Hadoop 的优化与发展
Hadoop 的局限与不足
Hadoop1.0 的核心组件(仅指 MapReduce 和 HDFS,不包括 Hadoop 生态系统内的 Pig、Hive、HBase 等其他组件)主要存在以下不足。
- 抽象层次低。需要手工编写代码来完成,有时只是为了实现一个简单的功能,也需要编写大量的代码。
- 表达能力有限。MapReduce 把复杂分布式编程工作高度抽象到两个函数上,即 Map 和 Reduce,在降低开发人员程序开发复杂度的同时,却也带来了表达能力有限的问题,实际生产环境中的一些应用是无法用简单的 Map 和 Reduce 来完成的。
- 开发者自己管理作业之间的依赖关系。一个作业(Job)只包含 Map 和 Reduce 两个阶段,通常的实际应用问题需要大量的作业进行协作才能顺利解决,这些作业之间往往存在复杂的依赖关系,但是 MapReduce 框架本身并没有提供相关的机制对这些依赖关系进行有效管理,只能由开发者自己管理。
- 难以看到程序整体逻辑。用户的处理逻辑都隐藏在代码细节中,没有更高层次的抽象机制对程序整体逻辑进行设计,这就给代码理解和后期维护带来了障碍。
- 执行迭代操作效率低。对于一些大型的机器学习、数据挖掘任务,往往需要多轮迭代才能得到结果。采用 MapReduce 实现这些算法时,每次迭代都是一次执行 Map、Reduce 任务的过程,这个过程的数据来自分布式文件系统 HDFS,本次迭代的处理结果也被存放到 HDFS 中,继续用于下一次迭代过程。反复读写 HDFS 文件中的数据,大大降低了迭代操作的效率。
- 资源浪费。在 MapReduce 框架设计中,Reduce 任务需要等待所有 Map 任务都完成后才可以开始,造成了不必要的资源浪费。
- 实时性差。只适用于离线批数据处理,无法支持交互式数据处理、实时数据处理。
针对 Hadoop 的改进与提升


HDFS2.0 的新特性
相对于之前的 HDFS1.0 而言,HDFS2.0 增加了 HDFS HA 和 HDFS 联邦等新特性。
HDFS HA
对于分布式文件系统 HDFS 而言,名称节点(NameNode)是系统的核心节点,存储了各类元数据信息,并负责管理文件系统的命名空间和客户端对文件的访问。但是,在 HDFS1.0 中,只存在一个名称节点,一旦这个唯一的名称节点发生故障,就会导致整个集群变得不可用,这就是常说的“单点故障问题”。虽然 HDFS1.0 中存在一个“第二名称节点(Secondary NameNode)”,但是第二名称节点并不是名称节点的备用节点,它与名称节点有着不同的职责,其主要功能是周期性地从名称节点获取命名空间镜像文件(FsImage)和修改日志(EditLog),进行合并后再发送给名称节点,替换掉原来的 FsImage,以防止日志文件 EditLog 过大,导致名称节点失败恢复时消
耗过多时间。合并后的命名空间镜像文件 FsImage 在第二名称节点中也保存一份,当名称节点失效的时候,可以使用第二名称节点中的 FsImage 进行恢复。
由于第二名称节点无法提供“热备份”功能,即在名称节点发生故障的时候,系统无法实时切换到第二名称节点立即对外提供服务,仍然需要进行停机恢复,因此 HDFS1.0 的设计是存在单点故障问题的。为了解决单点故障问题,HDFS2.0 采用了 HA(High Availability)架构。在一个典型的 HA 集群中,一般设置两个名称节点,其中一个名称节点处于“活跃(Active)”状态,另一个处于“待命(Standby)”状态。处于活跃状态的名称节点负责对外处理所有客户端的请求,而处于待命状态的名称节点则作为备用节点,保存了足够多的系统元数据,当名称节点出现故障时提供快速恢复能力。也就是说,在 HDFS HA 中,处于待命状态的名称节点提供了“热备份”,一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,不会影响到系统的正常对外服务。
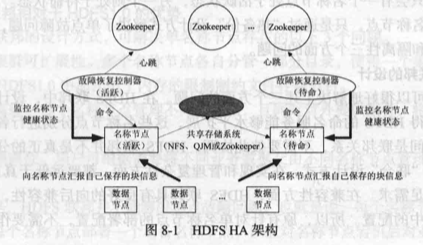
由于待命名称节点是活跃名称节点的“热备份”,因此活跃名称节点的状态信息必须实时同步到待命名称节点。两种名称节点的状态同步,可以借助于一个共享存储系统来实现,比如 NFS(Network File Systerm)、QJM(Quorum Jourmal Manager)或者 Zookeeper。活跃名称节点将更新数据写人到共享存储系统,待命名称节点会一直监听该系统,一旦发现有新的写人,就立即从公共存储系统中读取这些数据并加载到自己的内存中,从而保证与活跃名称节点状态完全同步。
此外,名称节点中保存了数据块(Block)到实际存储位置的映射信息,即每个数据块是由哪个数据节点存储的。当一个数据节点加入 HDFS 集群时,它会把自己所包含的数据块列表报告给名称节点,此后会通过“心跳”的方式定期执行这种告知操作,以确保名称节点的块映射是最新的。因此,为了实现故障时的快速切换,必须保证待命名称节点一直包含最新的集群中各个块的位置信息。为了做到这一点,需要给数据节点配置两个名称节点的地址(即活跃名称节点和待命名称节点),并把块的位置信息和心跳信息同时发送到这两个名称节点。为了防止出现“两个管家”现象,HA 还要保证任何时刻都只有一个名称节点处于活跃状态,否则,如果有两个名称节点处于活跃状态,HDFS 集群中出现“两个管家”,就会导致数据丢失或者其他异常,这个任务是由 Zookeeper 来实现的,Zookeeper 可以确保任意时刻只有一个名称节点提供对外服务。
HDFS 联邦
HDFS1.0 中存在的问题
HDFS1.0 采用单名称节点的设计,不仅会带来单点故障问题,还存在可扩展性、性能和隔离性等问题。在可扩展性方面,名称节点把整个 HDFS 文件系统中的元数据信息都保存在自己的内存中,HDFS1.0 中只有一个名称节点,不可以水平扩展,而单个名称节点的内存空间是有上限的,这限制了系统中数据块、文件和目录的数目。是否可以通过纵向扩展的方式(即为单个名称节点增加更多的 CPU、内存等资源)解决这个问题呢?答案是否定的。纵向扩展带来的第一个问题就是,会带来过长的系统启动时间,比如一个具有 50 GB 内存的 HDFS 启动一次大概需要消耗 30min~2h,单纯增大内存空间只会让系统启动时间变得更长。其次,当在内存空间清理时发生错误,就会导致整个 HDFS 集群宕机。
在系统整体性能方面,整个 HDFS 文件系统的性能会受限于单个名称节点的吞吐量。在隔离性方面,单个名称节点难以提供不同程序之间的隔离性,一个程序可能会影响其他运行的程序(比如一个程序消耗过多资源导致其他程序无法顺利运行)。HDFS HA 虽然提供了两个名称节点,但是在某个时刻也只会有一个名称节点处于活跃状态,另个则处于待命状态。因而,HDFS HA 在本质上还是单名称节点,只是通过“热备份”设计方式解决了单点故障问题,并没有解决可扩展性、系统性能和隔离性三个方面的问题。
HDFS 联邦的设计
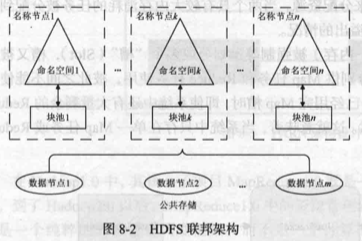
HDFS 联邦可以很好地解决上述三个方面的问题。在 HDFS 联邦中,设计了多个相互独立的名称节点,使得 HDFS 的命名服务能够水平扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联邦关系,不需要彼此协调。HDFS 联邦并不是真正的分布式设计,但是采用这种简单的“联合”设计方式,在实现和管理复杂性方面,都要远低于真正的分布式设计,而且可以快速满足需求。在兼容性方面,HDFS 联邦具有良好的向后兼容性,可以无缝地支持单名称节点架构中的配置。所以,原有针对单名称节点的部署配置,不需要作任何修改就可以继续工作。
HDFS 联邦中的名称节点提供了命名空间和块管理功能。在 HDFS 联邦中,所有名称节点会共享底层的数据节点存储资源。每个数据节点要向集群中所有的名称节点注册,并周期性地向名称节点发送“心跳”和块信息,报告自已的状态,同时也会处理来自名称节点的指令。
HDFS1.0 只有一个命名空间,这个命名空间使用底层数据节点全部的块。与 HDFS1.0 不同的是,HDFS 联邦拥有多个独立的命名空间,其中,每一个命名空间管理属于自己的一组块,这些属于同一个命名空间的块构成一个“块池”(Block Pool)。每个数据节点会为多个块池提供块的存储。可以看出,数据节点是一个物理概念,而块池则属于逻辑概念,一个块池是一组块的逻辑集合,块池中的各个块实际上是存储在各个不同的数据节点中的。因此,HDFS 联邦中的一个名称节点失效,也不会影响到与它相关的数据节点继续为其他名称节点提供服务。
HDFS 联邦的访问方式
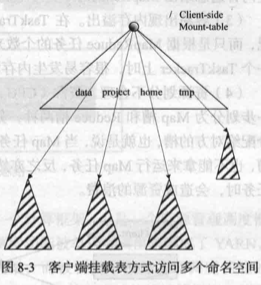
对于 HDFS 联邦中的多个命名空间,可以采用客户端挂载表(Client Side Mount Table)方式进行数据共享和访问。每个阴影三角形代表一个独立的命名空间,上方空白三角形表示从客户方向去访问下面子命名空间。客户可以访问不同的挂载点来访问不同的子命名空间。这就是 HDFS 联邦中命名空间管理的基本原理,即把各个命名空间挂载到全局“挂载表”(Mount-table)中,实现数据全局共享;同样地,命名空间挂载到个人的挂载表中,就成为应用程序可见的命名空间。
HDFS 联邦相对于 HDFS1.0 的优势
采用 HDFS 联邦的设计方式,可解决单名称节点存在的以下 3 个问题。
- HDFS 集群可扩展性。多个名称节点各自分管一部分目录,使得个集群可以扩展到更多节点,不再像 HDFS1.0 中那样由于内存的限制制约文件存储数目。
- 性能更高效。多个名称节点管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
- 良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点管理,这样不同业务之间影响很小。
需要注意的是,HDFS 联邦并不能解决单点故障问题,也就是说,每个名称节点都存在单点故障问题,需要为每个名称节点部署一个后备名称节点,以应对名称节点宕机后对业务产生的影响。
新一代资源管理调度框架 YARN
MapReduce1.0 的缺陷
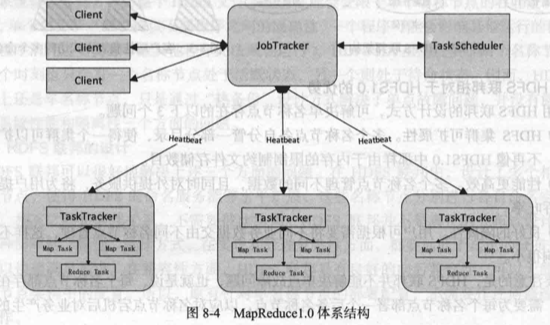
MapReduce1.0 采用 Master/Slave 架构设计,包括二个 JobTracker 和若干个 TaskTracker,前者负责作业的调度和资源的管理,后者负责执行 JobTracker 指派的具体任务。这种架构设计具有一些很难克服的缺陷,具体如下。
- 存在单点故障。由 JobTracker 负责所有 MapReduce 作业的调度,而系统中只有一个 JobTracker,因此会存在单点故障问题,即这个唯一的 JobTracker 出现故障就会导致系统不可用。
- JobTracker“大包大揽”导致任务过重。JobTracker 既要负责作业的调度和失败恢复,又要负责资源管理分配。执行过多的任务,需要消耗大量的资源,例如,当存在非常多的 MapReduce 任务时,JobTracker 需要巨大的内存开销,这也潜在地增加了 JobTracker 失败的风险。正因如此,业内普遍总结出 MapReduce1.0 支持主机数目的上限为 4000 个。
- 容易出现内存溢出。在 TaskTracker 端,资源的分配并不考虑 CPU、内存的实际使用情况,而只是根据 MapReduce 任务的个数来分配资源,当两个具有较大内存消耗的任务被分配到同一个 TaskTracker 上时,很容易发生内存溢出的情况。
- 资源划分不合理。资源(CPU、内存)被强制等量划分成多个“槽”(Slot),槽又被进一步划分为 Map 槽和 Reduce 槽两种,分别供 Map 任务和 Reduce 任务使用,彼此之间不能使用分配给对方的槽,也就是说,当 Map 任务已经用完 Map 槽时,即使系统中还有大量剩余的 Reduce 槽,也不能拿来运行 Map 任务,反之亦然。这就意味着,当系统中只存在单一 Map 任务或 Reduce 任务时,会造成资源的浪费。
YARN 设计思路
为了克服 MapReduce1.0 版本的缺陷,Hadoop2.0 以后的版本对其核心子项目 MapReduce1.0 的体系结构进行了重新设计,生成了 MapReduce2.0 和 YARN(Yet Another Resource Negotiator)。YARN 架构设计基本思路就是“放权”,即不让 JobTracker 这一个组件承担过多的功能,把原 JobTracker 三大功能(资源管理、任务调度和任务监控)进行拆分,分别交给不同的新组件去处理。重新设计后得到的 YARN 包括 ResourceManager 、ApplicationMaster 和 NodeManager,其中,由 ResourceManager 负责资源管理,由 ApplicationMaster 负责任务调度和监控,由 NodeManager 负责执行原 TaskTracker 的任务。通过这种“放权”的设计,大大降低了 JobTracker 的负担,提升了系统运行的效率和稳定性。
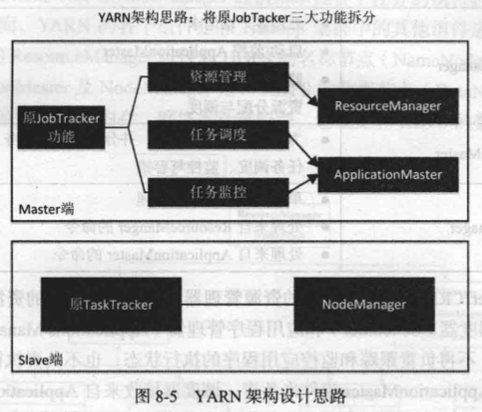
在 Hadoop1.0 中,其核心子项目 MapReduce1.0 既是一个计算框架,也是一个资源管理调度框架。到了 Hadoop2.0 以后,MapReduce1.0 中的资源管理调度功能被单独分离出来形成了 YARN,它是一个纯粹的资源管理调度框架,而不是一个计算框架;而被剥离了资源管理调度功能的 MapReduce 框架就变成了 MapReduce2.0,它是运行在 YARN 之上的一个纯粹的计算框架,不再自己负责资源调度管理服务,而是由 YARN 为其提供资源管理调度服务。
YARN 体系架构
YARN 体系结构中包含了三个组件:ResourceManager、ApplicationMaster 和 NodeManager。
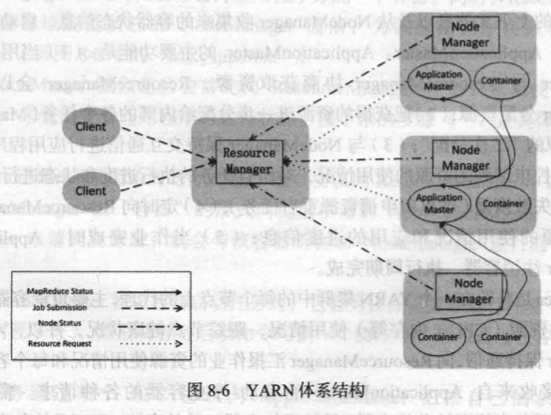
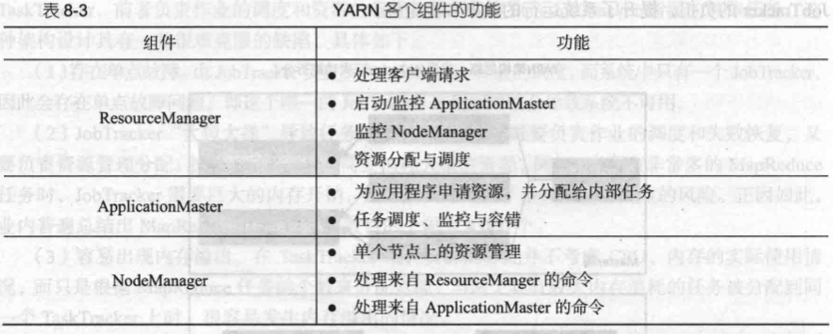
ResourceManager(RM)是一个全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)。调度器主要负责资源管理和分配,不再负责跟踪和监控应用程序的执行状态,也不负责执行失败恢复,因为这些任务都已经交给 ApplicationMaster 组件来负责。调度器接收来自 ApplicationMaster 的应用程序资源请求,并根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择,从而实现“计算向数据靠拢”。在 MapReduce1.0 中,资源分配的单位是“槽”,而在 YARN 中是以容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的 CPU、内存、磁盘等资源,从而限定每个应用程序可以使用的资源量。同时,在 YARN 中调度器被设计成是一个可插拔的组件,YARN 不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器。应用程序管理器负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动 ApplicationMaster、 监控 ApplicationMaster 运行状态并在失败时重新启动等。
在 Hadoop 平台上,用户的应用程序是以作业(Job)的形式提交的,然后一个作业会被分解成多个任务(包括 Map 任务和 Reduce 任务)进行分布式执行。ResourceManager 接收用户提交的作业,按照作业的上下文信息以及从 NodeManager 收集来的容器状态信息,启动调度过程,为用户作业启动一个 ApplicationMaster。
ApplicationMaster 的主要功能是:
- 当用户作业提交时,ApplicationMaster 与 ResourceManager 协商获取资源,ResourceManager 会以容器的形式为 ApplicationMaster 分配资源;
- 把获得的资源进步分配给内部的各个任务(Map 任务或 Reduce 任务),实现资源的“二次分配”;
- 与 NodeManager 保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务);
- 定时向 ResourceManager 发送“心跳”消息,报告资源的使用情况和应用的进度信息;
- 当作业完成时,ApplicationMaster 向 ResourceManager 注销容器,执行周期完成。
NodeManager 是驻留在一个 YARN 集群中的每个节点上的代理,主要负责容器生命周期管理,监控每个容器的资源(CPU、内存等)使用情况,跟踪节点健康状况,并以“心跳”的方式与 ResourceManager 保持通信,向 ResourceManager 汇报作业的资源使用情况和每个容器的运行状态,同时,它还要接收来自 ApplicationMaster 的启动/停止容器的各种请求。需要说明的是,NodeManager 主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map 任务或 Reduce 任务)自身状态的管理,因为这些管理工作是由 ApplicationMaster 完成的,ApplicationMaster 会通过不断与 NodeManager 通信来掌握各个任务的执行状态。
在集群部署方面,YARN 的各个组件是和 Hadoop 集群中的其他组件进行统一部署的。YARN 的 ResourceManager 组件和 HDFS 的名称节点(NameNode)部署在一个节点上,YARN 的 ApplicationMaster 及 NodeManager 是和 HDFS 的数据节点(DataNode)部署在一-起的。YARN 中的容器代表了 CPU、内存、网络等计算资源,它也是和 HDFS 的数据节点一起的。
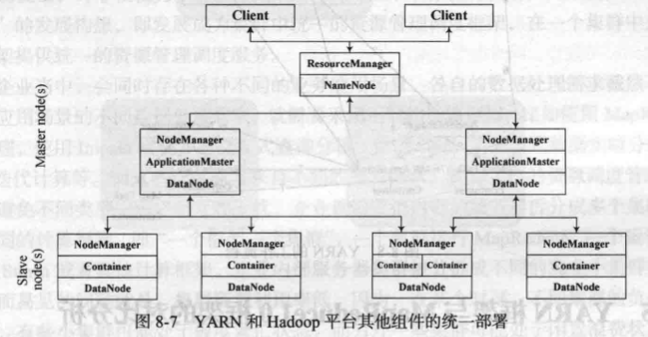
YARN 工作流程
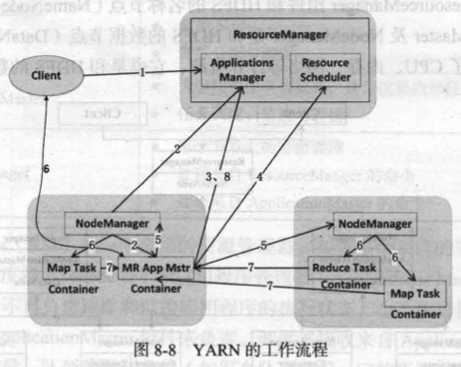
在 YARN 框架中执行一个 MapReduce 程序时,从提交到完成需要经历如下8个步骤。
- 用户编写客户端应用程序,向 YARN 提交应用程序,提交的内容包括 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
- YARN 中的 ResourceManager 负责接收和处理来自客户端的请求。接到客户端应用程序请求后,ResourceManager 里面的调度器会为应用程序分配一个容器。同时,ResourceManager 的应用程序管理器会与该容器所在的 NodeManager 通信,为该应用程序在该容器中启动一个 ApplicationMaster。
- ApplicationMaster 被创建后会首先向 ResourceManager 注册,从而使得用户可以通过 ResourceManager 来直接查看应用程序的运行状态。接下来的步骤4~7是具体的应用程序执行步骤。
- ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请资源。
- ResourceManager 以“容器”的形式向提出申请的 ApplicationMaster 分配资源,一旦 ApplicationMaster 申请到资源后,就会与该容器所在的 NodeManager 进行通信,要求它启动任务。
- 当 ApplicationMaster 要求容器启动任务时,它会为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等),然后将任务启动命令写到一个脚本中,最后通过在容器中运行该脚本来启动任务。
- 各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,让 AplicationMater 可以随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 的应用程序管理器注销并关闭自己。若 ApplicationMaster 因故失败,ResourceManager 中的应用程序管理器会监测到失败的情形,然后将其重新启动,直到所有的任务执行完毕。