概述
数据仓库概念
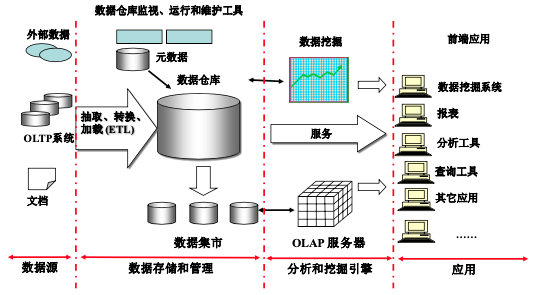
数据仓库的体系结构通常包含四个层次:数据源、数据存储和管理、数据服务、数据应用,具体如下:
- 数据源:是数据仓库的数据来源,包括了外部数据、现有业务系统和文档资料等;
- 数据集成:完成数据的抽取、清洗、转换和加载任务,数据源中的数据采用 ETL 工具以固定的周期加载到数据仓库中;
- 数据存储和管理:这一层次主要涉及对数据的存储和管理,包括数据仓库、数据集市、数据仓库检测、运行与维护工具和元数据管理等;
- 数据服务:为前端工具和应用提供数据服务,可以直接从数据仓库中获取数据供前端应用使用,也可以通过 OLAP(Online Analytical Processing)服务器为前端应用提供更加复杂的数据服务。OLAP 服务器提供了不同聚集粒度的多维数据集合,使得应用不需要直接访问数据仓库中的底层细节数据,大大减少了数据计算量,提高了查询响应速度。OLAP 服务器还支持针对多维数据集的上钻、下探、切片、切块和旋转等操作,增强了多维数据分析能力;
- 数据应用:这一层次直接面向最终用户,包括数据查询工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。
Hive 简介
Hive 是一个构建于 Hadoop 顶层的数据仓库工具,依赖 HDFS 来存储数据,依赖 MapReduce 来处理数据。Hive 定义了简单的类似 SQL 的查询语言 HiveQL,它与大部分 SQL 语法兼容,但是,并不完全支持 SQL 标准,比如,HiveSQL 不支持更新操作,也不支持索引和事务,它的子查询和连接操作也存在很多局限。
Hive 与 Hadoop 生态系统中其他组件的关系
HDFS 作为高可靠的底层存储,用来存储海量数据;MapReduce 对这些海量数据进行批处理,实现高性能计算;Hive 架构在 MapReduce、HDFS 之上,其自身并不存储和处理数据,需要分别借助于 HDFS 和 MapReduce 实现数据的存储和处理,用 HiveQL 语句编写的处理逻辑,最终都要转化为 MapReduce 任务来运行;Pig 可以作为 Hive 的替代工具,是一种数据流语言和运行环境,适合用于在 Hadoop 平台上查询半结构化数据集,常用于 ETL 过程的一部分,即将外部数据装载到 Hadoop 集群中,然后转换为用户需要的数据格式;HBase 是一个面向列的、分布式的、可伸缩的数据库,它可以提供数据的实时访问功能,而 Hive 只能处理静态数据,主要是 BI 报表数据,就设计初衷而言,在 Hadoop 上设计 Hive,是为了减少复杂 MapReduce 应用程序的编写工作,在 Hadoop 上设计 HBase 则是为了实现对数据的实时访问,所以,HBase 与 Hive 的功能是互补的,它实现了 Hive 不能提供的功能。
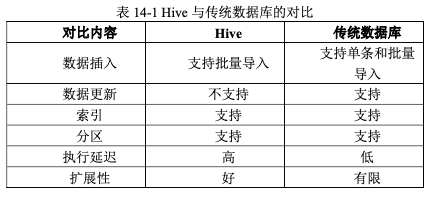
Hive 与传统数据库的对比
Hive 系统架构
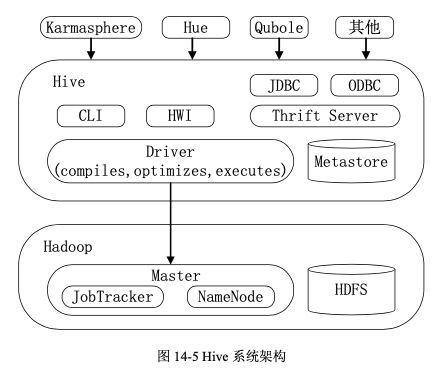
Hive 主要由以下三个模块组成:用户接口模块、驱动模块以及元数据存储模块。
用户接口模块包括 CLI、HWI、JDBC、ODBC、Thrift Server 等,用来实现外部应用对 Hive 的访问。
- CLI 是 Hive 自带的一个命令行界面
- HWI 是 Hive 的一个简单网页界面
- JDBC、ODBC 以及 Thrift Server 可以向用户提供进行编程访问的接口
- Thrift Server 是基于 Thrift 软件框架开发的,它提供 Hive 的 RPC 通信接口
驱动模块(Driver)包括编译器、优化器、执行器等,负责把 HiveSQL 语句转换成一系列 MapReduce 作业,所有命令和查询都会进入到驱动模块,通过该模块对输入进行解析编译,对计算过程进行优化,然后按照指定的步骤执行。
元数据存储模块(Metastore)是一个独立的关系型数据库,通常是与 MySQL 数据库连接后创建的一个 MySQL 实例,也可以是 Hive 自带的 derby 数据库实例。元数据存储模块中主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
Hive 工作原理
Hive 可以快速实现简单的 MapReduce 统计,主要是通过自身组件把 HiveQL 语句转换成 MapReduce 任务来实现的。
SQL 语句转换成 MapReduce 作业的基本原理
用 MapReduce 实现连接操作
假设参与连接(join)的两个表分别为用户表 User 和订单表 Order,User 表有两个属性,即 uid 和 name,Order 表也有两个属性,即 uid 和 orderid,它们的连接键为公共属性 uid。这里对两个表执行连接操作,得到用户的订单号与用户名的对应关系,具体的 SQL 语句命令如下:select name, orderid from user u join order o on u.uid=o.uid;
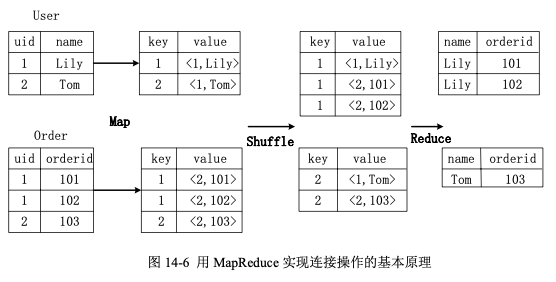
首先,在 Map 阶段, User 表以 uid 为键(key),以 name 和表的标记位(这里 User 的标记位记为 1)为值(value)进行 Map 操作,把表中记录转化成生成一系列键值对的形式。同样地,Order 表以 uid 为键,以 orderid 和表的标记位(这里表 Order 的标记位记为 2)为值进行 Map 操作,把表中 记录转化成生成一系列键值对的形式。比如,User 表中记录 (1,Lily) 转化为键值对 (1,<1,Lily>),其中,括号中的第一个“1”是 uid 的值,第二个“1”是表 User 的标记位,用来标识这个键值对来自 User 表;再比如,Order 表中记录 (1,101) 转化为键值对 (1,<2,101>),其中,“2”是表 Order 的标记位,用来标识这个键值对来自 Order 表。
接着,在 Shuffle 阶段,把 User 表和 Order 表生成的键值对按键值进行哈希,然后传送给对应的 Reduce 机器执行,比如键值对 (1,<1,Lily>)、(1,<2,101>) 和 (1,<2,102>) 传送到同一台 Reduce 机器上,键值对 (2,<1,Tom>) 和 (2,<2,103>) 传送到另一台 Reduce 机器上。当 Reduce 机器接收这些键值对时,还需要按表的标记位对这些键值对进行排序,以优化连接操作。
最后,在 Reduce 阶段,对同一台 Reduce 机器上的键值对,根据“值”(value)中的表标记位,对来自 User 和 Order 这两个表的数据进行笛卡尔积连接操作,以生成最终的连接结果。比如,键值对 (1,<1,Lily>) 与键值对 (1,<2,101>) 和 (1,<2,102>) 的连接结果分别为 (Lily ,101>) 和 (Lily, 102),键值对 (2,<1,Tom>) 和键值对 (2,<2,103>) 的连接结果为 (Tom, 103)。
用 MapReduce 实现分组操作
假设分数表 Score 具有两个属性,即 rank(排名)和 level(级别),这里存在一个分组(Group By)操作,其功能是把表 Score 的不同片段按照 rank 和 level 的组合值进行合并,计算不同 rank 和 level 的组合值分别有几条记录。具体的 SQL 语句命令如下:select rank, level ,count(*) as value from score group by rank, level;
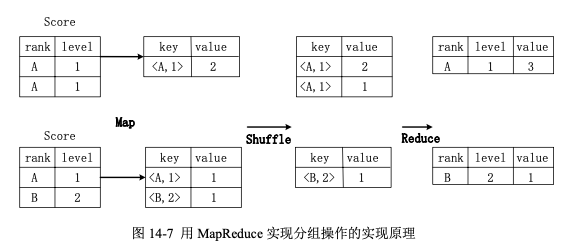
首先,在 Map 阶段,对表 Score 进行 Map 操作,生成一系列键值对,对于每个键值对,其键为 <rank,level>,值为“拥有该 <rank,value> 组合值的记录的条数”。比如,Score 表的第一片段中有两条记录 (A,1),所以,记录 (A,1) 转化为键值对 (<A,1>,2),Score 表的第二片段中只有一条记录 (A,1),所以,记录 (A,1) 转化为键值对 (<A,1>,1)。
接着,在 Shuffle 阶段,对 Score 表生成的键值对,按照“键”的值进行哈希,然后根据哈希结果传送给对应的 Reduce 机器去执行,比如键值 对 (<A,1>,2) 和 (<A,1>,1) 传送到同一台 Reduce 机器上,键值对 (<B,2>,1) 传送到另一台 Reduce 机器上。然后,Reduce 机器对接收到的这些键值对,按“键”的值进行排序。
最后,在 Reduce 阶段,对于 Reduce 机器上的这些键值对,把具有相同键的所有键值对的“值”进行累加,生成分组的最终结果,比如,在同一台 Reduce 机器上的键值对 (<A,1>,2) 和 (<A,1>,1>) Reduce 后的输出结果为 (<A,1>,3),(<B,2>,1) 的 Reduce 后的输出结果为 (<B,2>,1)。
Hive 中 SQL 查询转换成 MapReduce 作业的过程
当用户向 Hive 输入一段命令或查询(即 HiveQL 语句)时,Hive 需要与 Hadoop 交互工作来完成该操作。该命令或查询首先进入到驱动模块,由驱动模块中的编译器进行解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行。执行器通常的任务是启动一个或多个 MapReduce 任务,有时也不需要启动 MapReduce 任务,比如,执行包含 * 的操作时(如 select * from 表),就是全表扫描,选择所有的属性和所有的元组,不存在投影和选择操作,因此,不需要执行 Map 和 Reduce 操作。
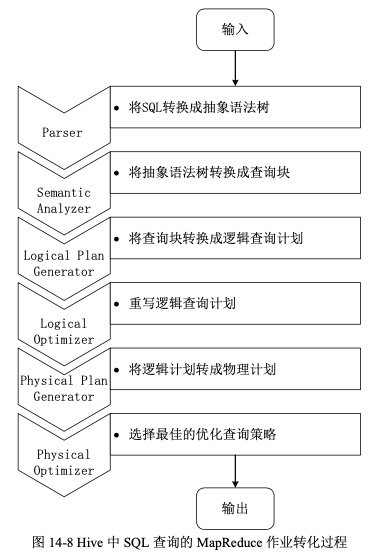
在 Hive 中,用户通过命令行 CLI 或其他 Hive 访问工具,向 Hive 输入一段命令或查询以后,SQL 查询被 Hive 自动转化为 MapReduce 作业,具体步骤如下:
- 由 Hive 驱动模块中的编译器——Antlr 语言识别工具,对用户输入的 SQL 语言进行词法和语法解析,将 SQL 语句转化为抽象语法树(AST Tree)的形式;
- 对该抽象语法树进行遍历,进一步转化成 QueryBlock 查询单元。因为抽象语法树的结构仍很复杂,不方便直接翻译为 MapReduce 算法程序,所以,Hive 把抽象语法树进一步转化为 QueryBlock,其中,QueryBlock 是一条最基本的 SQL 语法组成单元,包括输入源、计算过程和输出三个部分;
- 再对 QueryBlock 进行遍历,生成 OperatorTree(操作树)。其中,OperatorTree 由很多逻辑操作符组成,如 TableScanOperator、SelectOperator、FilterOperator、JoinOperator、 GroupByOperator 和 ReduceSinkOperator 等。这些逻辑操作符可以在 Map 阶段和 Reduce 阶 段完成某一特定操作;
- 通过 Hive 驱动模块中的逻辑优化器对 OperatorTree 进行优化,变换 OperatorTree 的形式,合并多余的操作符,从而减少 MapReduce 任务数量以及 Shuffle 阶段的数据量;
- 对优化后的 OperatorTree 进行遍历,根据 OperatorTree 中的逻辑操作符生成需要执行的 MapReduce 任务;
- 启动 Hive 驱动模块中的物理优化器,对生成的 MapReduce 任务进行优化,生成最终的 MapReduce 任务执行计划;
- 最后由 Hive 驱动模块中的执行器,对最终的 MapReduce 任务进行执行输出。
需要说明的是,Hive 驱动模块中的执行器执行最终的 MapReduce 任务时,Hive 本身是不会生成 MapReduce 算法程序的,它需要通过一个表示“Job 执行计划”的 XML 文件,来驱动执行内置的、原生的 Mapper 和 Reducer 模块。Hive 通过和 JobTracker 通信来初始化 MapReduce 任务,而不需要直接部署在 JobTracker 所在的管理节点上执行。通常在大型集群上,会有专门的网关机来部署 Hive 工具。这些网关机的作用主要是远程操作和管理节点上的 JobTracker 通信来执行任务。Hive 要处理的数据文件通常存储在 HDFS 上,HDFS 由名称节点(NameNode)来管理。
Hive HA 基本原理
Hive 的功能十分强大,可以支持采用 SQL 方式查询 Hadoop 平台上的数据,但是,在实际应用中,Hive 也暴露出不稳定的问题,在极少数情况下,甚至会出现端口不响应或者进程丢失的问题。Hive HA(High Availability)的出现,就是为了解决这类问题。
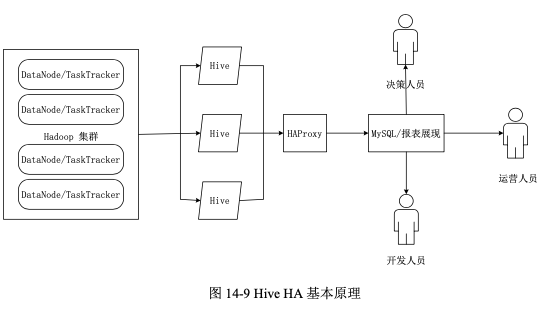
在 Hive HA 中,在 Hadoop 集群上构建的数据仓库是由多个 Hive 实例进行管理的,这些 Hive 实例被纳入到一个资源池中,并由 HAProxy 提供一个统一的对外接口。客户端的查询请求首先访问 HAProxy,由 HAProxy 对访问请求进行转发。HAProxy 收到请求后,会轮询资源池里可用的 Hive 实例,执行逻辑可用性测试,如果某个 Hive 实例逻辑可用,就会把客户端的访问请求转发到该 Hive 实例上,如果该 Hive 实例逻辑不可用,就把它放入黑名单,并继续从资源池中取出下一个 Hive 实例进行逻辑可用性测试。对于黑名单中的 Hive 实例,HiveHA 会每隔一段时间进行统一处理,首先尝试重启该 Hive 实例,如果重启成功,就再次把它放入到资源池中。由于采用 HAProxy 提供统一的对外访问接口,因此,对于程序开发人员来说,可以把它认为是一台超强“Hive”。