转自:https://blog.csdn.net/zzti_erlie/article/details/86355477
极简计算机发展史
我们知道,计算机CPU和内存的交互是最频繁的,内存是我们的高速缓存区。而刚开始用户磁盘和CPU进行交互,CPU运转速度越来越快,磁盘远远跟不上CPU的读写速度,才设计了内存,但是随着CPU的发展,内存的读写速度也远远跟不上CPU的读写速度,因此,为了解决这一纠纷,CPU厂商在每颗CPU上加入了高速缓存,用来缓解这种症状,因此,现在CPU同内存交互就变成了下面的样子。
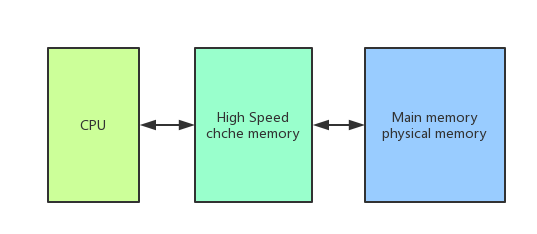
单核CPU的性能不可能无限制的增长,要想很多的提升新能,需要多个处理器协同工作。 基于高速缓存的存储交互很好的解决了处理器与内存之间的矛盾,也引入了新的问题:缓存一致性问题。在多处理器系统中,每个处理器有自己的高速缓存,而他们又共享同一块内存(下文成主存,main memory 主要内存),当多个处理器运算都涉及到同一块内存区域的时候,就有可能发生缓存不一致的现象。为了解决这一问题,需要各个处理器运行时都遵循一些协议,在运行时需要用这些协议保证数据的一致性。
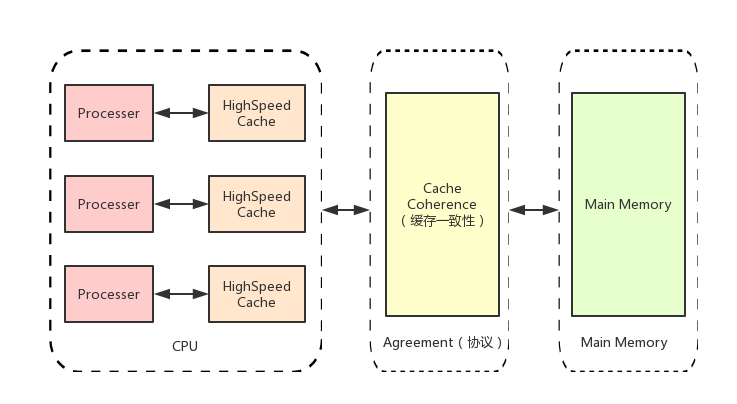
缓存一致性协议中最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存设置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中该变量是无效状态,那么它就会从内存重新读取
Java内存模型
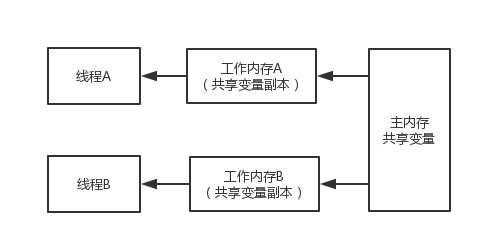
Java的内存模型和上面的结构还是挺相似的,此时在看工作内存和主内存关系,从逻辑上,高速缓存对应工作内存,每个线程分配到CPU时间片时,独自享有高速缓存的使用能力。主内存对应存储的物理内存。特别注意,这只是逻辑上的对等关系,物理的上具体对应关系十分复杂,这里不讨论。
volatile的作用是什么?
volatile可以保证可见性,有序性,但不能保证原子性
可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
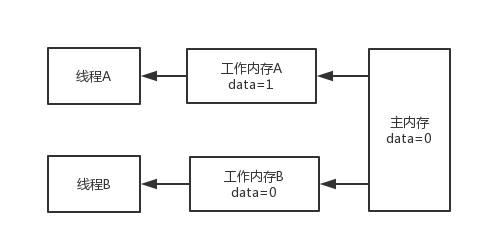
假如说有2个线程对一个变量data进行操作,线程先会把主内存中的值缓存到工作内存,这样做的原因和上面提到的高速缓存类似,提高效率
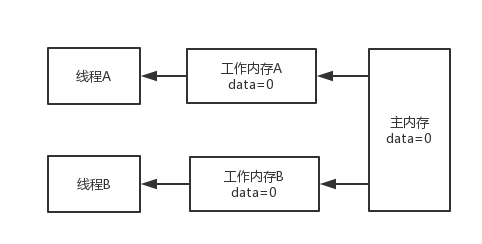
但是这样会引入新的问题,假如说线程A把data修改为1,线程A的工作内存data值为1,但是主内存和线程B的工作内存data值为0,此时就有可能出现Java并发编程中的可见性问题
举个例子,如下面代码,线程A已经将flag的值改变,但是线程B并没有及时的感知到,导致一直进行死循环
1 | public class Test { |
输出为,线程B一直没有结束
1 | threadA end |
但是如果将data定义为如下形式,线程A对data的变更,线程B立马能感知到
1 | public static volatile boolean flag = false; |
输出为
1 | threadA end |
那么是如何实现的呢?其实volatile保证可见性的方式和上面提到的缓存一致性协议的原理很类似
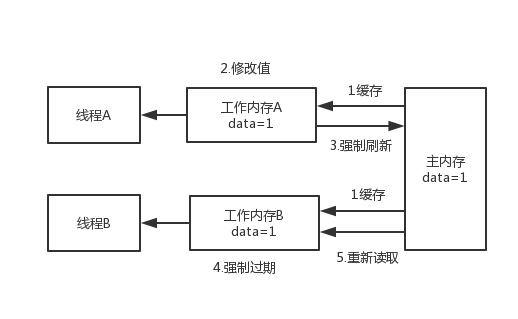
- 线程A将工作内存的data更改后,强制将data值刷回主内存
- 如果线程B的工作内存中有data变量的缓存时,会强制让这个data变量缓存失效
- 当线程B需要读取data变量的值时,先从工作内存中读,发现已经过期,就会从主内存中加载data变量的最新值了
有序性
有序性即程序执行的顺序按照代码的先后顺序执行
1 | int i = 0; |
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是有依赖关系的语句不会进行重排序,如下面求圆面积的代码
1 | double pi = 4.14 //A |
程序的执行顺序只有下面这2个形式:A->B->C和B->A->C,因为A和C之间存在依赖关系,同时B和C之间也存在依赖关系。因此最终执行的指令序列中C不能被重排序到A和B前面。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子
1 | //线程1: |
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性
当写双重检测锁定版本的单例模式时,就要用到volatile来保证可见性
1 | public class Singleton { |
原子性
原子性即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
1 | public class Test { |
执行上述代码结果并不是每次都是5000,表明volatile并不能保证原子
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有5个线程分别进行了1000次操作,那么最终inc的值应该是1000*5=5000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,也不会导致主存中的值刷新,所以线程2会直接去主存读取inc的值(这个部分小编感觉是海子大佬的笔误,应该是线程2会直接去工作内存读取inc的值,因为工作内存中inc并没有失效),发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值(inc++,包括3个操作,1.读取inc的值,2.进行加1操作,3.写入新的值),注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
解决方案:可以通过synchronized或lock,进行加锁,来保证操作的原子性。也可以通过使用AtomicInteger
应用
- 状态标记量
- 单例模式中的double check