- 滑动窗口目标检测
- 缺点:计算成本
评价对象检测算法

一般约定,在计算机检测任务中,如果 $IoU \geq 0.5$,就说检测正确,如果预测器和实际边界框完美重叠,$IoU$ 就是 1,因为交集就等于并集。但一般来说只要 $IoU \geq 0.5$,那么结果是可以接受的,看起来还可以。一般约定,0.5 是阈值,用来判断预测的边界框是否正确。
非极大值抑制(Non-max suppression)
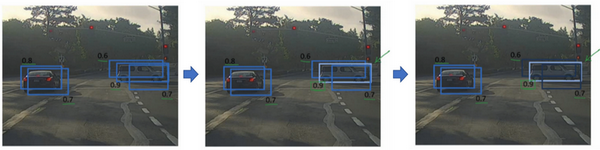
算法可能对同一个对象做出多次检测,所以算法不是对某个对象检测出一次,而是检测出多次。非极大值抑制这个方法可以确保你的算法对每个对象只检测一次。

这个 $p_c$ 检测概率,首先看概率最大的那个,这个例子(右边车辆)中是 0.9,然后就说这是最可靠的检测,所以我们就用高亮标记,就说我这里找到了一辆车。这么做之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比,高度重叠的其他边界框,那么这些输出就会被抑制。所以这两个矩形 $p_c$ 分别是 0.6 和 0.7,这两个矩形和淡蓝色矩形重叠程度很高,所以会被抑制,变暗,表示它们被抑制了。
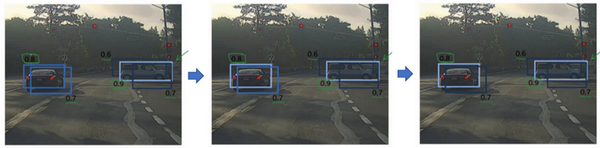
接下来,逐一审视剩下的矩形,找出概率最高,$p_c$ 最高的一个,在这种情况下是 0.8,我们就认为这里检测出一辆车(左边车辆),然后非极大值抑制算法就会去掉其他 $IoU$ 值很高的矩形。所以现在每个矩形都会被高亮显示或者变暗,如果你直接抛弃变暗的矩形,那就剩下高亮显示的那些,这就是最后得到的两个预测结果。

Anchor Boxes
对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用 anchor box 这个概念。
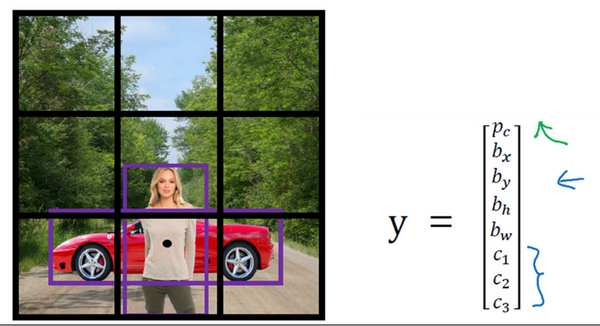
对于这个例子,我们继续使用3×3网格,注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。所以对于那个格子,如果 $y$ 输出这个向量$y= \ \begin{bmatrix} p_{c} \ b_{x} \ b_{y} \ b_{h} \ b_{w} \ c_{1} \ c_{2}\ c_{3} \\end{bmatrix}$,你可以检测这三个类别,行人、汽车和摩托车,它将无法输出检测结果,所以我必须从两个检测结果中选一个。
而anchor box的思路是,这样子,预先定义两个不同形状的anchor box,或者anchor box形状,你要做的是把预测结果和这两个anchor box关联起来。一般来说,你可能会用更多的anchor box,可能要5个甚至更多,但对于这个视频,我们就用两个anchor box,这样介绍起来简单一些。
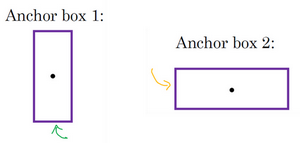
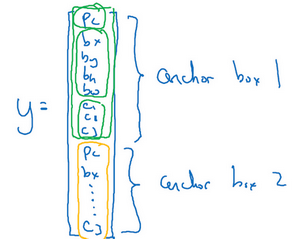
你要做的是定义类别标签,用的向量不再是上面这个$\begin{bmatrix} p_{c} & b_{x} &b_{y} & b_{h} & b_{w} & c_{1} & c_{2} & c_{3} \\end{bmatrix}^{T}$,而是重复两次,$y= \begin{bmatrix} p_{c} & b_{x} & b_{y} &b_{h} & b_{w} & c_{1} & c_{2} & c_{3} & p_{c} & b_{x} & b_{y} & b_{h} & b_{w} &c_{1} & c_{2} & c_{3} \\end{bmatrix}^{T}$,前面的$p_{c},b_{x},b_{y},b_{h},b_{w},c_{1},c_{2},c_{3}$(绿色方框标记的参数)是和anchor box 1关联的8个参数,后面的8个参数(橙色方框标记的元素)是和anchor box 2相关联。因为行人的形状更类似于anchor box 1的形状,而不是anchor box 2的形状,所以你可以用这8个数值(前8个参数),这么编码$p_{c} =1$,是的,代表有个行人,用$b_{x},b_{y},b_{h}$和$b_{w}$来编码包住行人的边界框,然后用$c_{1},c_{2},c_{3}$($c_{1}= 1,c_{2} = 0,c_{3} = 0$)来说明这个对象是个行人。
然后是车子,因为车子的边界框比起anchor box 1更像anchor box 2的形状,你就可以这么编码,这里第二个对象是汽车,然后有这样的边界框等等,这里所有参数都和检测汽车相关($p_{c}= 1,b_{x},b_{y},b_{h},b_{w},c_{1} = 0,c_{2} = 1,c_{3} = 0$)。

总结一下,用anchor box之前,你做的是这个,对于训练集图像中的每个对象,都根据那个对象中点位置分配到对应的格子中,所以输出$y$就是3×3×8,因为是3×3网格,对于每个网格位置,我们有输出向量,包含$p_{c}$,然后边界框参数$b_{x},b_{y},b_{h}$和$b_{w}$,然后$c_{1},c_{2},c_{3}$。
现在用到anchor box这个概念,是这么做的。现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的anchor box中。所以这里有两个anchor box,你就取这个对象,如果你的对象形状是这样的(编号1,红色框),你就看看这两个anchor box,anchor box 1形状是这样(编号2,紫色框),anchor box 2形状是这样(编号3,紫色框),然后你观察哪一个anchor box和实际边界框(编号1,红色框)的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,即(grid cell,anchor box)对,这就是对象在目标标签中的编码方式。所以现在输出 $y$ 就是3×3×16,上一张幻灯片中你们看到 $y$ 现在是16维的,或者你也可以看成是3×3×2×8,因为现在这里有2个anchor box,而 $y$ 是8维的。$y$ 维度是8,因为我们有3个对象类别,如果你有更多对象,那么$y$ 的维度会更高。
YOLO 算法(Putting it together: YOLO algorithm)
候选区域(Region proposals)
滑动窗法,使用训练过的分类器,在这些窗口中全部运行一遍,然后运行一个检测器,看看里面是否有车辆,行人和摩托车。现在也可以运行一下卷积算法,这个算法的其中一个缺点是,它在显然没有任何对象的区域浪费时间。
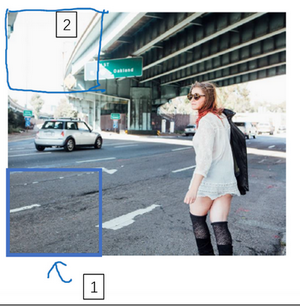
所以这里这个矩形区域(编号1)基本是空的,显然没有什么需要分类的东西。也许算法会在这个矩形上(编号2)运行,而你知道上面没有什么有趣的东西。
R-CNN的算法,意思是带区域的卷积网络,或者说带区域的CNN。这个算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的,所以这里不再针对每个滑动窗运行检测算法,而是只选择一些窗口,在少数窗口上运行卷积网络分类器。
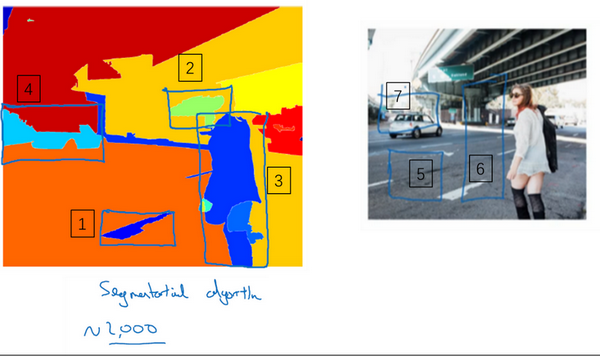
选出候选区域的方法是运行图像分割算法,分割的结果是下边的图像,为了找出可能存在对象的区域。比如说,分割算法在这里得到一个色块,所以你可能会选择这样的边界框(编号1),然后在这个色块上运行分类器,就像这个绿色的东西(编号2),在这里找到一个色块,接下来我们还会在那个矩形上(编号2)运行一次分类器,看看有没有东西。在这种情况下,如果在蓝色色块上(编号3)运行分类器,希望你能检测出一个行人,如果你在青色色块(编号4)上运行算法,也许你可以发现一辆车,我也不确定。