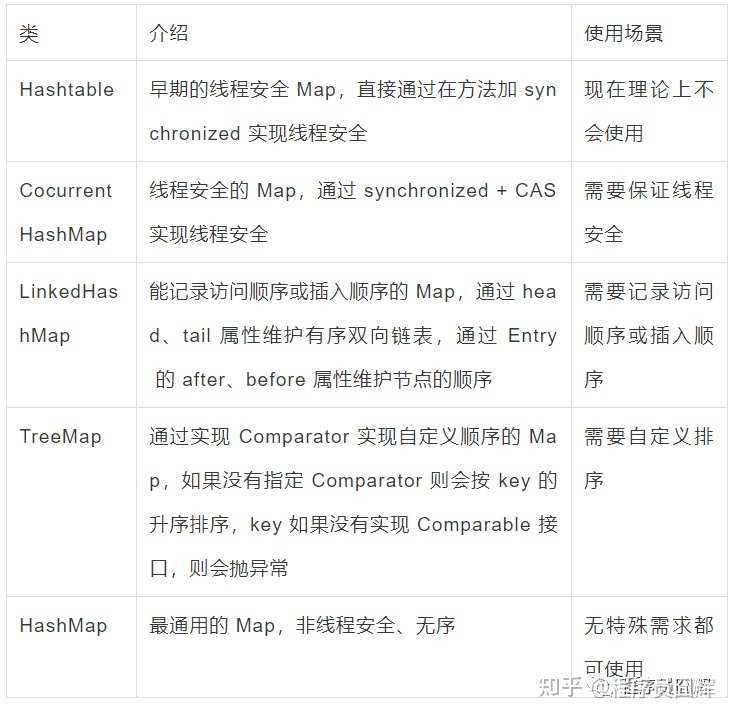
- HashMap
- 线程不安全。可以使用 `Collections.synchronizedMap(Map)` 创建线程安全的 map 集合。
- **Collections.synchronizedMap 是怎么实现线程安全的?**
- 在 SynchronizedMap 内部维护了一个普通对象 Map,还有排斥锁 mutex。
- 在调用这个方法的时候就需要传入一个 Map,有两个构造器,如果传入了 mutex 参数,则将对象排斥锁赋值为传入的对象。如果没有,则将对象排斥锁赋值为 this。
- 创建出 SynchronizedMap 之后,再操作 map 的时候,就会对方法上锁。
- 由数组和链表组合构成。
- 初始容量 16。
- 负载因子默认 0.75。
- 根据泊松分布,在负载因子默认为 0.75 的时候,单个 hash 槽内元素个数为 8 的概率小于百万分之一,所以将 7 作为一个分水岭,**等于 7 的时候不转换,大于等于 8 的时候才进行转换为红黑树,小于等于 6 的时候就化为链表**。
- HashMap 的键值则都可以为 null。
- hash 方法
- 扰动函数
- 混合原始哈希码的高位和低位,以此来加大低位的随机性。
- Java 7
- ```
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
- 操作
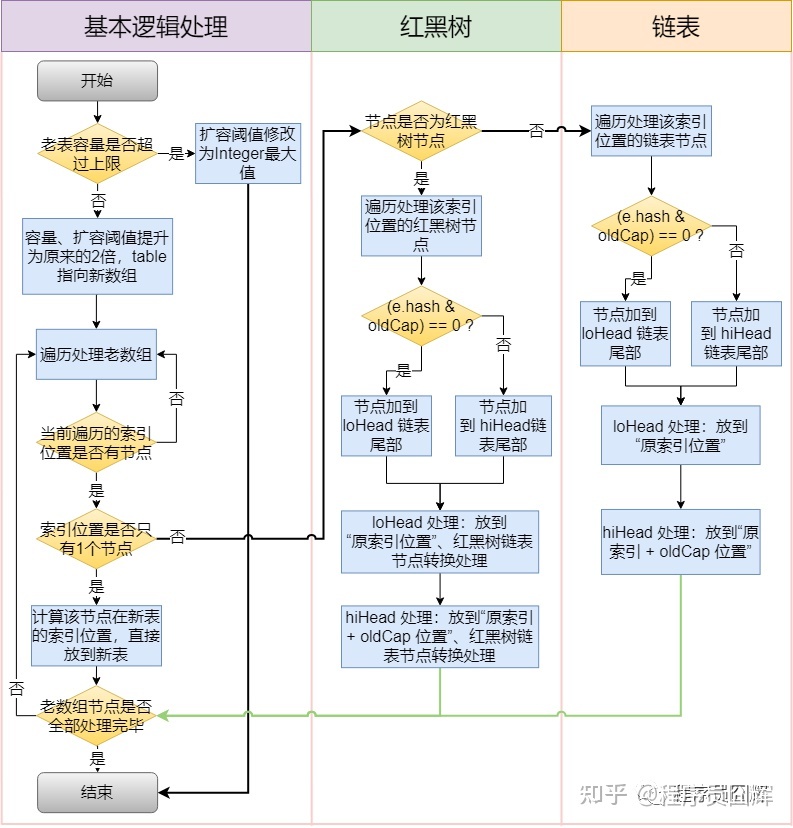
- 扩容机制
- 当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍。
- 扩容流程
- 迭代器
- HashMap 中的 Iterator 迭代器是 fail-fast 的。
- 快速失败(fail—fast)是 Java 集合中的一种机制,在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出 Concurrent Modification Exception。
- 原理:
- 迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。
- 集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。
- 每当迭代器使用
hashNext()/next()遍历下一个元素之前,都会检测 modCount 变量是否为 expectedmodCount 值,是的话就返回遍历;否则抛出异常,终止遍历。 - 这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改 modCount 值刚好又设置为了 expectedmodCount 值,则异常不会抛出。
- java.util 包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)算是一种安全机制吧。
- 原理:
- 快速失败(fail—fast)是 Java 集合中的一种机制,在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出 Concurrent Modification Exception。
- HashMap 中的 Iterator 迭代器是 fail-fast 的。
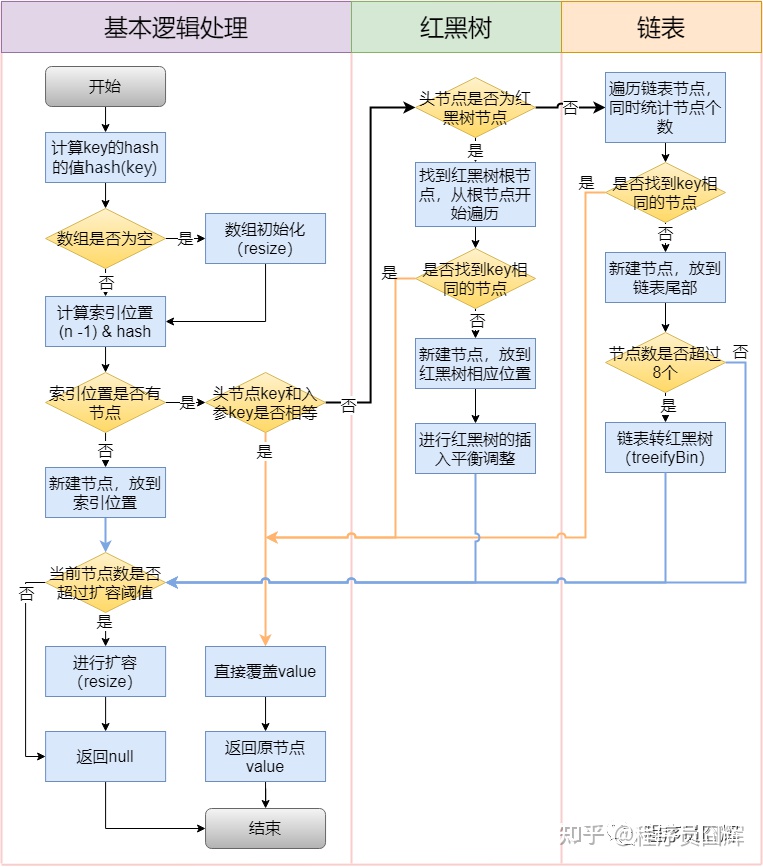
- 插入数据时:
- Java8 之前是头插法。采用 数组+链表 的数据结构。
- Java8 之后,都是所用尾部插入了。采用 Node 数组+链表+红黑树 的数据结构。
- 插入流程
- 相关问题
- 为什么要改插入方式?
- 多线程 resize 的时候,可能会产生环形链表,则插入会死循环
- 使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了
- 为什么要改插入方式?
- 扩容机制
- 相关问题
- 为什么是非线程安全的?
- 多线程 put(不考虑 resize)
- 如果 hash 冲突,后一个线程覆盖前一个线程的 key-value,如在一系列线程中出现 hash 冲突的键值对个数为 N,则最多可能丢失 N-1 个键值对,即只有一个线程的键值对最终被加入到 table 内的链表或红黑树中
- 多线程 resize
- 可能会产生环形链表,则插入会死循环
- 多线程 remove
- 可能没删掉
- 多线程 put(不考虑 resize)
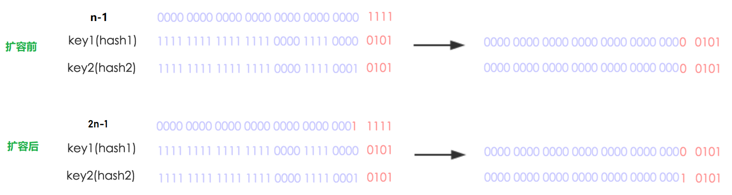
- 为什么容量要是 2 的幂?
- 为了位运算的方便,位与运算比算数计算的效率高了很多
- 当数组长度为 $2^n$ 时,$2^n − 1$ 的所有位都是 1,如 8-1=7 即 111,那么进行低位 & 运算时,值总与原来的 hash 值相同,降低了碰撞的概率
当 table 数组的大小为 2 的幂次时,通过
key.hash & table.length-1这种方式计算出的索引 i,当 table 扩容后(2 倍),新的索引要么在原来的位置 i,要么是 i+n。
- 为什么重写 equals 方法的时候需要重写 hashCode 方法?
- 这两个方法都是用来比较两个对象是否相等的
- 未重写 equals 方法,我们是继承了 object 的 equals 方法,那里的 equals 是比较两个对象的内存地址
- get 的时候,他就是根据 key 去 hash 然后计算出 index。所以如果我们对 equals 方法进行了重写,建议一定要对 hashCode 方法重写,以保证相同的对象返回相同的 hash 值,不同的对象返回不同的 hash 值。
- JDK1.8 发生了哪些变化?
- 由数组+链表改为数组+链表+红黑树,当链表的长度超过8时,链表变为红黑树。
- 为什么要这么改?
- 我们知道链表的查找效率为 $O(n)$,而红黑树的查找效率为 $O(logn)$,查找效率变高了。
- 为什么不直接用红黑树?
- 因为红黑树的查找效率虽然变高了,但是插入效率变低了,如果从一开始就用红黑树并不合适。从概率学的角度选了一个合适的临界值为 8
- 为什么要这么改?
- 优化了 hash 算法(变成位运算)
- 计算元素在新数组中位置的算法发生了变化,新算法通过新增位判断
oldTable[i]应该放在newTable[i]还是newTable[i+oldTable.length] - 头插法改为尾插法,扩容时链表没有发生倒置(避免形成死循环)
- 由数组+链表改为数组+链表+红黑树,当链表的长度超过8时,链表变为红黑树。
- 为什么不使用 AVL 树而使用红黑树?
- 红黑树和 AVL 树都是最常用的平衡二叉搜索树,它们的查找、删除、修改都是 $O(lgn)$
- AVL 树和红黑树有几点比较和区别:
- AVL 树是更加严格的平衡,因此可以提供更快的查找速度,一般读取查找密集型任务,适用 AVL 树。
- 红黑树更适合于插入修改密集型任务。
- 通常,AVL 树的旋转比红黑树的旋转更加难以平衡和调试。
- 总结:
- AVL 以及红黑树是高度平衡的树数据结构。它们非常相似,真正的区别在于在任何添加/删除操作时完成的旋转操作次数。
- 两种实现都缩放为a $O(lgN)$,其中 N 是叶子的数量,但实际上 AVL 树在查找密集型任务上更快:利用更好的平衡,树遍历平均更短。另一方面,插入和删除方面,AVL 树速度较慢:需要更高的旋转次数才能在修改时正确地重新平衡数据结构。
- 在 AVL 树中,从根到任何叶子的最短路径和最长路径之间的差异最多为 1。在红黑树中,差异可以是 2 倍。
- 两个都给 $O(logn)$ 查找,但平衡 AVL 树可能需要 $O(logn)$ 旋转,而红黑树将需要最多两次旋转使其达到平衡(尽管可能需要检查 $O(logn)$ 节点以确定旋转的位置)。旋转本身是 $O(1)$ 操作,因为你只是移动指针。
- 为什么是非线程安全的?
- HashTable
- 线程安全。直接在方法上锁,并发度很低,最多同时允许一个线程访问。
- 读写枷锁
- 为什么效率低?
- 对数据操作的时候都会上锁,所以效率比较低下。
- 扩容机制
- 当现有容量大于总容量 * 负载因子时,Hashtable 扩容规则为当前容量翻倍 + 1。
- Hashtable 是不允许键或值为 null 的。
- 为什么 Hashtable 是不允许 KEY 和 VALUE 为 null, 而 HashMap 则可以呢?
- 因为 Hashtable 在我们 put 空值的时候会直接抛空指针异常,但是 HashMap 却做了特殊处理(key 为 null 直接放在
table[0]处)。
- 因为 Hashtable 在我们 put 空值的时候会直接抛空指针异常,但是 HashMap 却做了特殊处理(key 为 null 直接放在
- 为什么 Hashtable 是不允许 KEY 和 VALUE 为 null, 而 HashMap 则可以呢?
- 线程安全。直接在方法上锁,并发度很低,最多同时允许一个线程访问。
- ConcurrentHashMap
- 线程安全
- 读不加锁,写不一定加锁
- 基本结构
- 结点定义
- Node 结点
- 是其它类型节点的父类
- TreeNode 结点
- TreeNode 就是红黑树的结点,TreeNode 不会直接链接到
table[i](桶)上面,而是由 TreeBin 链接,TreeBin 会指向红黑树的根结点。
- TreeNode 就是红黑树的结点,TreeNode 不会直接链接到
- TreeBin 结点
- TreeBin 相当于 TreeNode 的代理结点。TreeBin 会直接链接到
table[i](桶)上面,该结点提供了一系列红黑树相关的操作,以及加锁、解锁操作。
- TreeBin 相当于 TreeNode 的代理结点。TreeBin 会直接链接到
- ForwardingNode 结点
- ForwardingNode 结点仅仅在扩容时才会使用。
- 当最后一个线程完成迁移任务后,会遍历所有桶,看看是否都是 ForwardingNode,如果是,那么说明整个扩容/数据迁移的过程就完成了。
- ReservationNode 结点
- 保留结点
- Node 结点
- 结点定义
- 操作
- 插入数据时:
- Java8 之前,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel(Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
- Java8 之后,Node 数组+链表+红黑树,采用了 CAS + synchronized 来保证并发安全性。操作 hash值 相同的链表,头结点用 synchronized 上锁保证线程安全。
- 步骤:
- 根据 key 计算出 hashcode。
- 判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 当
table[i]的结点类型为 Node(链表结点)时,就会将新结点以“尾插法”的形式插入链表的尾部。 - 当
table[i]的结点类型为 TreeBin(红黑树代理结点)时,就会将新结点通过红黑树的插入方式插入。
- 当
- 如果当前位置的 hashcode == MOVED == -1 ,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
- 步骤:
- 查询数据
- 当槽
table[i]被普通 Node 结点占用,说明是链表链接的形式,直接从链表头开始查找 - 当槽
table[i]被 TreeBin 结点占用时,说明链接的是一棵红黑树。由于红黑树的插入、删除会涉及整个结构的调整,所以通常存在读写并发操作的时候,是需要加锁的
- 当槽
- 扩容
- Hash 表的扩容,一般都包含两个步骤:
- table 数组的扩容
- table 数组的扩容,一般就是新建一个 2 倍大小的槽数组,这个过程通过由一个单线程完成,且不允许出现并发。
- 数据迁移
- 把旧 table 中的各个槽中的结点重新分配到新 table 中。
- table 数组的扩容
- transfer 方法,这个方法可以被多个线程同时调用,也是“数据迁移”的核心操作方法
- transfer 方法主要包含 4 个分支,即对 4 种不同情况进行处理
- 桶
table[i]为空- 当旧 table 的桶
table[i] == null,说明原来这个桶就没有数据,那就直接尝试放置一个 ForwardingNode,表示这个桶已经处理完成。
- 当旧 table 的桶
- 桶
table[i]已迁移完成 - 桶
table[i]未迁移完成- 如果旧桶的数据未迁移完成,就要进行迁移,这里根据桶中结点的类型分为:链表迁移、红黑树迁移
- 链表迁移
- 链表迁移的过程如下,首先会遍历一遍原链表,找到最后一个相邻的 runBit 不同的结点。
- runbit 是根据 key.hash 和旧 table 长度 n 进行与运算得到的值,由于 table 的长度为 2 的幂次,所以 runbit 只可能为 0 或最高位为 1
- 然后,会进行第二次链表遍历,按照第一次遍历找到的结点为界,将原链表分成 2 个子链表,再链接到新 table 的槽中。可以看到,新 table 的索引要么是 i,要么是 i+n
- 链表迁移的过程如下,首先会遍历一遍原链表,找到最后一个相邻的 runBit 不同的结点。
- 红黑树迁移
- 红黑树的迁移按照链表遍历的方式进行,当链表结点超过/小于阈值时,涉及红黑树<->链表的相互转换
- 链表迁移
- 如果旧桶的数据未迁移完成,就要进行迁移,这里根据桶中结点的类型分为:链表迁移、红黑树迁移
- 当前是最后一个迁移任务或出现扩容冲突
- 桶
- Hash 表的扩容,一般都包含两个步骤:
- 插入数据时:
- 安全失败:
- java.util.concurrent 包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
- 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
- 迭代器:
- 是弱一致性迭代器。ConcurrentHashMap 的迭代器创建后,就会按照哈希表结构遍历每个元素,但在遍历过程中,内部元素可能会发生变化,如果变化发生在已遍历过的部分,迭代器就不会反映出来,而如果变化发生在未遍历过的部分,迭代器就会发现并反映出来,这就是弱一致性。
- ConcurrentHashMap 中每个结点指向下一个结点的 next 是不可变的(final)。concurrentHashMap 的删除操作是通过将被删除的元素重新复制一遍实现的。也就是说,如果 A 删掉了第 7 个元素,此时 B 已经遍历到了第 3 个元素,那么 B 还是可以遍历到被删除的第 7 个元素(Java1.8 之前)。
- 线程安全
- TreeMap
- TreeMap 是会自动进行排序的,也就是一个有序 Map(使用了红黑树来实现)
- LinkedHashMap
- 有序的 HashMap,和 TreeMap 是不一样的概念,是用了 HashMap+双向链 的方式来构造的
- 线程不安全
- 顺序
- 插入顺序(默认实现)
- 插入的是什么顺序,读出来的就是什么顺序
- 访问顺序
- 每次 get 的时候都会把链表的节点移除掉,放到链表的最后面。这样子就是一个 LRU 的一种实现方式。
- 插入顺序(默认实现)
I/O
- 基本概念
- 同步、异步
- 同步:同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
- 异步:异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
- 同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
- 阻塞、非阻塞
- 阻塞:阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
- 非阻塞:非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
- 相关问题
- 同步阻塞、同步非阻塞和异步非阻塞又代表什么意思呢?
- 举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在哪里傻等着水开(同步阻塞)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(同步非阻塞)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(异步非阻塞)。
- 同步阻塞、同步非阻塞和异步非阻塞又代表什么意思呢?
- 同步、异步
- I/O 方式
- BIO(Blocking I/O)
- 传统 BIO
- 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。
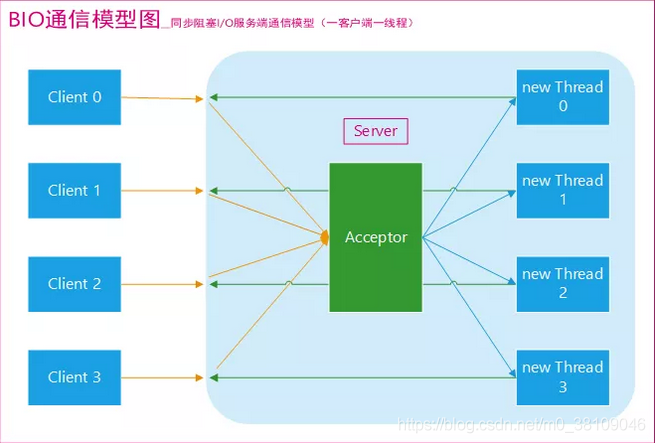
- 采用 BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在
while(true)循环中服务端会调用accept()方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成,不过可以通过多线程来支持多个客户端的连接。可以通过线程池机制改善,线程池还可以让线程的创建和回收成本相对较低。
- 伪异步 IO
- 为了解决同步阻塞 I/O 面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化。
- 后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数 M : 线程池最大线程数 N 的比例关系,其中 M 可以远远大于 N。通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。
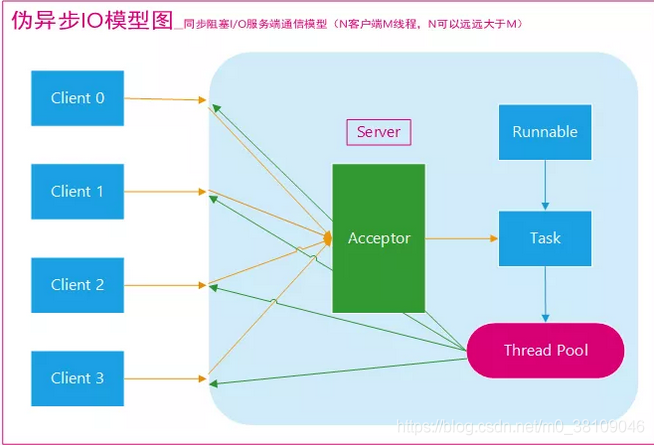
- 总结
- 在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- 传统 BIO
- NIO
- NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel、Selector、Buffer 等抽象。它支持面向缓冲的,基于通道的 I/O 操作方法。
- JDK 的 NIO 底层由 epoll 实现。
- NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
- 核心组件
- Buffer
- 在 NIO 厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
- 最常用的缓冲区是 ByteBuffer,一个 ByteBuffer 提供了一组功能用于操作 byte 数组。除了 ByteBuffer,还有其他的一些缓冲区,事实上,每一种 Java 基本类型(除了 Boolean 类型)都对应有一种缓冲区。
- Channel
- NIO 通过 Channel(通道)进行读写。
- 通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和 Buffer 交互。因为 Buffer,通道可以异步地读写。
- Selectors
- 选择器用于使用单个线程处理多个通道。
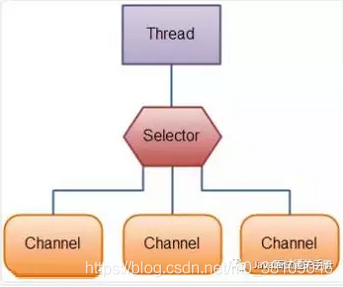
- Buffer
- NIO 读数据和写数据方式
- 从通道进行数据读取:创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入:创建一个缓冲区,填充数据,并要求通道写入数据。
- AIO(Asynchronous I/O)
- AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
- AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO 操作本身是同步的。
- BIO(Blocking I/O)
多线程
- 并发编程 3 大重要特征
- 原子性
- 一个操作或者多个操作,要么全部执行成功,要么全部执行失败。满足原子性的操作,中途不可被中断。
- 可见性
- 多个线程共同访问共享变量时,某个线程修改了此变量,其他线程能立即看到修改后的值。
- 有序性
- 程序执行的顺序按照代码的先后顺序执行。(由于 JMM 模型中允许编译器和处理器为了效率,进行指令重排序的优化。指令重排序在单线程内表现为串行语义,在多线程中会表现为无序。那么多线程并发编程中,就要考虑如何在多线程环境下可以允许部分指令重排,又要保证有序性)
- 原子性
- 锁
- 概念
- 公平锁和非公平锁
- 公平锁
- 多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死在队列中
- 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
- 非公平锁
- 多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
- 优点:可以减少 CPU 唤醒线程的开销,整体的吞吐效率会高点,CPU 也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
- 公平锁
- 公平锁和非公平锁
- synchronized
- synchronized 是一种独占式的重量级锁,在运行到同步方法或者同步代码块的时候,让程序的运行级别由用户态切换到内核态,把所有的线程挂起,通过操作系统的指令,去调度线程。这样会频繁出现程序运行状态的切换,线程的挂起和唤醒,会消耗系统资源,为了提高效率,引入了偏向锁、轻量级锁、尽量让多线程访问公共资源的时候,不进行程序运行状态的切换。
- 非公平锁
- 特性
- 可重入性
- synchronized 锁对象的时候有个计数器,他会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会 -1,直到计数器清零,就释放锁了。
- 那可重入有什么好处呢?
- 可以避免一些死锁的情况,也可以让我们更好封装我们的代码。
- 那可重入有什么好处呢?
- synchronized 锁对象的时候有个计数器,他会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会 -1,直到计数器清零,就释放锁了。
- 不可中断性
- 不可中断就是指,一个线程获取锁之后,另外一个线程处于阻塞或者等待状态,前一个不释放,后一个也一直会阻塞或者等待,不可以被中断。
- 可重入性
- 对象监视器(Monitor)
- 在 HotSpot JVM 实现中,锁有个专门的名字:对象监视器。
- 任何一个对象都有一个 Monitor 与之关联,当且一个 Monitor 被持有后,它将处于锁定状态。
- 监视器锁(Monitor)本质是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。每个对象都对应于一个可称为“互斥锁”的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
- synchronized 在 JVM 里的实现都是基于进入和退出 Monitor 对象来实现方法同步和代码块同步,虽然具体实现细节不一样,但是都可以通过成对的 MonitorEnter 和 MonitorExit 指令来实现。
- MonitorEnter 指令:插入在同步代码块的开始位置,当代码执行到该指令时,将会尝试获取该对象 Monitor 的所有权,即尝试获得该对象的锁;
- MonitorExit 指令:插入在方法结束处和异常处,JVM 保证每个 MonitorEnter 必须有对应的 MonitorExit;
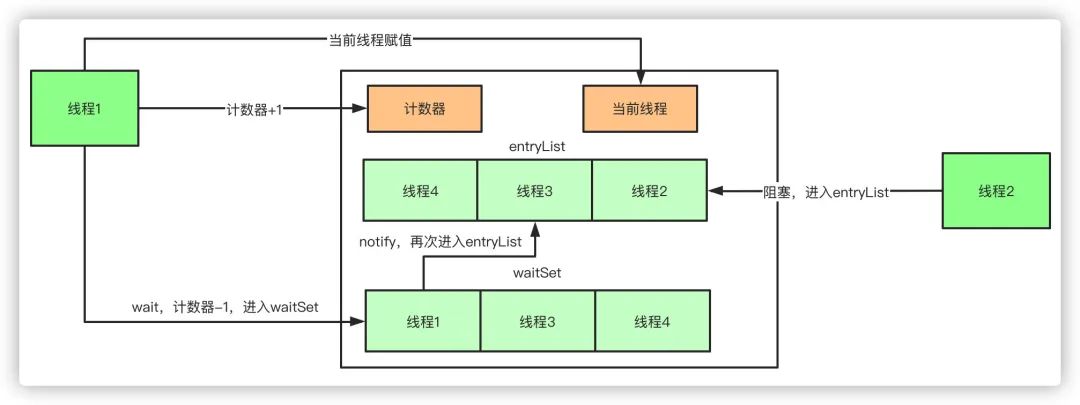
- Monitor 对象存在于每个 Java 对象的对象头 Mark Word 中(存储的指针的指向)
- 当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程:
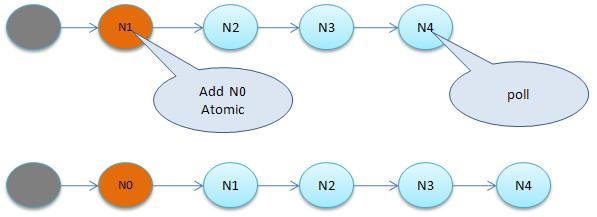
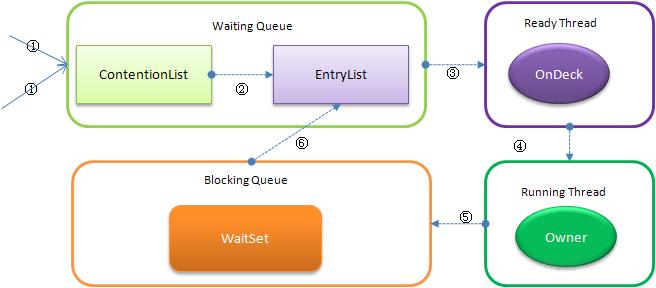
- Contention List:所有请求锁的线程将被首先放置到该竞争队列
- ContentionList 并不是一个真正的 Queue,而只是一个虚拟队列,原因在于 ContentionList 是由 Node 及其 next 指针逻辑构成,并不存在一个 Queue 的数据结构。
- ContentionList 是一个
后进先出(LIFO)【注:按上下文来看应该是先进先出(FIFO)】的队列,每次新加入 Node 时都会在队头进行,通过 CAS 改变第一个节点的的指针为新增节点,同时设置新增节点的 next 指向后续节点,而取得操作则发生在队尾。显然,该结构其实是个 Lock-Free 的队列。 - 因为只有 Owner 线程才能从队尾取元素,也即线程出列操作无争用,当然也就避免了 CAS 的 ABA 问题。
- Entry List:Contention List 中那些有资格成为候选人的线程被移到 Entry List
- EntryList 与 ContentionList 逻辑上同属等待队列,ContentionList 会被线程并发访问,为了降低对 ContentionList 队尾的争用,而建立 EntryList。
- Owner 线程在 unlock 时会从 ContentionList 中迁移线程到 EntryList,并会指定 EntryList 中的某个线程(一般为 Head)为 Ready(OnDeck)线程。Owner 线程并不是把锁传递给 OnDeck 线程,只是把竞争锁的权利交给 OnDeck,OnDeck 线程需要重新竞争锁。这样做虽然牺牲了一定的公平性,但极大的提高了整体吞吐量,在 Hotspot 中把 OnDeck 的选择行为称之为“竞争切换”。
- OnDeck 线程获得锁后即变为 owner 线程,无法获得锁则会依然留在 EntryList 中,考虑到公平性,在 EntryList 中的位置不发生变化(依然在队头)。如果 Owner 线程被 wait 方法阻塞,则转移到 WaitSet 队列;如果在某个时刻被
notify/notifyAll唤醒,则再次转移到 EntryList。
- Wait Set:那些调用 wait 方法被阻塞的线程被放置到 Wait Set
- OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为 OnDeck
- Owner:获得锁的线程称为 Owner
- !Owner:释放锁的线程
- Contention List:所有请求锁的线程将被首先放置到该竞争队列
- 状态转换
- 原理
- 对象头,他会关联到一个 monitor 对象。
- 当我们进入一个人方法的时候,执行 monitorenter,就会获取当前对象的一个所有权,这个时候 monitor 进入数为 1,当前的这个线程就是这个 monitor 的 owner。
- 如果你已经是这个 monitor 的 owner 了,你再次进入,就会把进入数 +1。
- 如果线程调用 wait 方法,将释放锁,当前线程置为 null,计数器 -1,同时进入 waitSet 等待被唤醒,调用 notify 或者 notifyAll 之后又会进入 entryList 竞争锁。
- 同理,当他执行完 monitorexit,对应的进入数就 -1,直到为 0,才可以被其他线程持有。
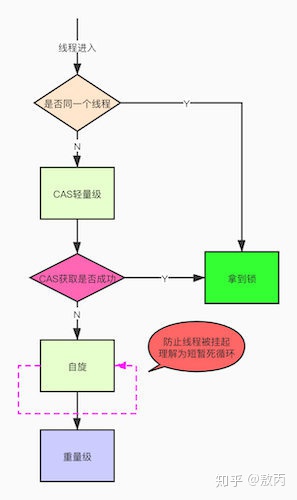
- 自旋锁
- 出现自旋锁的原因
- 那些处于 ContetionList、EntryList、WaitSet 中的线程均处于阻塞状态,阻塞操作由操作系统完成(在 Linxu 下通过 pthread_mutex_lock 函数)。线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能。
- 原理
- 当发生争用时,若 Owner 线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋),在 Owner 线程释放锁后,争用线程可能会立即得到锁,从而避免了系统阻塞。但 Owner 运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。
- 相关问题
- 线程自旋时做些啥?
- 其实啥都不做,可以执行几次 for 循环,可以执行几条空的汇编指令,目的是占着 CPU 不放,等待获取锁的机会。所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择,如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。
- synchronized 实现何时使用了自旋锁?
- 在线程进入 ContentionList 时,也即第一步操作前。线程在进入等待队列时首先进行自旋尝试获得锁,如果不成功再进入等待队列。这对那些已经在等待队列中的线程来说,稍微显得不公平。还有一个不公平的地方是自旋线程可能会抢占了 Ready 线程的锁。自旋锁由每个监视对象维护,每个监视对象一个。
- 线程自旋时做些啥?
- 适应性自旋锁
- JDK 1.6 引入了更加聪明的自旋锁,即自适应自旋锁。所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
- 如何进行适应性自旋呢?
- 线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
- 出现自旋锁的原因
- 锁消除
- 锁消除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不会逃逸出去从而被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行。
- 例子
- 变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是程序员自己所该是很清楚的,怎么会在明知道不存在数据争用的情况下要求同步呢?答案是有许多同步措施并不是程序员自己加入的,同步的代码在 Java 程序中的普遍程度也许超过了大部分读者的想象。我们来看看下面代码中的例子,这段非常简单的代码仅仅是输出 3 个字符串相加的结果,无论是源码字面上还是程序语义上都没有同步。

- 我们也知道,由于 String 是一个不可变的类,对字符串的连接操作总是通过生成新的 String 对象来进行的,因此 Javac 编译器会对 String 连接做自动优化。在 JDK 1.5 之前,会转化为 StringBuffer 对象的连续
append()操作,在 JDK 1.5及以后的版本中,会转化为 StringBuilder 对象的连续append()操作,上述代码可能会变成下面的样子。 
- 每个
StringBuffer.append()方法中都有一个同步块,锁就是 sb 对象。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在concatString()方法内部。也就是说,sb 的所有引用永远不会 “逃逸” 到concatString()方法之外,其他线程无法访问到它,因此,虽然这里有锁,但是可以被安全地消除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了。
- 锁粗化
- 原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小,只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待锁的线程也能尽快拿到锁。
- 大部分情况下,上面的原则都是正确的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作是出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。
- 例子
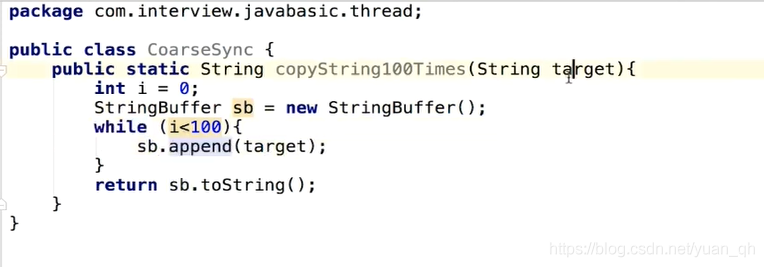
- 上述代码中连续的
append()方法就属于这类情况。如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部,以上述代码为例,就是扩展到append()操作外部,也就是把 while 循环加锁,这样只需要加锁一次就可以了。
- 锁升级
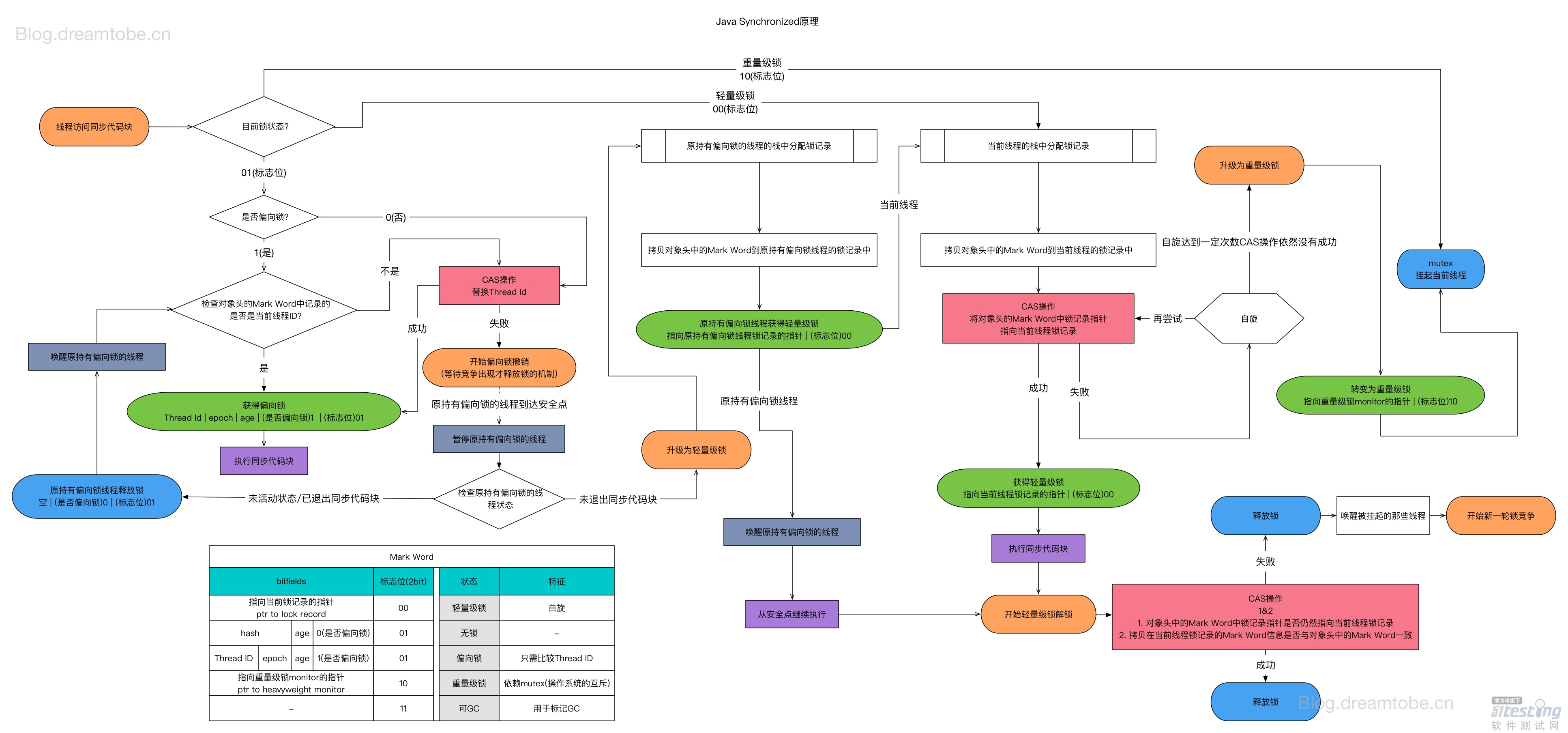
- 从 JDK1.6 版本之后,synchronized 本身也在不断优化锁的机制,有些情况下他并不会是一个很重量级的锁了。优化机制包括自适应锁、自旋锁、锁消除、锁粗化、轻量级锁和偏向锁。
- 无锁——>偏向锁——>轻量级锁——>重量级锁,膨胀方向不可逆。
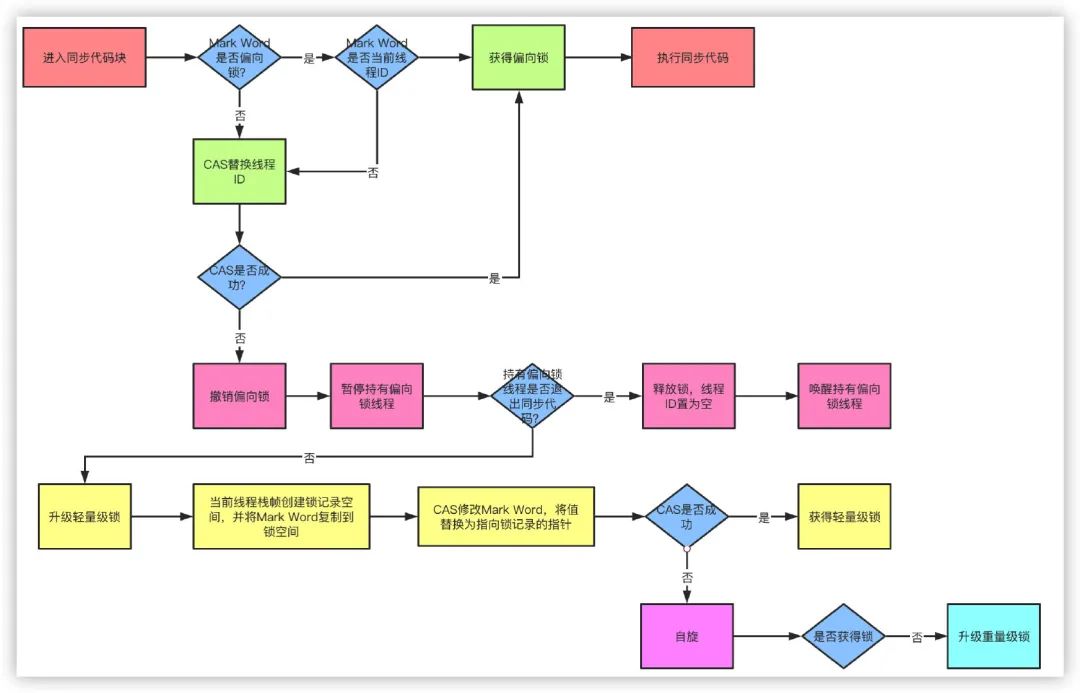
- 偏向锁
- 对象头是由 Mark Word 和 Klass pointer 组成,锁争夺也就是对象头指向的 Monitor 对象的争夺,一旦有线程持有了这个对象,标志位修改为 1,就进入偏向模式,同时会把这个线程的 ID 记录在对象的 Mark Word 中。
- 这个过程是采用了 CAS 乐观锁操作的,每次同一线程进入,虚拟机就不进行任何同步的操作了,对标志位 +1 就好了,不同线程过来,CAS 会失败,也就意味着获取锁失败。
- 偏向锁在 1.6 之后是默认开启的,1.5 中是关闭的,需要手动开启参数是
xx:-UseBiasedLocking=false。 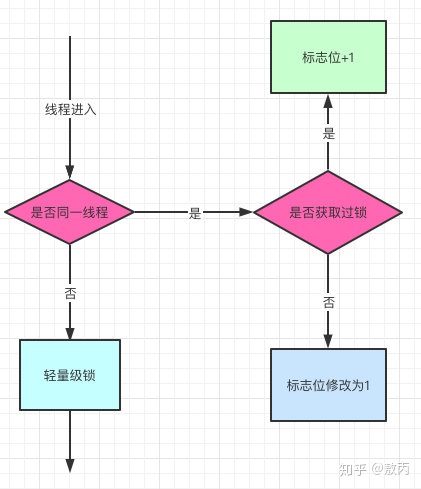
- 轻量级锁
- 如果这个对象是无锁的,JVM 就会在当前线程的栈帧中建立一个叫锁记录(Lock Record)的空间,用来存储锁对象的 Mark Word 拷贝,然后把 Lock Record 中的 owner 指向当前对象。
- JVM 接下来会利用 CAS 尝试把对象原本的 Mark Word 更新为 Lock Record 的指针,成功就说明加锁成功,改变锁标志位,执行相关同步操作。
- 如果失败了,就会判断当前对象的 Mark Word 是否指向了当前线程的栈帧,是则表示当前的线程已经持有了这个对象的锁,否则说明被其他线程持有了,继续锁升级,修改锁的状态,之后等待的线程也阻塞。
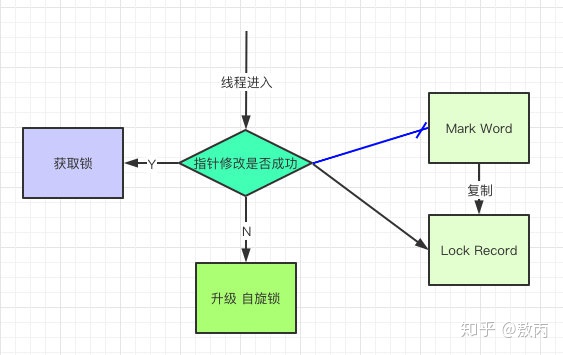
- 轻量级锁认为竞争存在,但是竞争的程度很轻,一般两个线程对于同一个锁的操作都会错开,或者说稍微等待一下(自旋),另一个线程就会释放锁。 但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁膨胀为重量级锁,重量级锁使除了拥有锁的线程以外的线程都阻塞,防止 CPU 空转。
- 重量级锁
- 就是让争抢锁的线程从用户态转换成内核态。让 CPU 借助操作系统进行线程协调。
- 偏向锁
- 流程
- 检查 MarkWord 里面是不是放的自己的 ThreadId,如果是,表示当前线程是处于“偏向锁”。跳过轻量级锁直接执行同步体。
- 如果 MarkWord 不是自己的 ThreadId,锁升级,这时候,用 CAS 来执行切换,新的线程根据 MarkWord 里面现有的 ThreadId,通知之前线程暂停,之前线程将 Markword 的内容置为空。
- 两个线程都把对象的 HashCode 复制到自己新建的用于存储锁的记录空间,接着开始通过 CAS 操作,把共享对象的 MarKWord 的内容修改为自己新建的记录空间的地址的方式竞争 MarkWord.
- 第三步中成功执行 CAS 的获得资源,失败的则进入自旋.
- 自旋的线程在自旋过程中,成功获得资源(即之前获的资源的线程执行完成并释放了共享资源),则整个状态依然处于轻量级锁的状态,如果自旋失败
- 进入重量级锁的状态,这个时候,自旋的线程进行阻塞,等待之前线程执行完成并唤醒自己.
- 同步代码块和同步方法
- 同步方法就是在方法前加关键字 synchronized;同步代码块则是在方法内部使用 synchronized
- 加锁对象相同的话,同步方法锁的范围大于等于同步方法块。一般加锁范围越大,性能越差
- 同步方法如果是 static 方法,等同于同步方法块加锁在该 Class 对象上
- 相关命令
- wait
- notify
- ReentrantLock
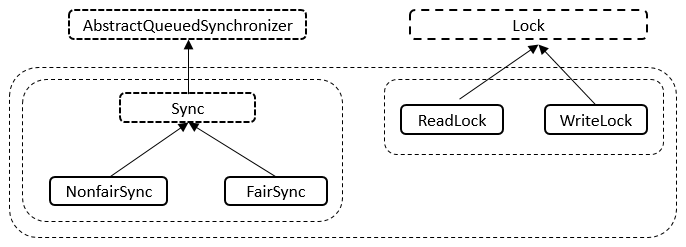
- 基于 AQS 而形成了一个“可重入锁”
- AQS:AbstractQueuedSynchronizer 的缩写
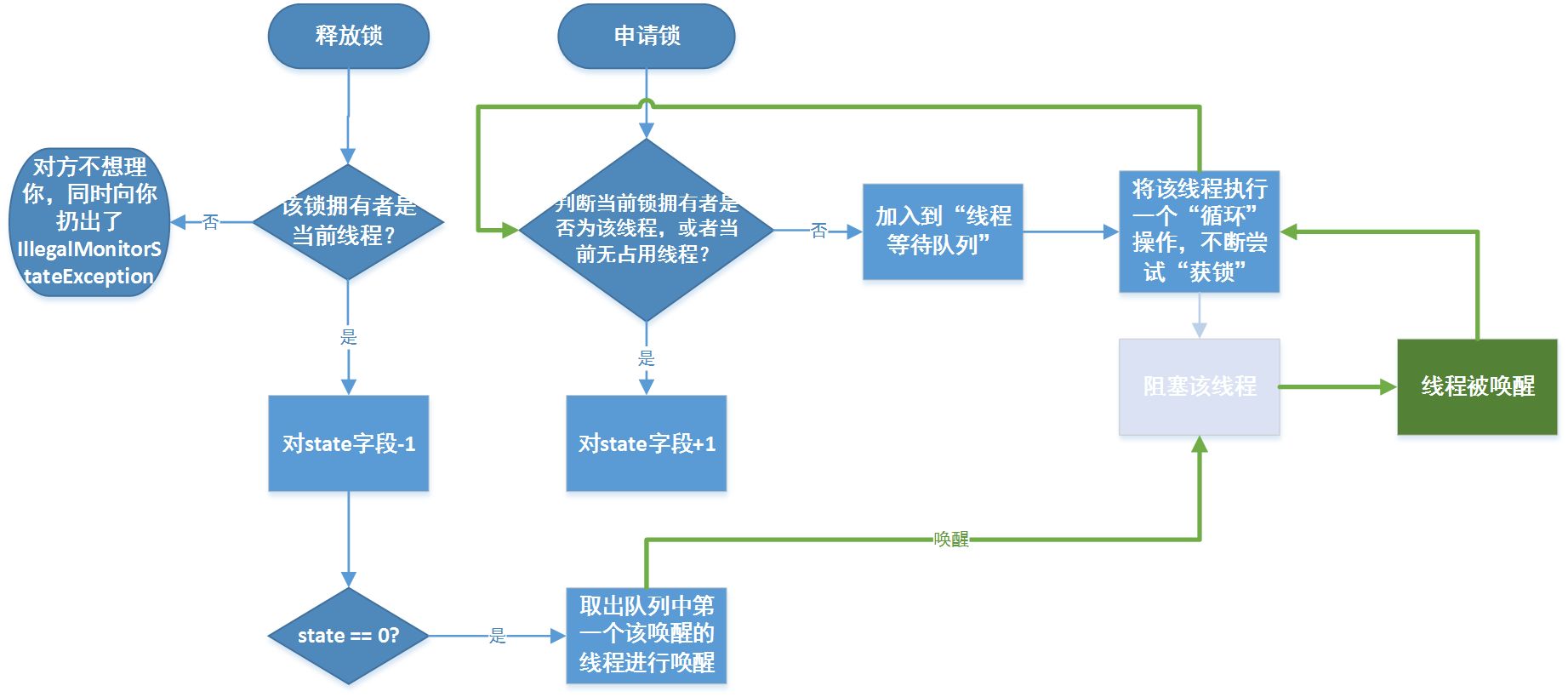
- AQS 是 JUC(java.util.concurrent)的核心,而 CLH 锁又是 AQS 的基础
- CLH 锁
- 原理
- 首先有一个尾节点指针,通过这个尾结点指针来构建等待线程的逻辑队列,因此能确保线程线程先到先服务的公平性,因此尾指针可以说是构建逻辑队列的桥梁;此外这个尾节点指针是原子引用类型,避免了多线程并发操作的线程安全性问题;
- 通过等待锁的每个线程在自己的某个变量上自旋等待,这个变量将由前一个线程写入。由于某个线程获取锁操作时总是通过尾节点指针获取到前一线程写入的变量,而尾节点指针又是原子引用类型,因此确保了这个变量获取出来总是线程安全的。
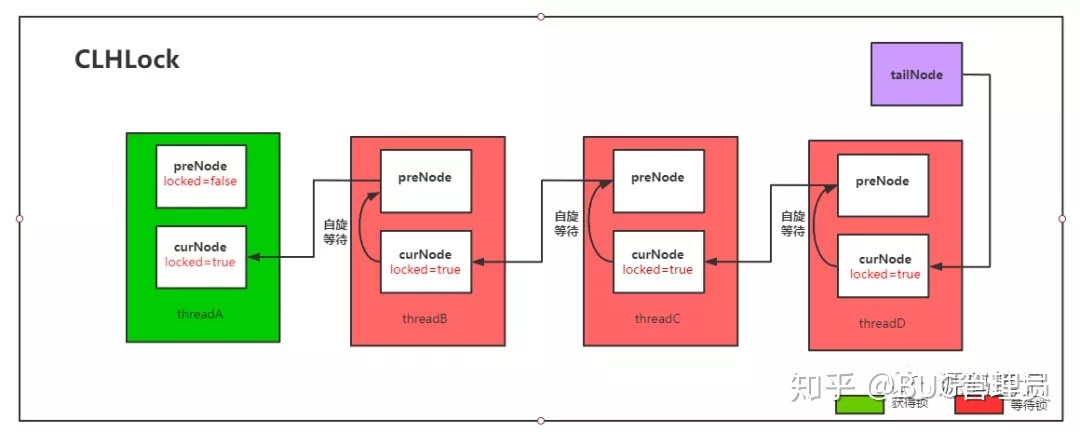
- 原理
- CLH 锁
- 可重入:同一个线程对于已经获得到的锁,可以多次继续申请到该锁的使用权
- AQS:AbstractQueuedSynchronizer 的缩写
- ReentrantLock 实现了 Lock 接口,操作其成员变量 sync(AQS 的子类),来完成锁的相关功能。
- sync 有 2 种形态:NonfairSync 和 FairSync。
- FairSync
- 在 tryAquire 方法中,当判断到锁状态字段
state == 0时,不会立马将当前线程设置为该锁的占用线程,而是去判断是在此线程之前是否有其他线程在等待这个锁(执行hasQueuedPredecessors()方法),如果是的话,则该线程会加入到等待队列中,进行排队(FIFO,先进先出的排队形式)。 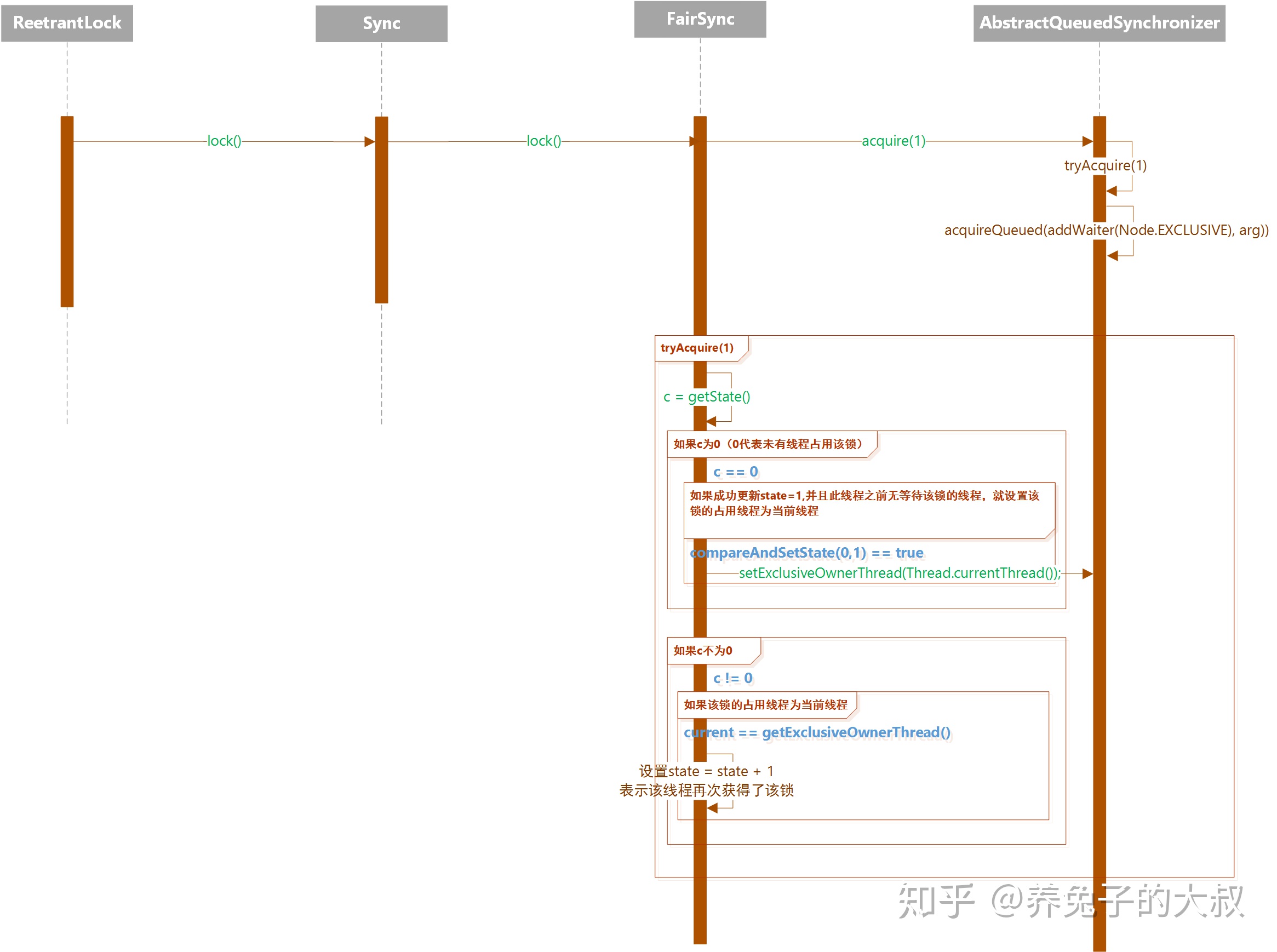
- 在 tryAquire 方法中,当判断到锁状态字段
- NoFairSync
- 在 tryAquire 方法中,没有判断是否有在此之前的排队线程,而是直接进行获锁操作,因此多个线程之间同时争用一把锁的时候,谁先获取到就变得随机了,很有可能线程 A 比线程 B 更早等待这把锁,但是B却获取到了锁,A 继续等待。
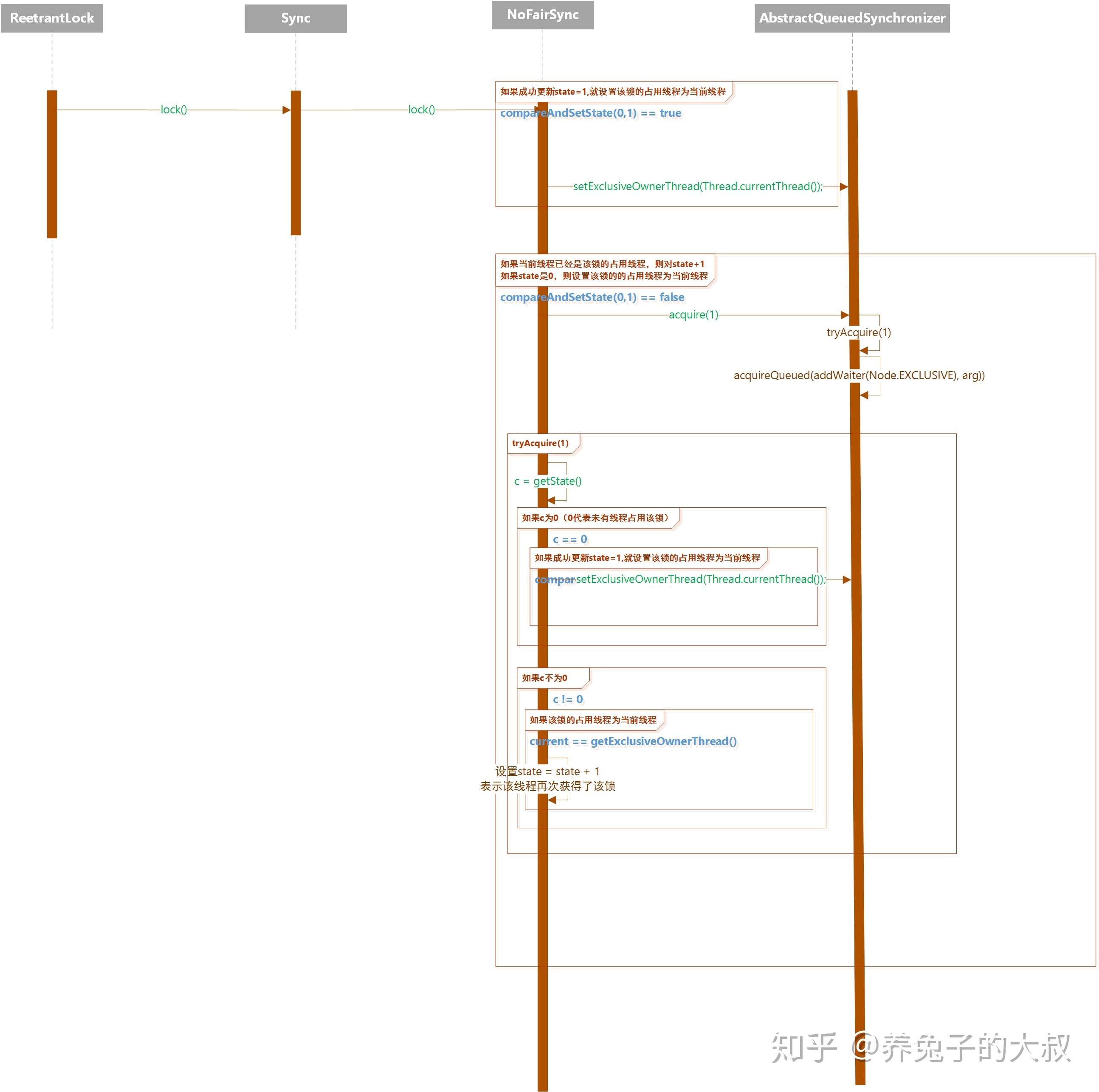
- FairSync
- sync 有 2 种形态:NonfairSync 和 FairSync。
- Node
- Node 结点是对每一个访问同步代码的线程的封装
- 其包含了需要同步的线程本身以及线程的状态,如是否被阻塞,是否等待唤醒,是否已经被取消等。每个 Node 结点内部关联其前继结点 prev 和后继结点 next,这样可以方便线程释放锁后快速唤醒下一个在等待的线程。
- 结构
- waitStatus
- 表示当前被封装成 Node 结点的等待状态
- CANCELLED
- 值为 1,在同步队列中等待的线程等待超时或被中断,需要从同步队列中取消该 Node 的结点,其结点的 waitStatus 为 CANCELLED,即结束状态,进入该状态后的结点将不会再变化。
- SIGNAL
- 值为 -1,被标识为该等待唤醒状态的后继结点,当其前继结点的线程释放了同步锁或被取消,将会通知该后继结点的线程执行。说白了,就是处于唤醒状态,只要前继结点释放锁,就会通知标识为 SIGNAL 状态的后继结点的线程执行。
- CONDITION
- 值为 -2,与 Condition 相关,该标识的结点处于等待队列中,结点的线程等待在 Condition 上,当其他线程调用了 Condition 的
signal()方法后,CONDITION 状态的结点将从等待队列转移到同步队列中,等待获取同步锁。
- 值为 -2,与 Condition 相关,该标识的结点处于等待队列中,结点的线程等待在 Condition 上,当其他线程调用了 Condition 的
- PROPAGATE
- 值为 -3,与共享模式相关,在共享模式中,该状态标识结点的线程处于可运行状态。
- 0 状态
- 值为0,代表初始化状态。
- CANCELLED
- 表示当前被封装成 Node 结点的等待状态
- waitStatus
- Condition
- Condition 的具体实现类是 AQS 的内部类 ConditionObject。
- 每个 Condition 都对应着一个等待队列,也就是说如果一个锁上创建了多个 Condition 对象,那么也就存在多个等待队列。等待队列是一个 FIFO 的队列,在队列中每一个节点都包含了一个线程的引用,而该线程就是 Condition 对象上等待的线程。当一个线程调用了
await()相关的方法,那么该线程将会释放锁,并构建一个 Node 节点封装当前线程的相关信息加入到等待队列中进行等待,直到被唤醒、中断、超时才从队列中移出。 - Condition 结构
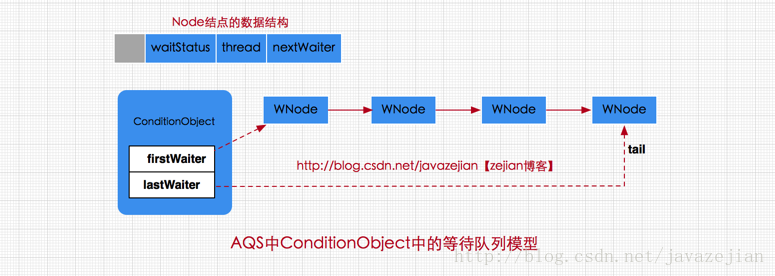
- 等待队列中结点的状态只有两种即 CANCELLED 和 CONDITION
- 相关问题
- 线程是什么时候排队的?
- 在获锁的时候,无法成功获取到该锁,然后进行排队等待。
- 线程是如何排队的?

- 想要知道如何排队,那也就是去理解
addWaiter(Node.EXCLUSIVE)这个方法具体是如何实现的。 - 流程
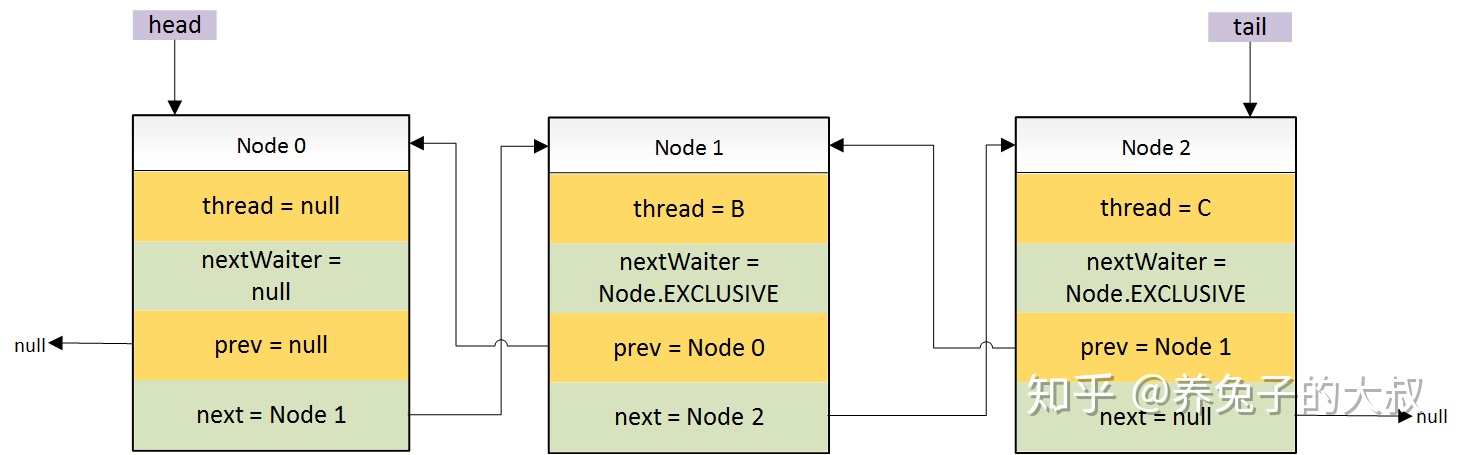
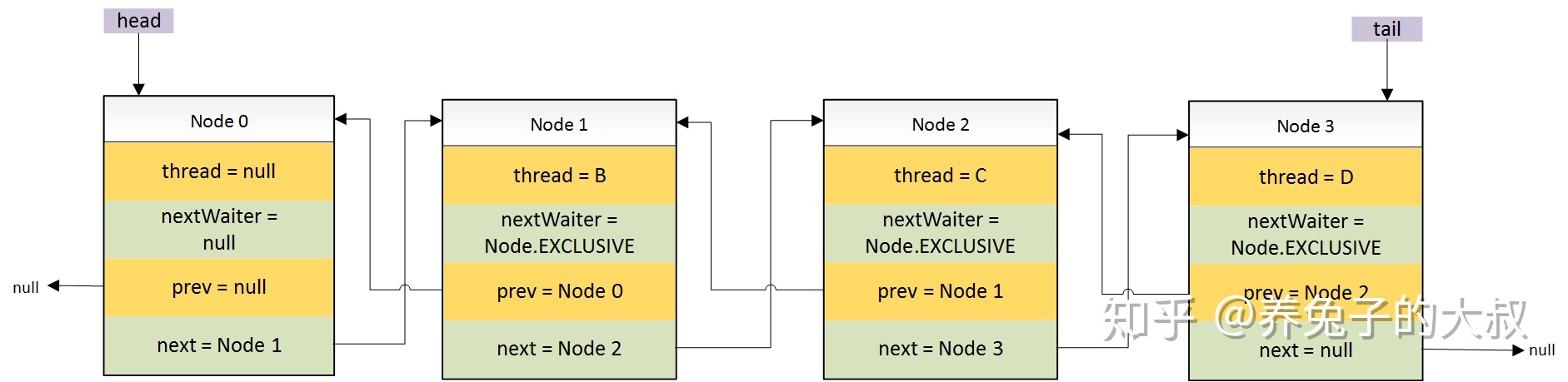
- 初始状态(也就是锁未被任何线程占用的时候)线程 A 申请锁。此时,成功获取到锁,无排队线程。
- 线程 B 申请该锁,且上一个线程未释放。
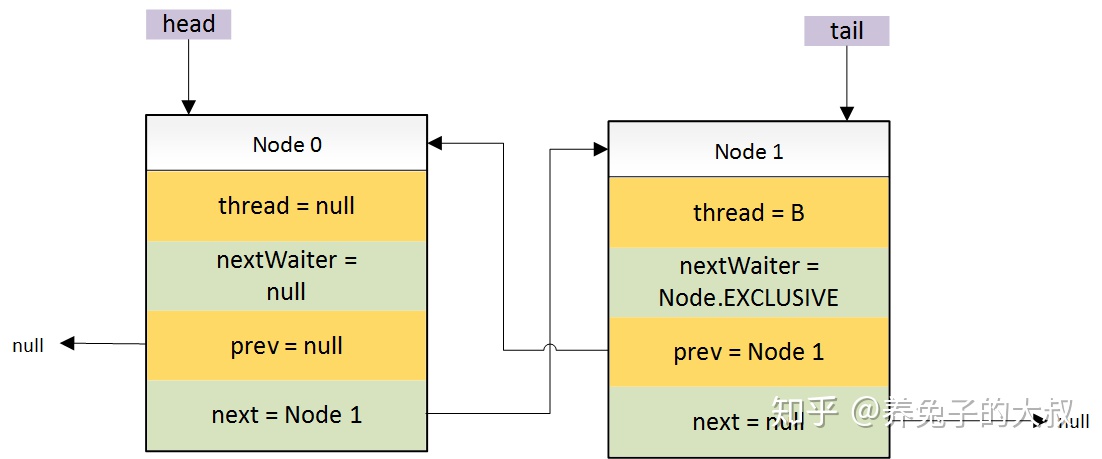
- 这里需要关注的是 Head 节点,这个节点是一个空的 Node 节点,不存储任何线程相关的信息
- 线程 C 申请该锁,且占有该锁的线程未释放
- 线程 D 申请该锁,且占有该锁的线程未释放
- 等待中的线程如何感知到锁空闲并获得锁?
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)中的addWaiter(Node.EXCLUSIVE)方法是对获锁失败的线程放入到队列中排队等待,而该方法的外层方法acquireQueued()就是对已经排队中的线程进行“获锁”操作。- 就是一个线程获取锁失败了,被放到了线程等待队列中,而 acquireQueued 方法就是把放入队列中的这个线程不断进行“获锁”,直到它“成功获锁”或者“不再需要锁(如被中断)”。
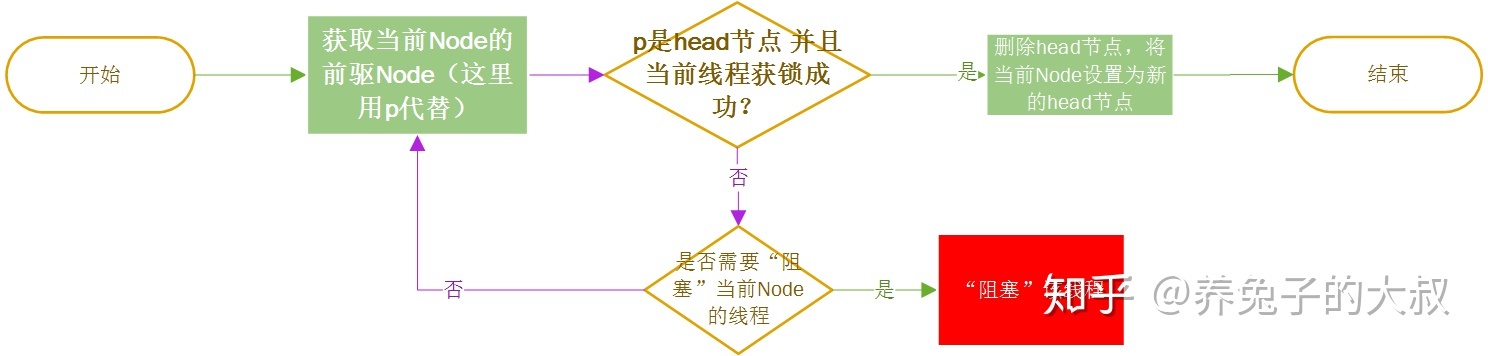
- 不管公平还是非公平模式下,ReentrantLock 对于排队中的线程都能保证,排在前面的一定比排在后面的线程优先获得锁。但是,非公平模式不保证队列中的第一个线程一定就比新来的(未加入到队列)的线程优先获锁。因为队列中的第一个线程尝试获得锁时,可能刚好来了一个线程也要获取锁,而这个刚来的线程都还未加入到等待队列,此时两个线程同时随机竞争,很有可能,队列中的第一个线程竞争失败(而该线程等待的时间其实比这个刚来的线程等待时间要久)。
- 什么时候线程需要被阻塞呢?
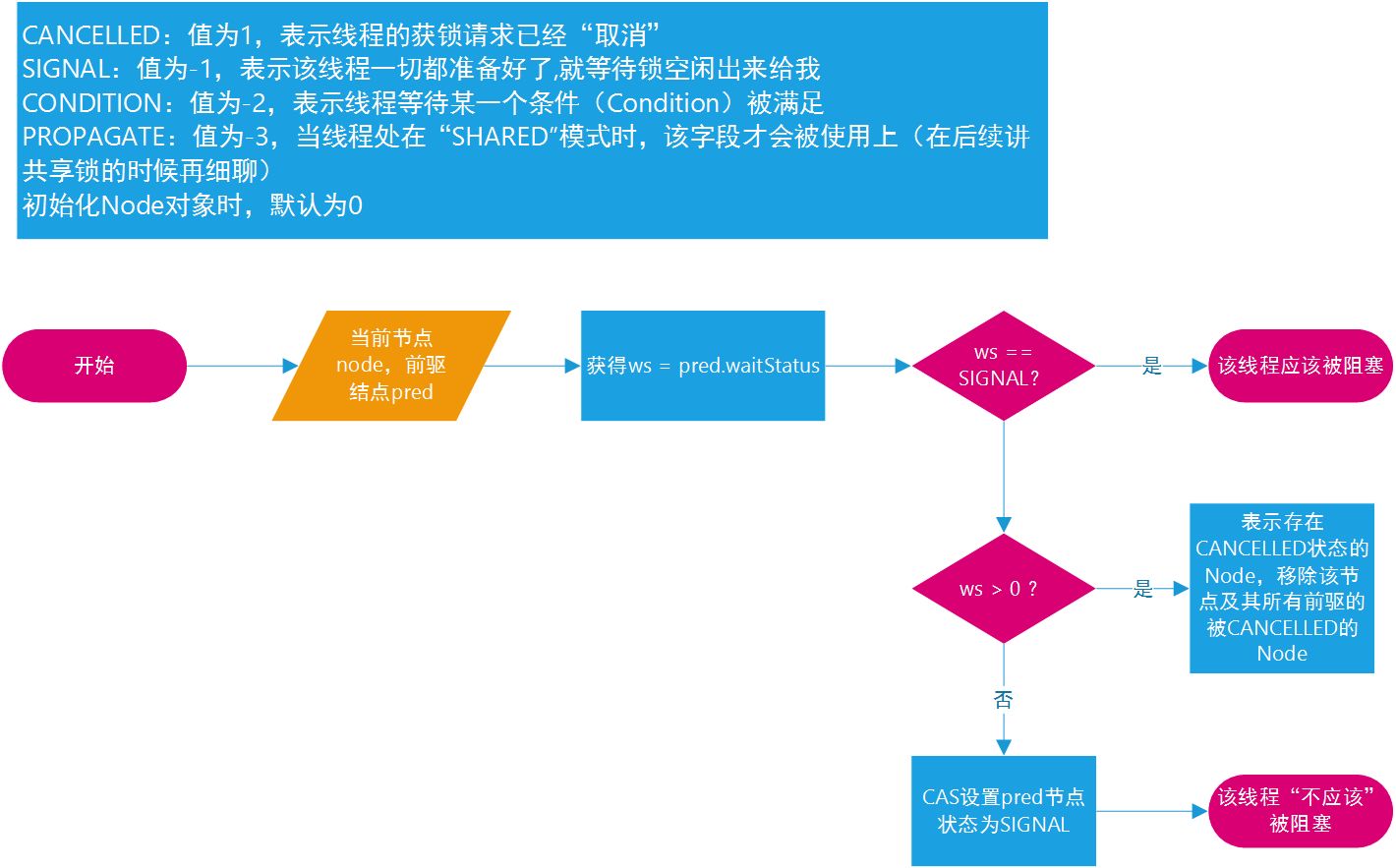
- while 循环中必须要这个 node 符合“它就是该队列中最早的 Node 并且获锁成功”才会跳出 while 循环体,如果不是,则会继续执行到“判断这个线程是否应该被阻塞”,此时。原本状态不是 SIGNAL 的线程,因为在上一次“判断这个线程是否应该被阻塞”这个方法时被设置成了 SIGNAL,那么第二次执行这个判断时,就会被成功阻塞。也就不会出现“空跑”的情况。
- 那什么时候唤醒这些阻塞的线程呢?

unparkSuccessor(h)方法就是“唤醒操作”,主要流程如代码所示- 尝试释放当前线程持有的锁
- 如果成功释放,那么去唤醒头结点的后继节点(因为头节点 head 是不保存线程信息的节点,仅仅是因为数据结构设计上的需要,在数据结构上,这种做法往往叫做“空头节点链表”。对应的就有“非空头结点链表”)
- synchronized、ReentrantLock 的区别
- 非公平锁比公平锁高效的原因?
- 因为线程切换的开销。如果一个线程在 running 期间直接抢占到锁资源,就不需要进行【恢复现场】操作,也就可以更快地执行业务代码。相反地,如果是一个就绪态的线程想要获得锁资源,首先需要恢复现场,之后争抢锁(可能成功也可能失败),此时就已经浪费了大量的 CPU,只有在获取锁成功后才能继续执行业务代码。
- 非公平锁减少了线程挂起的几率,后来的线程有一定几率逃离被挂起的开销。
- 线程是什么时候排队的?
- 基于 AQS 而形成了一个“可重入锁”
- ReentrantReadWriteLock
- 表示两个锁,一个是读操作相关的锁,称为共享锁;一个是写相关的锁,称为排他锁
- 入锁条件:
- 线程进入读锁的前提条件:
- 没有其他线程的写锁
- 没有写请求或者有写请求,但调用线程和持有锁的线程是同一个。
- 线程进入写锁的前提条件:
- 没有其他线程的读锁
- 没有其他线程的写锁
- 线程进入读锁的前提条件:
- 三个重要的特性:
- 公平选择性:支持非公平(默认)和公平的锁获取方式,吞吐量还是非公平优于公平。
- 重进入:读锁和写锁都支持线程重进入。
- 锁降级:遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级成为读锁。
- 结构
- 原理
- 同步状态在重入锁的实现中是表示被同一个线程重复获取的次数,即一个整形变量来维护,但是之前的那个表示仅仅表示是否锁定,而不用区分是读锁还是写锁。而读写锁需要在同步状态(一个整形变量)上维护多个读线程和一个写线程的状态。
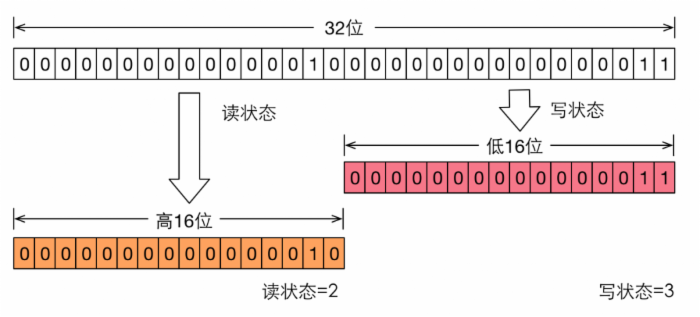
- 读写锁对于同步状态的实现是在一个整形变量上通过“按位切割使用”:将变量切割成两部分,高 16 位表示读,低 16 位表示写。
- 读锁
- 加锁过程
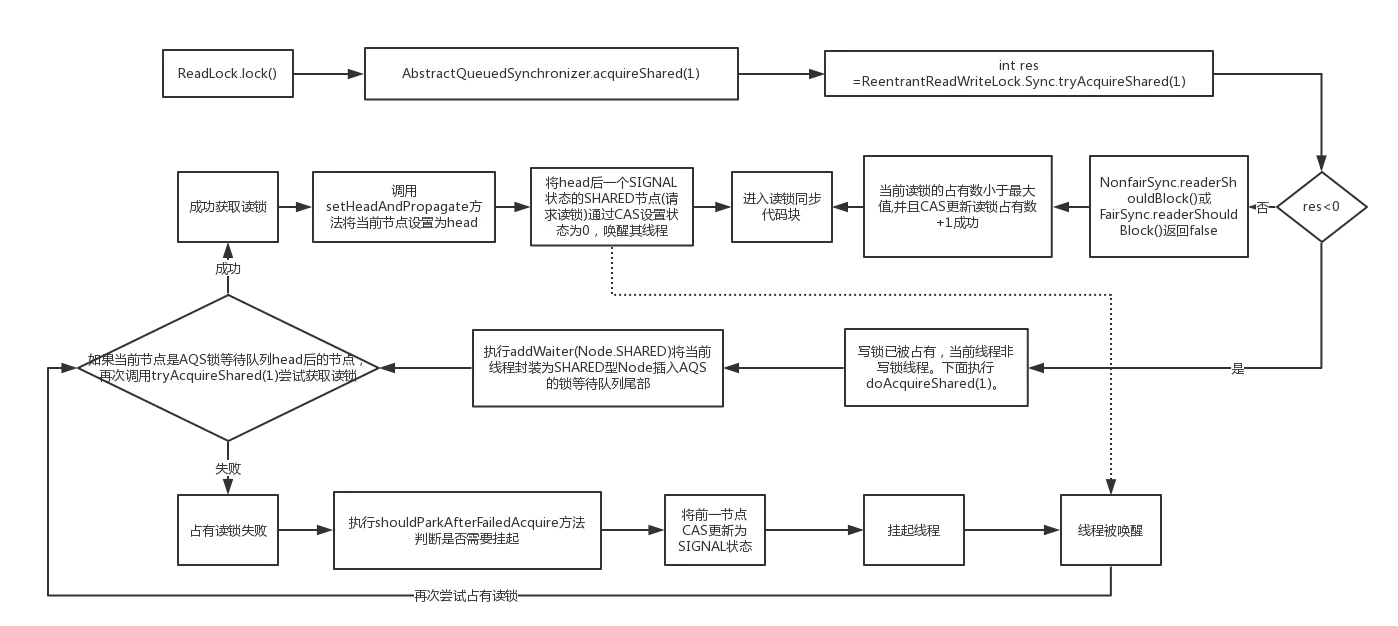
- 读锁的获取条件要满足:
- 当前的写锁未被占有(AQS state 变量低 16 位为 0)或者当前线程是写锁占有的线程
readerShouldBlock()方法返回 false- 当前读锁占有量小于最大值
(2^16 -1) - 成功通过 CAS 操作将读锁占有量 +1(AQS 的 state 高 16 位同步加 1)
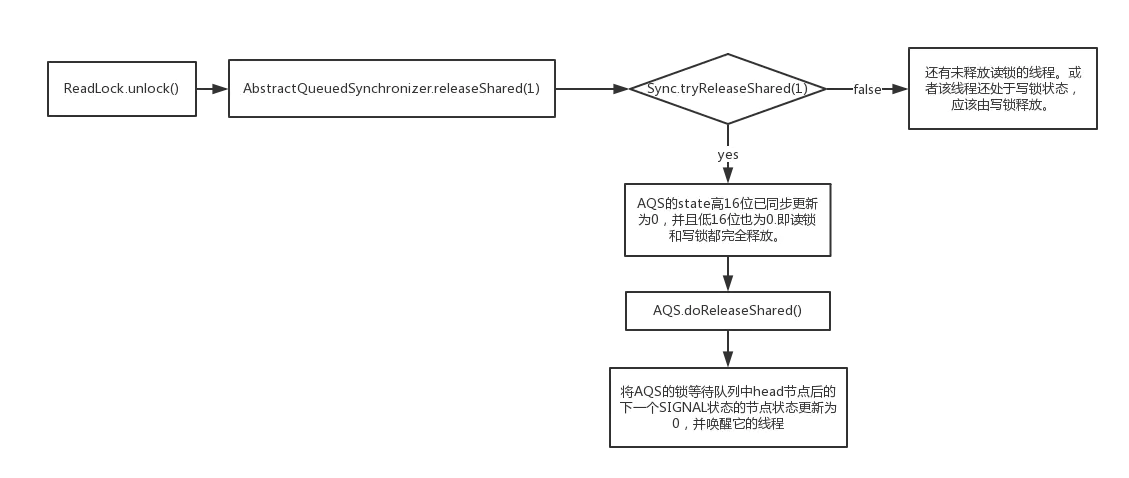
- 释放过程
- 加锁过程
- 写锁
- 加锁过程
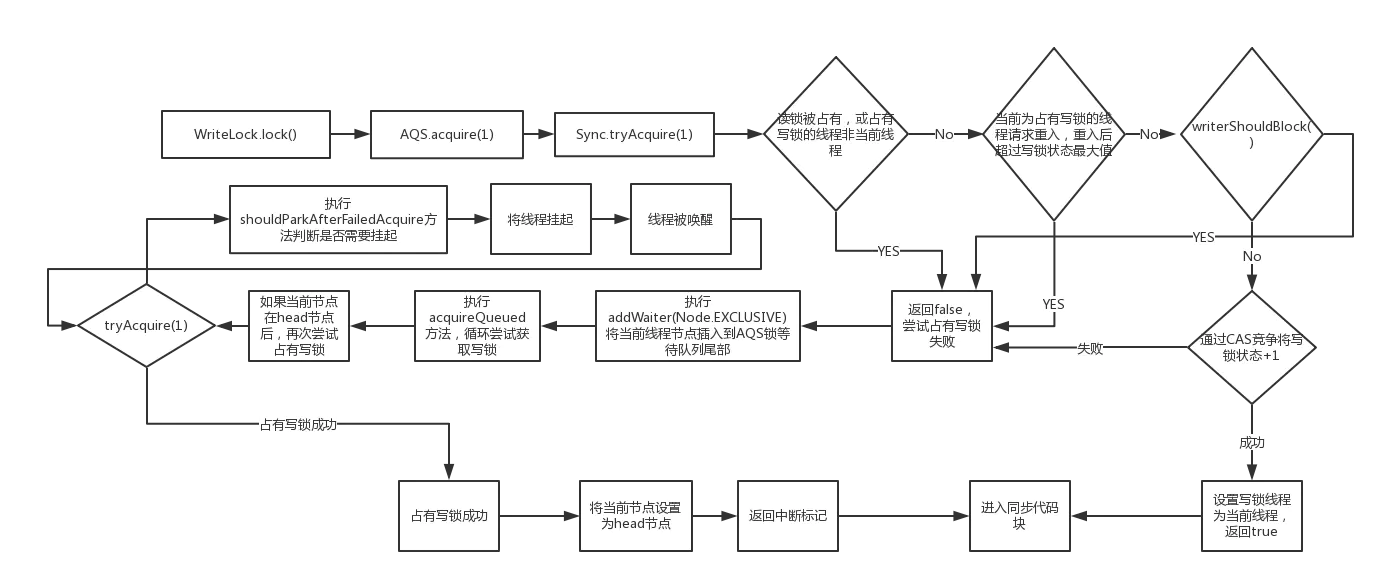
- 写锁获取的条件需要满足:
- 读锁未被占用(AQS state 高 16 位为 0) ,写锁未被占用(state 低 16 位为 0)或者占用写锁的线程是当前线程
writerShouldBlock()方法返回 false,即不阻塞写线程- 当前写锁占有量小于最大值(2^16 -1),否则抛出Error(“Maximum lock count exceeded”)
- 通过 CAS 竞争将写锁状态 +1(将 state 低 16 位同步 +1)
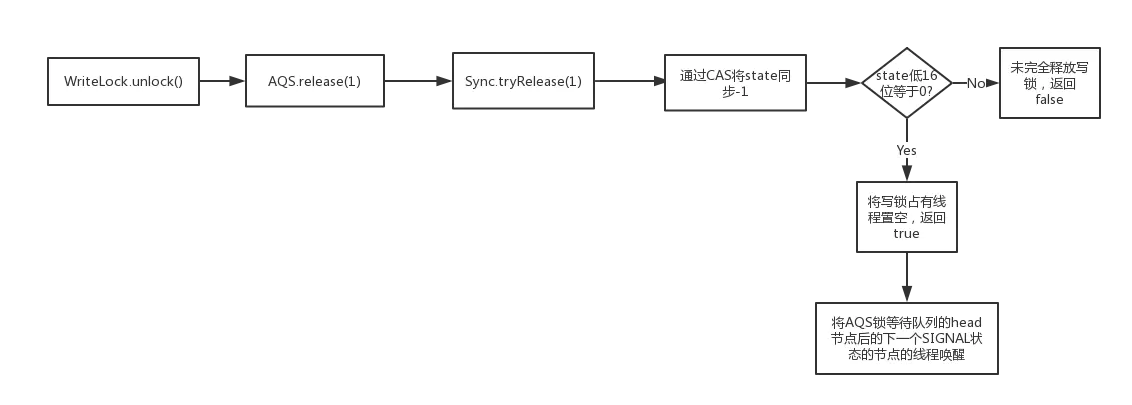
- 释放过程
- 加锁过程
- StampedLock
- StampedLock 类,在 JDK1.8 时引入,是对读写锁 ReentrantReadWriteLock 的增强,该类提供了一些功能,优化了读锁、写锁的访问,同时使读写锁之间可以互相转换,更细粒度控制并发。
- StampedLock 是不可重入锁。
- 主要特点
- 所有获取锁的方法,都返回一个邮戳(Stamp),Stamp 为 0 表示获取失败,其余都表示成功;
- 所有释放锁的方法,都需要一个邮戳(Stamp),这个 Stamp 必须是和成功获取锁时得到的 Stamp 一致;
- StampedLock 是不可重入的;(如果一个线程已经持有了写锁,再去获取写锁的话就会造成死锁)
- StampedLock 支持读锁和写锁的相互转换
- 在 RRW 中,当线程获取到写锁后,可以降级为读锁,但是读锁是不能直接升级为写锁的。
- StampedLock 提供了读锁和写锁相互转换的功能,使得该类支持更多的应用场景。
- 无论写锁还是读锁,都不支持 Conditon 等待
- StampedLock 相比 ReentrantReadWriteLock,对多核 CPU 进行了优化。当 CPU 核数超过 1 时,会有一些自旋操作
- StampedLock 有三种访问模式:
- Reading(读模式):功能和 ReentrantReadWriteLock 的读锁类似
- Writing(写模式):功能和 ReentrantReadWriteLock 的写锁类似
- Optimistic reading(乐观读模式):这是一种优化的读模式
- 读的时候不加读锁,读出来发现数据被修改了,再升级为“悲观读”;即读错了再严格读一次,避免写线程被饿死。乐观读不能保证读取到的数据是最新的,所以将数据读取到局部变量的时候需要通过
lock.validate(stamp)校验是否被写线程修改过,若是修改过则需要上悲观读锁,再重新读取数据到局部变量。- stamp 类似 version
- 读的时候不加读锁,读出来发现数据被修改了,再升级为“悲观读”;即读错了再严格读一次,避免写线程被饿死。乐观读不能保证读取到的数据是最新的,所以将数据读取到局部变量的时候需要通过
- 原理
- StampedLock 虽然不像其它锁一样定义了内部类来实现 AQS 框架,但是 StampedLock 的基本实现思路还是利用 CLH 队列进行线程的管理,通过同步状态值来表示锁的状态和类型。
- 相关问题
- 为什么有了 ReentrantReadWriteLock,还要引入 StampedLock?
- ReentrantReadWriteLock 使得多个读线程同时持有读锁(只要写锁未被占用),而写锁是独占的。
- 但是,读写锁如果使用不当,很容易产生“饥饿”问题。
- 例如
- 比如在读线程非常多,写线程很少的情况下,很容易导致写线程“饥饿”,虽然使用“公平”策略可以一定程度上缓解这个问题,但是“公平”策略是以牺牲系统吞吐量为代价的。
- 线程饥饿
- 大量读多写少的场景,读线程连续抢占导致等待的写线程无法执行。
- 线程饥饿
- 比如在读线程非常多,写线程很少的情况下,很容易导致写线程“饥饿”,虽然使用“公平”策略可以一定程度上缓解这个问题,但是“公平”策略是以牺牲系统吞吐量为代价的。
- 例如
- 为什么有了 ReentrantReadWriteLock,还要引入 StampedLock?
- LockSupport
- 底层实现原理
- 在 Linux 系统下,是用的 Posix 线程库 pthread 中的 mutex(互斥量),condition(条件变量)来实现的。
- mutex 和 condition 保护了一个 _counter 的变量,当 park 时,这个变量被设置为 0,当 unpark 时,这个变量被设置为 1。
- LockSupport可以在任何场合使线程阻塞,同时也可以指定要唤醒的线程
- 使用 wait、notify 来实现等待唤醒功能至少有两个缺点:
- 在调用这两个方法前必须先获得锁对象,这限制了其使用场合:只能在同步代码块中。
- 当对象的等待队列中有多个线程时,notify 只能随机选择一个线程唤醒,无法唤醒指定的线程。
- 使用 wait、notify 来实现等待唤醒功能至少有两个缺点:
- 常用方法
LockSupport.park()- 用来阻塞当前线程
- 当调用
park()方法时,会将 _counter 置为 0,同时判断设置前值,等于 1 说明前面被 unpark 过,则直接退出,否则将使该线程阻塞。
LockSupport.park(Object blocker)- 指定线程阻塞的对象 blocker,该对象主要用来排查问题
LockSupport.unpark(Thread thread)- 用来唤醒线程,因为需要线程作参数,所以可以指定线程进行唤醒
- 当调用
unpark()方法时,会将 _counter 置为 1,同时判断设置前值,小于 1 会进行线程唤醒,否则直接退出。
- 相关问题
- 为什么可以先唤醒线程后阻塞线程?
- 因为 unpark 获得了一个凭证,之后调用 park 因为有凭证消费,故不会阻塞。
- 为什么唤醒两次后阻塞两次会阻塞线程?
- 因为凭证的数量最多为 1,连续调用两次 unpark 和调用一次 unpark 效果一样,只会增加一个凭证;而调用两次 park 却需要消费两个凭证。
- 为什么可以先唤醒线程后阻塞线程?
- 底层实现原理
- 概念
- ThreadLocal
- ThreadLocal 的作用
- 作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的,在多线程环境下,如何防止自己的变量被其它线程篡改。
- 隔离有什么用,会用在什么场景么?
- Spring 实现事务隔离级别
- Spring 采用 Threadlocal 的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接,同时,采用这种方式可以使业务层使用事务时不需要感知并管理 connection 对象,通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
- Spring 框架里面就是用的 ThreadLocal 来实现这种隔离,主要是在T ransactionSynchronizationManager 这个类里面
- Spring 的事务主要是 ThreadLocal 和 AOP 去做实现的
- 很多场景的 cookie,session 等数据隔离都是通过 ThreadLocal 去做实现的。
- Spring 实现事务隔离级别
- 隔离有什么用,会用在什么场景么?
- 作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的,在多线程环境下,如何防止自己的变量被其它线程篡改。
- 常用于以下这个场景
- 多线程环境下存在对非线程安全对象的并发访问,而且该对象不需要在线程间共享,但是我们不想加锁,这时候可以使用 ThreadLocal 来使得每个线程都持有一个该对象的副本。
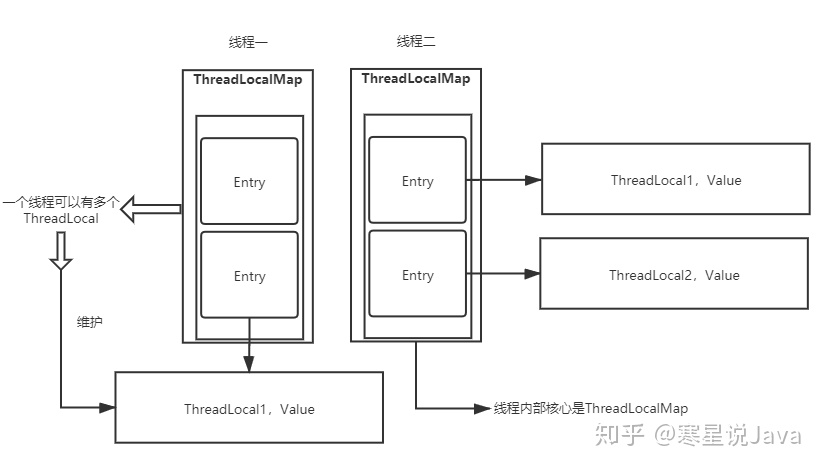
- 原理
- 每个 Thread 线程内部都有一个静态的 ThreadLocalMap。Map 里面存储线程本地对象 ThreadLocal(key)和线程的变量副本(value)。
- Thread 内部的 Map 是由 ThreadLocal 维护,ThreadLocal 负责向 map 获取和设置线程的变量值。
- 一个 Thread 可以有多个 ThreadLocal。
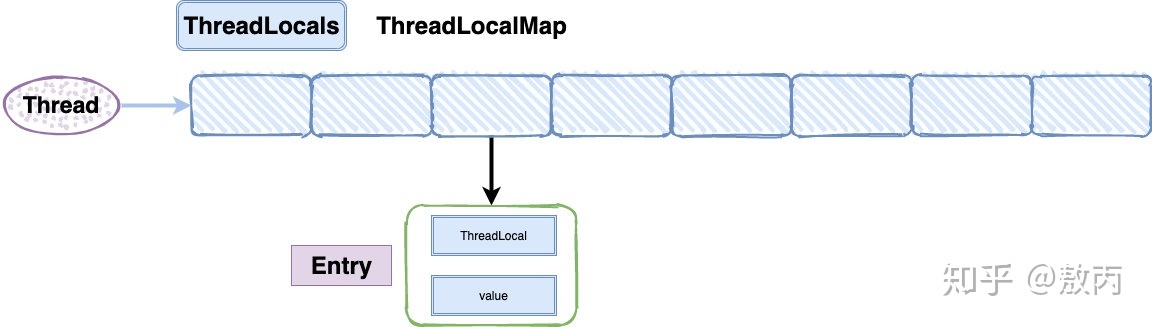
- Entry 是继承 WeakReference(弱引用)的,只用了数组没有用链表。
- 为什么需要数组呢?没有了链表怎么解决 Hash 冲突呢?
- 用数组是因为,我们开发过程中可以一个线程可以有多个 ThreadLocal 来存放不同类型的对象的,但是他们都将放到你当前线程的 ThreadLocalMap 里,所以肯定要数组来存。
- ThreadLocalMap 在存储的时候会给每一个 ThreadLocal 对象一个 threadLocalHashCode,在插入过程中,根据 ThreadLocal 对象的 hash 值,定位到 table 中的位置 i,
int i = key.threadLocalHashCode & (len-1)。- 然后会判断一下:如果当前位置是空的,就初始化一个 Entry 对象放在位置 i 上;
- 如果位置 i 不为空,如果这个 Entry 对象的 key 正好是即将设置的 key,那么就刷新 Entry 中的 value;
- 如果位置 i 的不为空,而且 key 不等于 entry,那就找下一个空位置,直到为空为止。
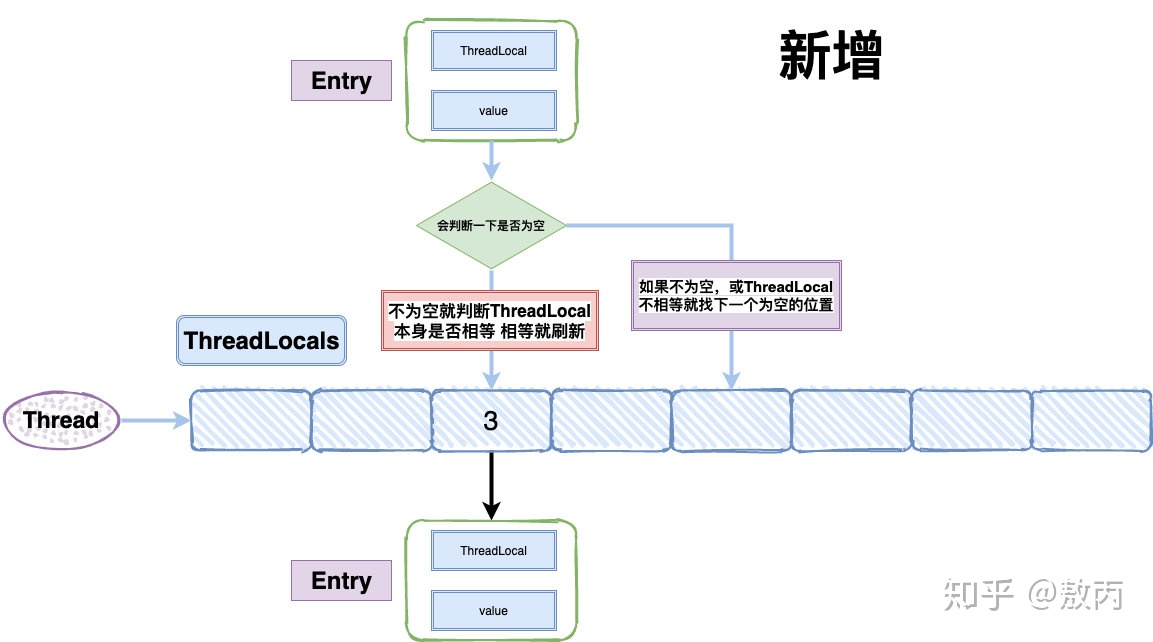
- 在 get 的时候,也会根据 ThreadLocal 对象的 hash 值,定位到 table 中的位置,然后判断该位置 Entry 对象中的 key 是否和 get 的 key 一致,如果不一致,就判断下一个位置,set 和 get 如果冲突严重的话,效率还是很低的。
- 为什么需要数组呢?没有了链表怎么解决 Hash 冲突呢?
- Entry 是继承 WeakReference(弱引用)的,只用了数组没有用链表。
- ThreadLocal 的问题
- 内存泄露
- ThreadLocal 在保存的时候会把自己当做 Key 存在 ThreadLocalMap 中,正常情况应该是 key 和 value 都应该被外界强引用才对,但是现在 key 被设计成 WeakReference 弱引用了。
- 这就导致了一个问题,ThreadLocal 在没有外部强引用时,发生 GC 时会被回收,如果创建 ThreadLocal 的线程一直持续运行,那么这个 Entry 对象中的 value 就有可能一直得不到回收,发生内存泄露。
- 就比如线程池里面的线程,线程都是复用的,那么之前的线程实例处理完之后,出于复用的目的线程依然存活,所以,ThreadLocal 设定的 value 值被持有,导致内存泄露。
- 按照道理一个线程使用完,ThreadLocalMap 是应该要被清空的,但是现在线程被复用了。
- 那怎么解决?
- 在代码的最后使用 remove 就好了,我们只要记得在使用的最后用 remove 把值清空就好了。
- 那怎么解决?
- 内存泄露
- 相关问题
- 如果我想共享线程的 ThreadLocal 数据怎么办?
- 使用 InheritableThreadLocal 可以实现多个线程访问 ThreadLocal 的值,我们在主线程中创建一个 InheritableThreadLocal 的实例,然后在子线程中得到这个 InheritableThreadLocal 实例设置的值。
- 怎么传递的呀?
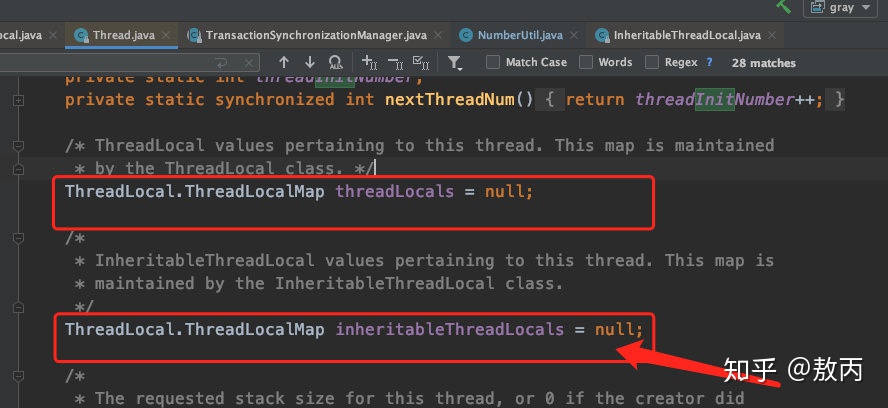
- ```
public class Thread implements Runnable {
……
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
……this.inheritableThreadLocals=ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267- 如果线程的 inheritThreadLocals 变量不为空,比如我们上面的例子,而且父线程的 inheritThreadLocals 也存在,那么我就把父线程的 inheritThreadLocals 给当前线程的 inheritThreadLocals。
- **那为什么 ThreadLocalMap 的 key 要设计成弱引用?**
- key 不设置成弱引用的话就会造成和 entry 中 value 一样内存泄漏的场景。
- 多线程相关使用类
- 原子操作相关类
- AtomicReference
- AtomicReference 是作用是对”对象”进行原子操作。提供了一种读和写都是原子性的对象引用变量。
- FieldUpdater
- 子类有:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater
- AtomicXXXFieldUpdater,就是可以以一种线程安全的方式操作非线程安全对象的某些字段
- 可以在不修改用户代码(调用方)的情况下,就能实现并发安全性
- 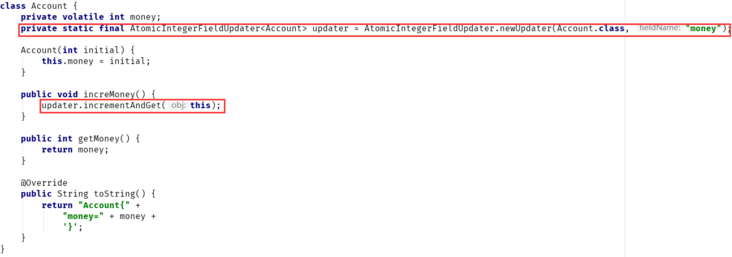
- AtomicReferenceFieldUpdater 的使用必须满足以下条件
- AtomicReferenceFieldUpdater 只能修改对于它可见的字段,也就是说对于目标类的某个字段 field,如果修饰符是 private,但是 AtomicReferenceFieldUpdater 所在的使用类不能看到 field,那就会报错;
- 目标类的操作字段,必须用 volatile 修饰;
- 目标类的操作字段,不能是 static 的;
- AtomicReferenceFieldUpdater 只适用于引用类型的字段;
- 原理
- 利用 Unsafe 进行 CAS 更新
- LongAdder
- JDK1.8 时,java.util.concurrent.atomic 包中提供了一个新的原子类:LongAdder。
- 根据 Oracle 官方文档的介绍,LongAdder 在高并发的场景下会比它的前辈(AtomicLong)具有更好的性能,代价是消耗更多的内存空间
- 原理
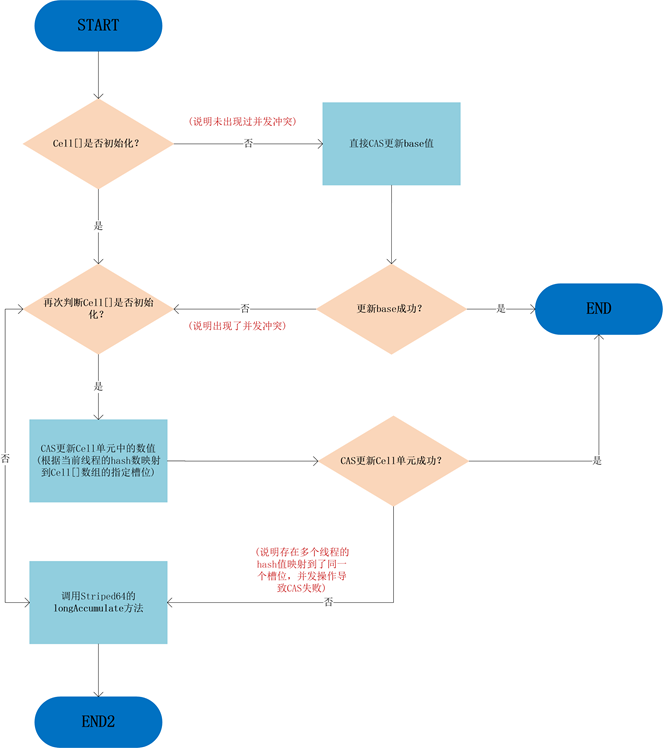
- 内部是一个 Base + 一个 Cell 数组
- base 变量:非竞争状态条件下,直接累加到该变量上
- Cell数组:竞争条件下(高并发下),累加各个线程自己的槽 `Cell[i]` 中
- add 方法
- 
- sum 方法
- $\text { value }=\text { base }+\sum_{i=0}^{n} \operatorname{Cell}[i]$
- 相关类
- LongAccumulator
- LongAccumulator 是 LongAdder 的增强版。LongAdder 只能针对数值的进行加减运算,而 LongAccumulator 提供了自定义的函数操作。
- DoubleAdder
- DoubleAccumulator
- 相关问题
- **为什么要引入 LongAdder?**
- AtomicLong 是利用了底层的 CAS 操作来提供并发性的,比如 addAndGet 方法:
- 
- 上述方法调用了 Unsafe 类的 getAndAddLong 方法,该方法内部是个 native 方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。
- 在并发量较低的环境下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发环境下,N 个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时 AtomicLong 的自旋会成为瓶颈。
- 这就是 LongAdder 引入的初衷-d解决高并发环境下 AtomicLong 的自旋瓶颈问题。
- **LongAdder 快在哪里?**
- AtomicLong 中有个内部变量 value 保存着实际的 long 值,所有的操作都是针对该变量进行。也就是说,高并发环境下,value 变量其实是一个热点,也就是 N 个线程竞争一个热点。
- LongAdder 的基本思路就是分散热点,将 value 值拆分到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行 CAS 操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的 long 值,只要将各个槽中的变量值累加返回。
- 其他
- Semaphore
- Semaphore,又名信号量,这个类的作用有点类似于“许可证”。有时,我们因为一些原因需要控制同时访问共享资源的最大线程数量,比如出于系统性能的考虑需要限流,或者共享资源是稀缺资源,我们需要有一种办法能够协调各个线程,以保证合理的使用公共资源。
- Semaphore 维护了一个许可集,其实就是一定数量的“许可证”。
- 当有线程想要访问共享资源时,需要先获取(acquire)的许可;如果许可不够了,线程需要一直等待,直到许可可用。当线程使用完共享资源后,可以归还(release)许可,以供其它需要的线程使用。
- Semaphore 其实就是实现了AQS共享功能的同步器
- 注意:Semaphore 不是锁,只能限制同时访问资源的线程数,至于对数据一致性的控制,Semaphore 是不关心的。当前,如果是只有一个许可的 Semaphore,可以当作锁使用。
- CyclicBarrier
- CyclicBarrier 是一个辅助同步器类,在 JDK1.5 时随着 J.U.C 一起引入。
- CyclicBarrier 可以认为是一个栅栏。让线程到达栅栏时被阻塞(调用await方法),直到到达栅栏的线程数满足指定数量要求时,栅栏才会打开放行。
- 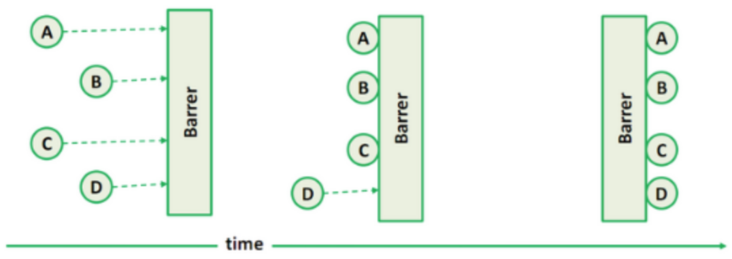
- CyclicBarrier 是可以循环复用的
- CountDownLatch
- CountDownLatch 是一个辅助同步器类,用来作计数使用,它的作用有点类似于生活中的倒数计数器,先设定一个计数初始值,当计数降到0时,将会触发一些事件,如火箭的倒数计时。
- 用法
- 初始计数值在构造 CountDownLatch 对象时传入,每调用一次 `countDown()` 方法,计数值就会减 1。
- 线程可以调用 CountDownLatch 的 await 方法进入阻塞,当计数值降到 0 时,所有之前调用 await 阻塞的线程都会释放。
- 注意:CountDownLatch 的初始计数值一旦降到 0,无法重置。如果需要重置,可以考虑使用 CyclicBarrier。
- Exchanger
- Exchanger-交换器,是 JDK1.5 时引入的一个同步器,从字面上就可以看出,这个类的主要作用是交换数据。
- Exchanger 有点类似于 CyclicBarrier。Exchanger 可以看成是一个双向栅栏。
- 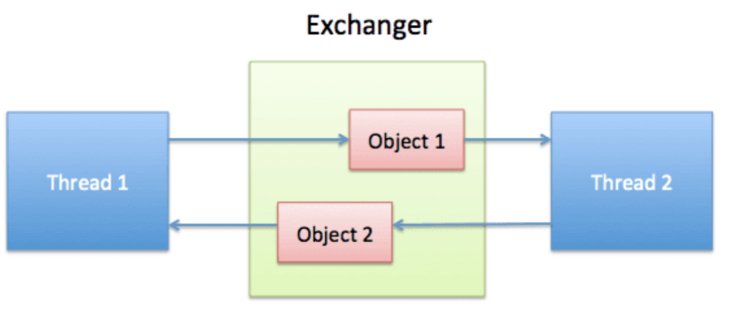
- Thread1 线程到达栅栏后,会首先观察有没其它线程已经到达栅栏,如果没有就会等待,如果已经有其它线程(Thread2)已经到达了,就会以成对的方式交换各自携带的信息,因此 Exchanger 非常适合用于两个线程之间的数据交换。
- Phaser
- Phaser 是 JDK1.7 开始引入的一个同步工具类,适用于一些需要分阶段的任务的处理。它的功能与 CyclicBarrier 和 CountDownLatch 有些类似,类似于一个多阶段的栅栏,并且功能更强大
- Fork/Join 框架
- Fork/Join 框架是在 java7 之后提供的一种基于分治策略的多线程框架。与分支策略思想一样,即一个大问题可以被拆分为若干个小问题,而且小问题之间互不干扰,并且解法与原问题形式相同,最终将子问题的解合并可以得到原问题的解。
- 执行流程
- 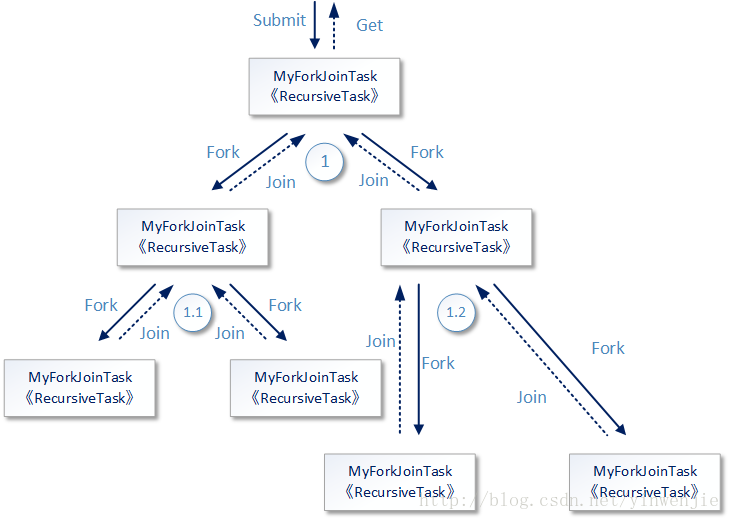
- 相关类
- RecursiveTask
- ForkJoinPool
- 线程
- 线程的五种状态
- 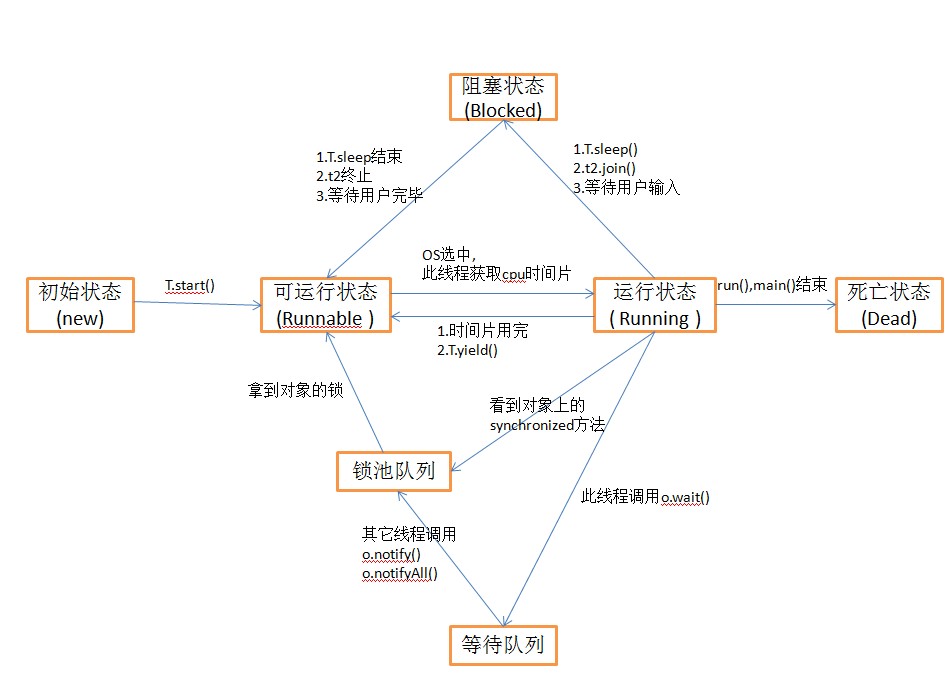
- NEW
- 新创建了一个线程对象。
- RUNNABLE
- 线程对象创建后,其他线程(比如 main 线程)调用了该对象的 `start()` 方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取 cpu 的使用权。
- RUNNING
- 可运行状态(runnable)的线程获得了 cpu 时间片(timeslice),执行程序代码。
- BLOCKED
- 阻塞状态是指线程因为某种原因放弃了 cpu 使用权,也即让出了 cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得 cpu timeslice 转到运行(running)状态。阻塞的情况分三种:
- 等待阻塞:运行(running)的线程执行 `o.wait()` 方法,JVM 会把该线程放入等待队列(waitting queue)中。
- 等待队列
- 调用 obj 的 `wait()`,`notify()`方法前,必须获得 obj 锁,也就是必须写在 `synchronized(obj)` 代码段内。
- 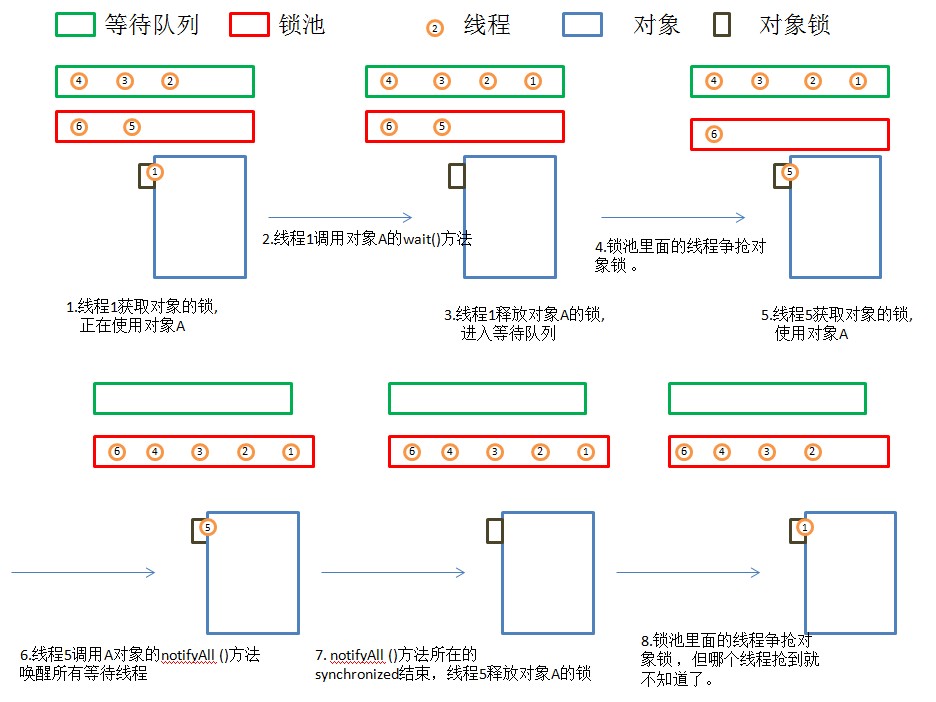
- 锁池状态
- 当前线程想调用对象 A 的同步方法时,发现对象 A 的锁被别的线程占有,此时当前线程进入锁池状态。简言之,锁池里面放的都是想争夺对象锁的线程。
- 当一个线程 1 被另外一个线程 2 唤醒时,1 线程进入锁池状态,去争夺对象锁。
- 锁池是在同步的环境下才有的概念,一个对象对应一个锁池。
- 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则 JVM 会把该线程放入锁池(lock pool)中。
- 其他阻塞:运行(running)的线程执行 `Thread.sleep(long ms)` 或 `t.join()` 方法,或者发出了 I/O 请求时,JVM 会把该线程置为阻塞状态。当 `sleep()` 状态超时、`join()` 等待线程终止或者超时、或者 I/O 处理完毕时,线程重新转入可运行(runnable)状态。
- DEAD
- 线程 `run()`、`main()` 方法执行结束,或者因异常退出了 `run()` 方法,则该线程结束生命周期。死亡的线程不可再次复生。
- 几种会导致线程状态改变的方法
- api
- `Thread.sleep(long millis)`,一定是当前线程调用此方法,当前线程进入阻塞,但不释放对象锁,millis 后线程自动苏醒进入可运行状态。
- 作用:给其它线程执行机会的最佳方式。
- `Thread.yield()`,一定是当前线程调用此方法,当前线程放弃获取的 cpu 时间片,由运行状态变会可运行状态,让 OS 再次选择线程。
- 作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证 `yield()` 达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。`Thread.yield()` 不会导致阻塞。
- `t.join()/t.join(long millis)`,当前线程里调用其它线程 1 的 join 方法,当前线程阻塞,但不释放对象锁,直到线程 1 执行完毕或者 millis 时间到,当前线程进入可运行状态。
- `obj.wait()`,当前线程调用对象的 `wait()` 方法,当前线程释放对象锁,进入等待队列。依靠 `notify()/notifyAll()` 唤醒或者 `wait(long timeout)` timeout 时间到自动唤醒。
- `obj.notify()`,唤醒在此对象监视器上等待的单个线程,选择是任意性的。`notifyAll()` 唤醒在此对象监视器上等待的所有线程。
- 应用
- `Thread.yield()` 和 `Thread.sleep(0)`
- `Thread.yield()` 和 `Thread.sleep(0)` 语义实现取决于具体的 JVM,某些 JVM 可能什么都不做,而大多数虚拟机会让线程放弃剩余的 cpu 时间片,重新变为 runnable 状态,并放到同优先级线程队列的末尾等待 cpu 资源。 但是当我们调用 `Thread.yield()` 的那一刻,并不意味着当前线程立马释放 cpu 资源,这是因为获得时间片的线程从 runable 切换到 running 仍需要一定的准备时间,这段时间当前线程仍可能运行一小段时间。
- Thread 的常用方法
- `interrupt()`
- 其作用是中断此线程(此线程不一定是当前线程,而是指调用该方法的 Thread 实例所代表的线程),但实际上只是给线程设置一个中断标志,线程仍会继续运行。
- `interrupted()`
- 作用是测试当前线程是否被中断(检查中断标志),返回一个 boolean 并清除中断状态,第二次再调用时中断状态已经被清除,将返回一个 false。
- `isInterrupted()`
- 作用是只测试此线程是否被中断 ,不清除中断状态。
- `join()`
- 线程安全问题
- 运行结果错误
- 发布和初始化导致线程安全问题
- 我们创建对象并进行发布和初始化供其他类或对象使用是常见的操作,但如果我们操作的时间或地点不对,就可能导致线程安全问题。
- 活跃性问题
- 活跃性问题就是程序始终得不到运行的最终结果,相比于前面两种线程安全问题带来的数据错误或报错,活跃性问题带来的后果可能更严重,比如发生死锁会导致程序完全卡死,无法向下运行。
- 最典型的有三种
- 死锁
- 死锁是一种状态,当两个(或多个)线程(或进程)相互持有对方所需要的资源,却又都不主动释放自己手中所持有的资源,导致大家都获取不到自己想要的资源,所有相关的线程(或进程)都无法继续往下执行,在未改变这种状态之前都不能向前推进,我们就把这种状态称为死锁状态,认为它们发生了死锁。
- 活锁
- 举一个例子,假设有一个消息队列,队列里放着各种各样需要被处理的消息,而某个消息由于自身被写错了导致不能被正确处理,执行时会报错,可是队列的重试机制会重新把它放在队列头进行优先重试处理,但这个消息本身无论被执行多少次,都无法被正确处理,每次报错后又会被放到队列头进行重试,周而复始,最终导致线程一直处于忙碌状态,但程序始终得不到结果,便发生了活锁问题。
- 饥饿
- 饥饿是指线程需要某些资源时始终得不到,尤其是 CPU 资源,就会导致线程一直不能运行而产生的问题。
- 线程池
- 核心的参数概念
- 最大线程数 maximumPoolSize
- 该参数表示的是线程池中允许存在的最大线程数量。当任务队列满了以后,再有新的任务进入到线程池时,会判断再新建一个线程是否会超过 maximumPoolSize,如果会超过,则不创建线程,而是执行拒绝策略。如果不会超过 maximumPoolSize,则会创建新的线程来执行任务。
- 核心线程数 corePoolSize
- 该参数表示的是线程池的核心线程数。当任务提交到线程池时,如果线程池的线程数量还没有达到 corePoolSize,那么就会新创建的一个线程来执行任务,如果达到了,就将任务添加到任务队列中。
- 活跃时间 keepAliveTime
- 当线程池中的线程数量大于 corePoolSize 时,那么大于 corePoolSize 这部分的线程,如果没有任务去处理,那么就表示它们是空闲的,这个时候是不允许它们一直存在的,而是允许它们最多空闲一段时间,这段时间就是 keepAliveTime,时间的单位就是 TimeUnit。
- unit
- 空闲线程允许存活时间的单位,TimeUnit 是一个枚举值,它可以是纳秒、微妙、毫秒、秒、分、小时、天。
- 阻塞队列 workQueue
- 任务队列,用来存放任务。该队列的类型是阻塞队列,常用的阻塞队列有 ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue 等。
- ArrayBlockingQueue
- 是一个基于数组实现的阻塞队列,元素按照先进先出(FIFO)的顺序入队、出队。因为底层实现是数组,数组在初始化时必须指定大小,因此 ArrayBlockingQueue 是有界队列。
- LinkedBlockingQueue
- 是一个基于链表实现的阻塞队列,元素按照先进先出(FIFO)的顺序入队、出队。因为顶层是链表,链表是基于节点之间的指针指向来维持前后关系的,如果不指链表的大小,它默认的大小是 Integer.MAX_VALUE。这个数值太大了,因此通常称 LinkedBlockingQueue 是一个无界队列。当然如果在初始化的时候,就指定链表大小,那么它就是有界队列了。
- SynchronousQueue
- 是一个不存储元素的阻塞队列。每个插入操作必须得等到另一个线程调用了移除操作后,该线程才会返回,否则将一直阻塞。吞吐量通常要高于 LinkedBlockingQueue。
- PriorityBlockingQueue
- 是一个将元素按照优先级排序的阻塞的阻塞队列,元素的优先级越高,将会越先出队列。这是一个无界队列。
- threadFactory
- 线程池工厂,用来创建线程。通常在实际项目中,为了便于后期排查问题,在创建线程时需要为线程赋予一定的名称,通过线程池工厂,可以方便的为每一个创建的线程设置具有业务含义的名称。
- 拒绝策略 RejectedExecutionHandler
- AbortPolicy:直接丢弃任务,抛出异常,这是默认策略
- CallerRunsPolicy:只用调用者所在的线程来处理任务
- DiscardOldestPolicy:丢弃等待队列中最旧的任务,并执行当前任务
- DiscardPolicy:直接丢弃任务,也不抛出异常
- 分类
- FixedThreadPool
- 特点:固定池子中线程的个数。使用静态方法 `newFixedThreadPool()` 创建线程池的时候指定线程池个数。
- CachedThreadPool(弹性缓存线程池)
- 特点:用 `newCachedThreadPool()` 方法创建该线程池对象,创建之初里面一个线程都没有,当 execute 方法或 submit 方法向线程池提交任务时,会自动新建线程;如果线程池中有空余线程,则不会新建;这种线程池一般最多情况可以容纳几万个线程,里面的线程空余 60s 会被回收。
- SingleThreadPool(单线程线程池)
- 池中只有一个线程,如果扔 5 个任务进来,那么有 4 个任务将排队;作用是保证任务的顺序执行。
- ScheduledThreadpool(定时器线程池)
- 在给定延迟后运行命令或者定期地执行。
- WorkStealingPool
- 在 Java 8 中,引入了一种新型的线程池,作为 `newWorkStealingPool()` 来补充现有的线程池。WorkStealingPool 线程池,来维持相应的并行级别,它会通过工作窃取的方式,使得多核的 CPU 不会闲置,总会有活着的线程让 CPU 去运行。
- 它基于工作窃取算法,其中任务可以生成其他较小的任务,这些任务将添加到并行处理线程的队列中。如果一个线程完成了工作并且无事可做,则可以从另一线程的队列中“窃取”工作。
- 底层用的 ForkJoinPool 来实现的。
- ForkJoinPool
- 在 Java7 中引入。主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。ForkJoinPool 的优势在于,可以充分利用多 cpu,多核 cpu 的优势,把一个任务拆分成多个“小任务”分发到不同的 cpu 核心上执行,执行完后再把结果收集到一起返回。
- 线程池的五种状态
- 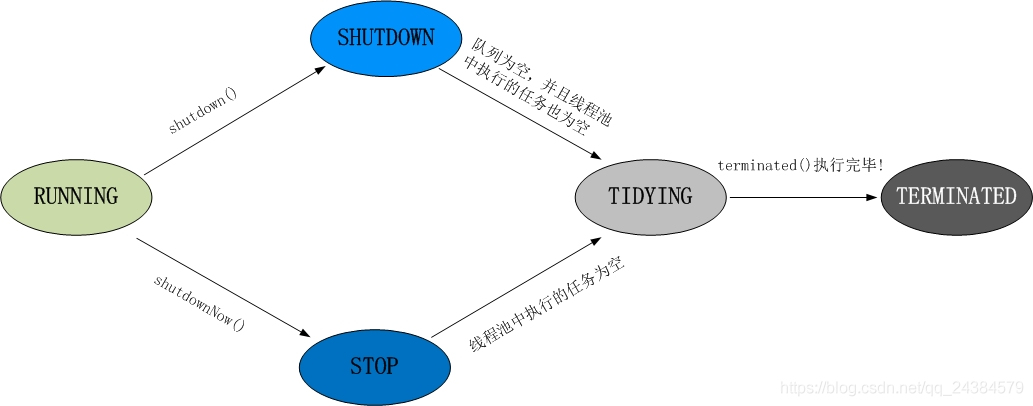
- RUNNING
- 状态说明:线程池处在 RUNNING 状态时,能够接收新任务,以及对已添加的任务进行处理。
- 状态切换:线程池的初始化状态是 RUNNING。换句话说,线程池被一旦被创建,就处于 RUNNING 状态,并且线程池中的任务数为 0!
- SHUTDOWN
- 状态说明:线程池处在 SHUTDOWN 状态时,不接收新任务,但能处理已添加的任务。
- 状态切换:调用线程池的 `shutdown()` 接口时,线程池由 RUNNING -> SHUTDOWN。
- STOP
- 状态说明:线程池处在 STOP 状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
- 状态切换:调用线程池的 `shutdownNow()` 接口时,线程池由(RUNNING or SHUTDOWN) -> STOP。
- TIDYING
- 状态说明:当所有的任务已终止,ctl 记录的”任务数量”为 0,线程池会变为 TIDYING 状态。当线程池变为 TIDYING 状态时,会执行钩子函数 `terminated()`。`terminated()` 在 ThreadPoolExecutor 类中是空的,若用户想在线程池变为 TIDYING 时,进行相应的处理;可以通过重载 `terminated()` 函数来实现。
- 状态切换:当线程池在 SHUTDOWN 状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。当线程池在 STOP 状态下,线程池中执行的任务为空时,就会由 STOP -> TIDYING。
- TERMINATED
- 状态说明:线程池彻底终止,就变成 TERMINATED 状态。
- 状态切换:线程池处在 TIDYING 状态时,执行完 `terminated()` 之后,就会由 TIDYING -> TERMINATED。
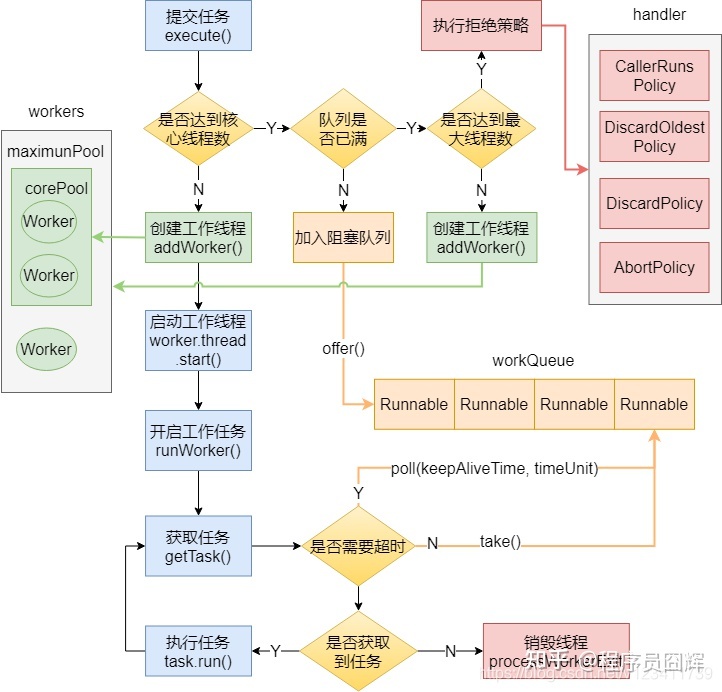
- 提交一个新任务到线程池时,具体的执行流程
1. 当我们提交任务,线程池会根据 corePoolSize 大小创建若干任务数量线程执行任务
2. 当任务的数量超过 corePoolSize 数量,后续的任务将会进入阻塞队列阻塞排队
3. 当阻塞队列也满了之后,那么将会继续创建 `(maximumPoolSize-corePoolSize)` 个数量的线程来执行任务,如果任务处理完成,`maximumPoolSize-corePoolSize` 额外创建的线程等待 keepAliveTime 之后被自动销毁
- **如果使用无界队列**
- 使用了无界队列,会直接导致最大线程数的配置失效。服务端高并发下使用无界的阻塞队列会发生 OOM,把机器打爆。LinkedBlockingQueue 默认的最大任务数量是 Integer.MAX_VALUE,非常大,近乎于可以理解为无限吧。
4. 如果达到 maximumPoolSize,阻塞队列还是满的状态,那么将根据不同的拒绝策略对应处理
- 
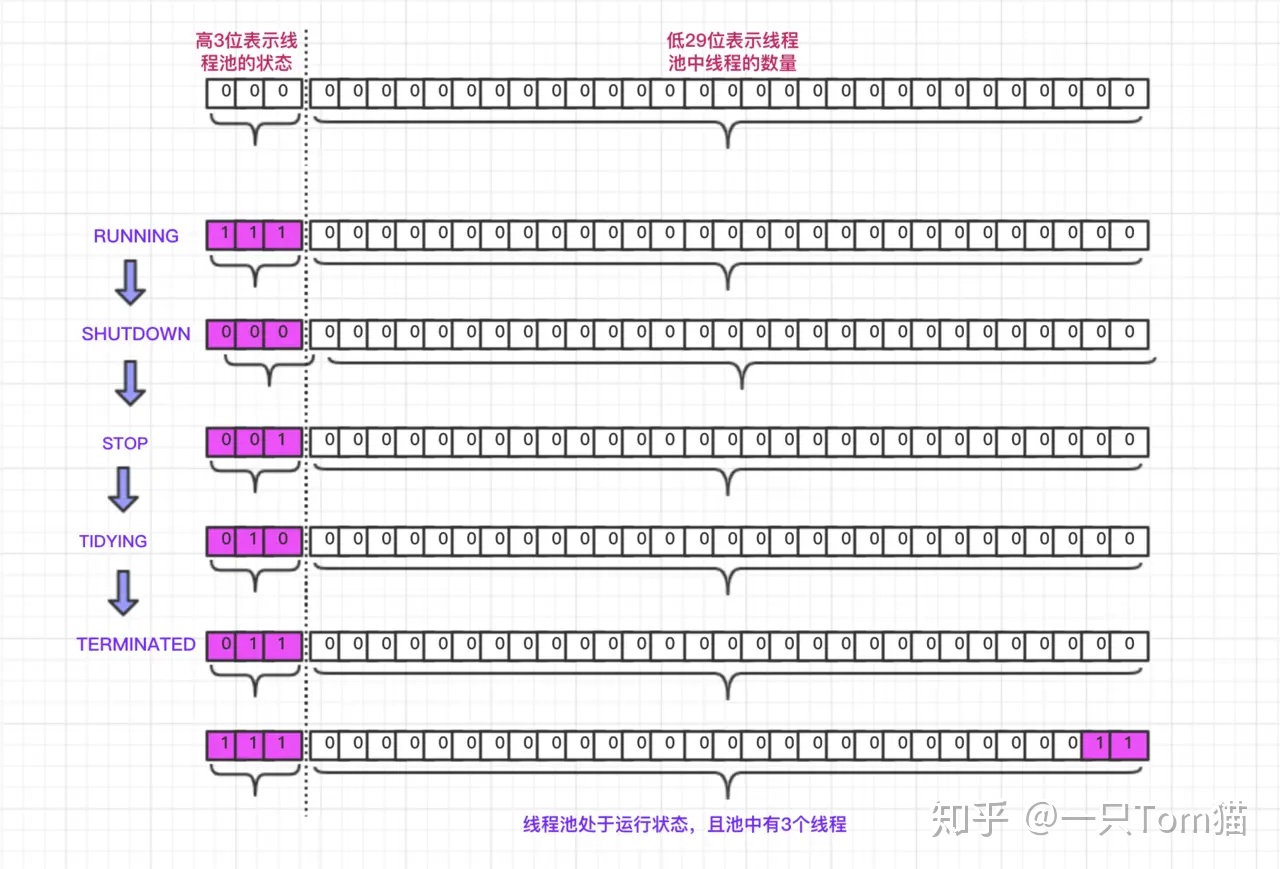
- 原理
- 在线程池中,使用了一个原子类 AtomicInteger 的变量来表示线程池状态和线程数量,该变量在内存中会占用 4 个字节,也就是 32bit,其中高 3 位用来表示线程池的状态,低 29 位用来表示线程的数量。
- 线程池的状态一共有 5 种状态,用 3bit 最多可以表示 8 种状态
- 
- 线程池参数设计
- CPU 密集型任务
- 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。
- 一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务
- 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
- **IO 是否会一直占用CPU?**
- IO 所需要的 CPU 资源非常少。大部分工作是分派给 DMA(Direct Memory Access)完成的。
- 流程
- CPU 计算文件地址 ——> 委派 DMA 读取文件 ——> DMA 接管总线 ——> CPU 的 A 进程阻塞,挂起——> CPU 切换到 B 进程 ——> DMA 读完文件后通知 CPU(一个中断异常)——> CPU 切换回 A 进程操作文件
- 相关问题
- **为什么是先判断任务队列有没有满,再判断线程数有没有超过最大线程数?而不是先判断最大线程数,再判断任务队列是否已满?**
- 案和具体的源码实现有关。因为当需要创建线程的时候,都会调用 `addWorker()` 方法,在 `addWorker()` 的后半部分的逻辑中,会调用 `mainLock.lock()` 方法来获取全局锁,而获取锁就会造成一定的资源争抢。如果先判断最大线程数,再判断任务队列是否已满,这样就会造成线程池原理的 4 个步骤中,第 1 步判断核心线程数时要获取全局锁,第 2 步判断最大线程数时,又要获取全局锁,这样相比于先判断任务队列是否已满,再判断最大线程数,就可能会多出一次获取全局锁的过程。因此在设计线程池,为了尽可能的避免因为获取全局锁而造成资源的争抢,所以会先判断任务队列是否已满,再判断最大线程数。
- **LinkedBlockingQueue 的吞吐量比 ArrayBlockingQueue 的吞吐量要高。前者是基于链表实现的,后者是基于数组实现的,正常情况下,不应该是数组的性能要高于链表吗?**
- 因为 LinkedBlockingQueue 的读和写操作使用了两个锁,takeLock 和 putLock,读写操作不会造成资源的争抢。而 ArrayBlockingQueue 的读和写使用的是同一把锁,读写操作存在锁的竞争。因此 LinkedBlockingQueue 的吞吐量高于 ArrayBlockingQueue。
- **为什么要使用线程池?**
- 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 增加线程的可管理型。线程是稀缺资源,使用线程池可以进行统一分配,调优和监控。
- **线程池为什么能维持线程不释放,随时运行各种任务?**
- 线程池就是用一堆包装住 Thread 的 Wroker 类的集合,在里面有条件的进行着死循环,从而可以不断接受任务来进行。
### 异常
- 基类为 Throwable
- 子类 Error(错误)
- 所有的编译时期的错误以及系统错误都是通过 Error 抛出的。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如 Java 虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java 中,错误通过 Error 的子类描述。
- 常见的 Error
- OutOfMemoryError
- 如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出 OutOfMemoryError异常。
- 具体情况
- OutOfMemoryError: PermGen space
- 在 JDK1.8 之前,方法区放在堆的永久带区(PermGen),方法区内存溢出则报此异常
- OutOfMemoryError: Metaspace
- JDK1.8 及以后的版本使用 Metaspace 来代替永久代,Metaspace 是方法区在 HotSpot 中的实现,它与持久代最大区别在于,Metaspace 并不在虚拟机内存中而是使用本地内存。
- StackOverflowError
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出 StackOverflowError异常。
- 子类 Exception(异常)
- RuntimeException
- 常见的 RuntimeException
- NullPointerException
- ClassNotFoundException
- NumberFormatException
- IndexOutOfBoundsException
- IllegalArgumentException
- ClassCastException
- 非 RuntimeException
- 是 checked exception,需要在代码中处理
- 捕获异常
- finally
- try 关键字最后可以定义 finally 代码块。 finally 块中定义的代码,总是在 try 和任何 catch 块之后、方法完成之前运行。
- 正常情况下,不管是否抛出或捕获异常 finally 块都会执行。
- 使用场景
- 执行关闭连接、关闭文件和释放线程的的操作。
- 相关问题
- **啥时候 finally 不会被执行?**
- 调用 System.exit 函数
- ```
try {
System.out.println("Inside try");
System.exit(1);
} finally {
System.out.println("Inside finally");
} - 调用 halt 函数
- ```
try {
} finally {System.out.println("Inside try"); Runtime.getRuntime().halt(1);
}System.out.println("Inside finally");1
2
3
4
5
6
7
8
9
10
11
12
13
14- 守护线程
- 如果守护线程刚开始执行到 finally 代码块,此时没有任何其他非守护线程,那么虚拟机将退出,此时 JVM 不会等待守护线程的 finally 代码块执行完成。
- try 代码块中无限循环
- 常见陷阱
- 忽视异常
- finally 代码块包含返回语句,没有处理未捕获的异常。
- ```
try {
System.out.println("Inside try");
throw new RuntimeException();
} finally {
System.out.println("Inside finally");
return "from finally";
}
- ```
- 此时,try 代码块中的 RuntimeException 会被忽略,函数返回 “from finally”字符串。
- 覆盖其他返回语句
- 如果 finally 代码块中存在返回语句,则 try 和 catch 代码块如果存在返回语句就会被忽略。
- 改变 throw 或 return 行为
- 如果再 finally 代码块中扔出异常,则 try 和 catch 中的异常扔出或者返回语句都将被忽略。
- ```
try {
} finally {System.out.println("Inside try"); return "from try";
}throw new RuntimeException();1
2
3
4
5
6
7
8- 这段代码永远都不会有返回值,总是会抛出 RuntimeException。
- 执行顺序
- ```
try {
return expression;
} finally {
do some work;
}
- 执行:expression,计算该表达式,结果保存在操作数栈顶;
- 执行:操作数栈顶值(expression 的结果)复制到局部变量区作为返回值;
- 执行:finally 语句块中的代码;
- 执行:将第 2 步复制到局部变量区的返回值又复制回操作数栈顶;
- 执行:return 指令,返回操作数栈顶的值;
- 如果我想共享线程的 ThreadLocal 数据怎么办?
- ThreadLocal 的作用

JNI、JNA
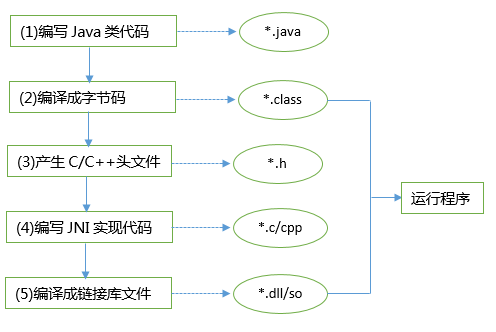
- JNI(Java Native Interface)
- 它允许 Java 代码和其他语言(尤其 C/C++)写的代码进行交互,只要遵守调用约定即可。
- 调用过程
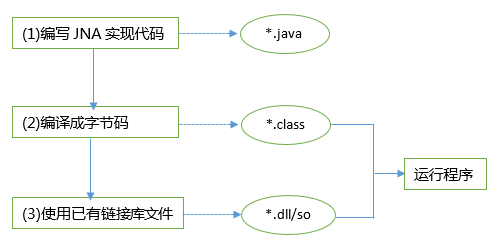
- 缺点
- 调用步骤非常的多,很麻烦,使用 JNI 调用 .dll/.so 共享库都能体会到这个痛苦的过程。如果已有一个编译好的 .dll/.so 文件,如果使用 JNI 技术调用,我们首先需要使用 C 语言另外写一个 .dll/.so 共享库,使用 SUN 规定的数据结构替代 C 语言的数据结构,调用已有的 dll/so 中公布的函数。然后再在 Java 中载入这个库 dll/so,最后编写 Java native 函数作为链接库中函数的代理。经过这些繁琐的步骤才能在 Java 中调用本地代码。因此,很少有 Java 程序员愿意编写调用 dll/.so 库中原生函数的 java 程序。
- JNA(Java Native Access)
- 是一个开源的 Java 框架,是 SUN 公司主导开发的,建立在经典的 JNI 的基础之上的一个框架。
- JNA 大大简化了调用本地方法的过程,使用很方便,基本上不需要脱离 Java 环境就可以完成。
- 调用过程
- 相关问题
- JNA 能完全替代 JNI 吗?
- JNA 是不能完全替代 JNI 的,因为有些需求还是必须求助于 JNI。
- 使用 JNI 技术,不仅可以实现 Java 访问 C 函数,也可以实现 C 语言调用 Java 代码。
- 而 JNA 只能实现 Java 访问 C 函数,作为一个 Java 框架,自然不能实现 C 语言调用 Java 代码。此时,你还是需要使用 JNI 技术。
- JNI 是 JNA 的基础,是 Java 和 C 互操作的技术基础。
- JNA 能完全替代 JNI 吗?
Java 与 C++ 的区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。