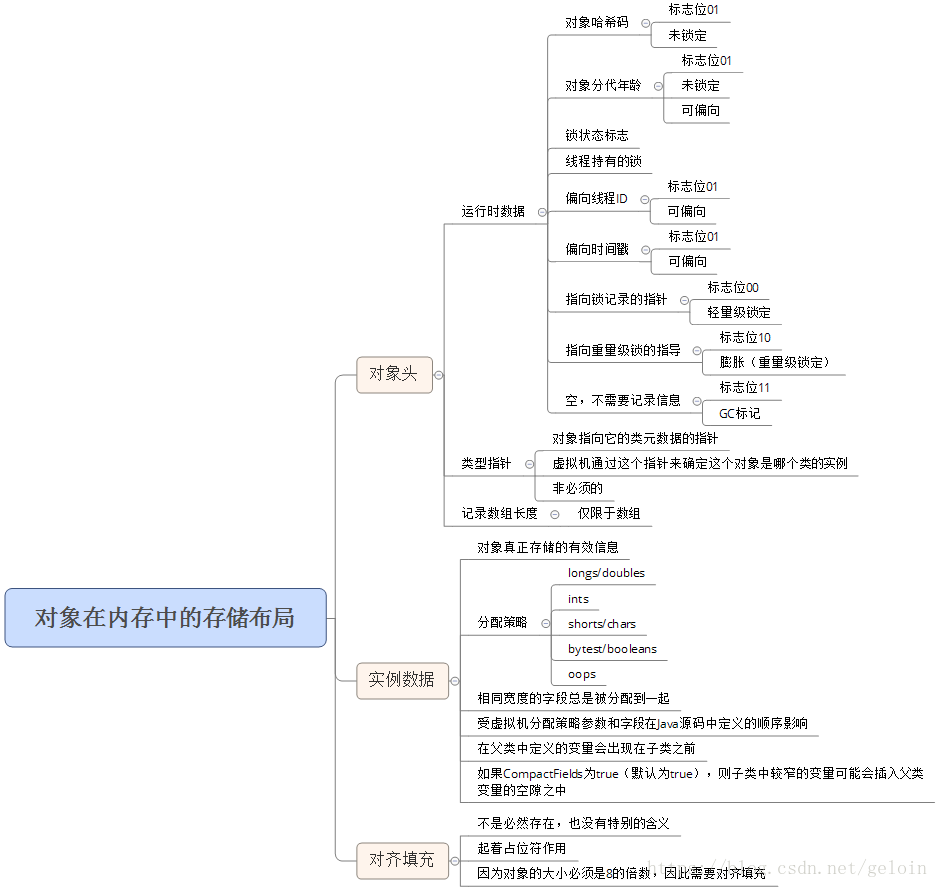
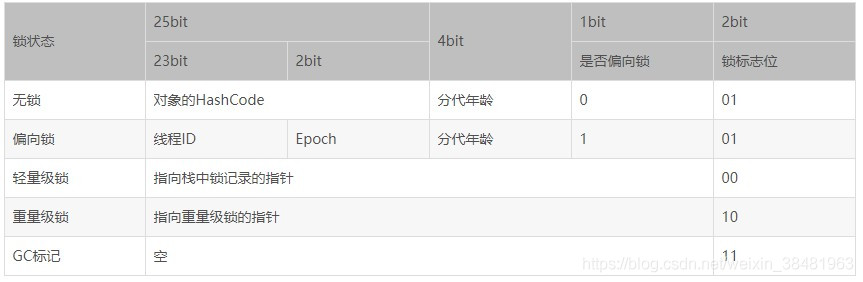
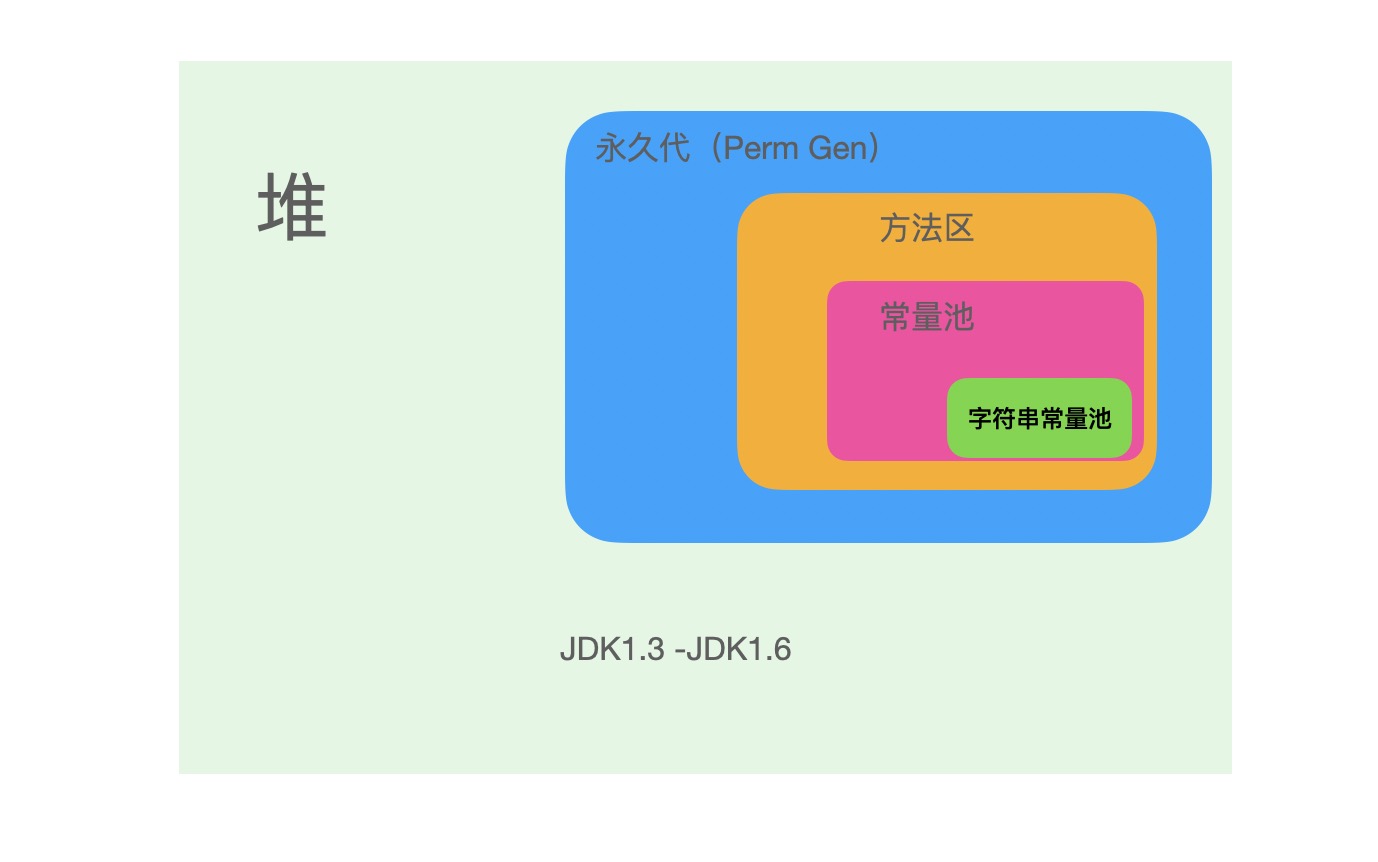
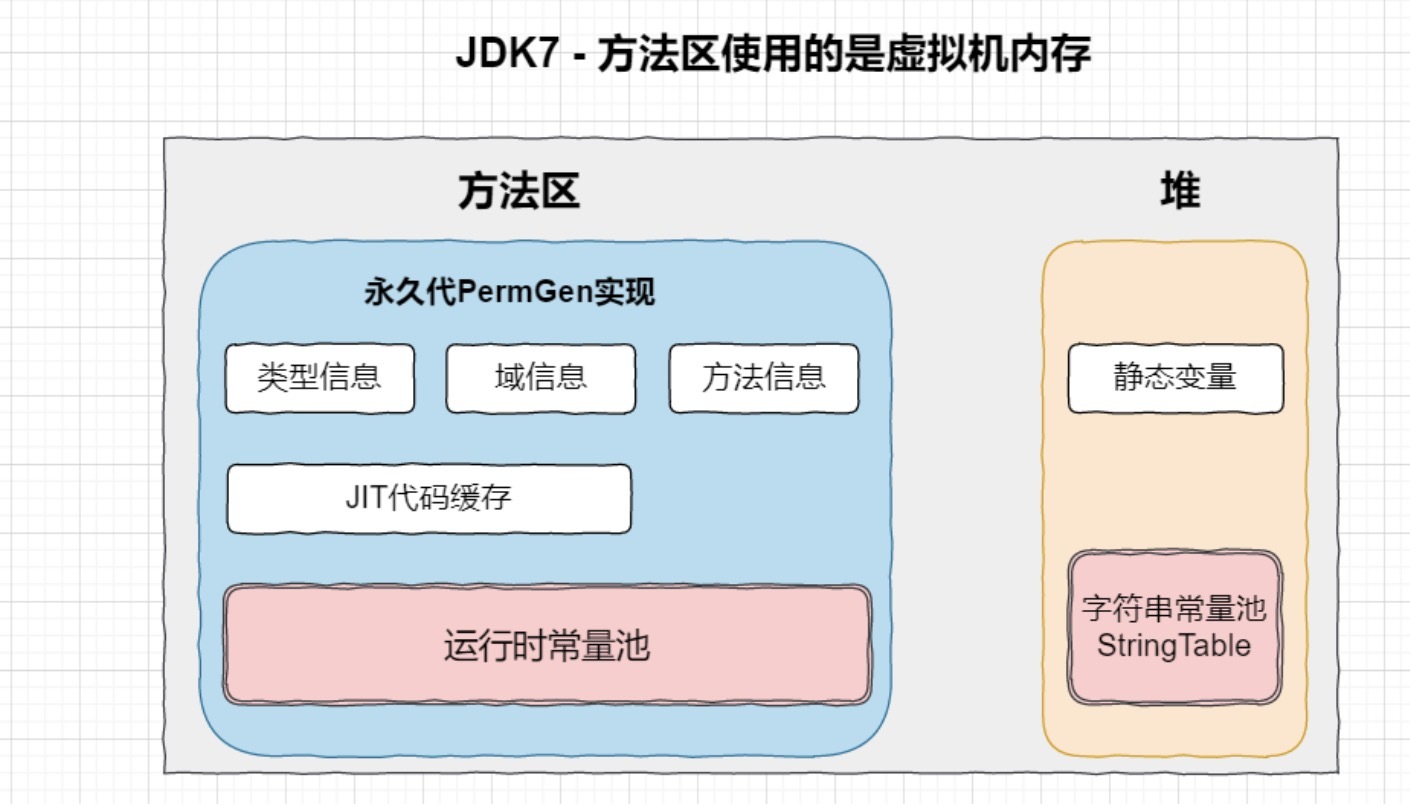
e.g.
这是 exampli gratia(“for example; for instance;such as”: 举例如) 的缩写。
例句1: Buy some vegetables, e.g., carrots.
使用中,不仅e后的“.”常常被漏掉(如写成eg.),而且也经常与下面的缩写混淆。
为了方便记忆,你可把 “e.g.” 与 “example given” 联想起来。
最好把 e.g. 连同它的例子放在括号中,如
例句2:I like quiet activities (e.g., reading)
etc.
这是 et cetera (“and so forth; and the others; and other things; and the rest; and so on”:等等) 的缩写。它放在列表的最后,表示前面的例子还没列举完,最后加个词“等等”。
例句3: I need to go to the store and buy some pie, milk, cheese, etc.
etc. 常常被误写为 ect.,这是因为很多英语的c在t前(c在t后的很少)。etc. 前面要有逗号。
不要在 e.g. 的列表最后用 etc( 在including后的列表后也不宜使用etc),这是因为 e.g. 表示泛泛的举几个例子,并没有囊括所有的实例,其中就已经包含“等等”,如果再加一个 etc. 就多余了,例如这是错的: Writing instructors focus on a number of complex skills that require extensive practice (e.g., organization, clear expression, logical thinking, etc.)
et al.
这是et alia(“and others; and co-workers”:等它人) 的缩写。它几乎都是在列文献作者时使用,即把主要作者列出后,其它作者全放在et al. 里面。
例句4: These results agree with the ones published by Pelon et al. (2002).
人的场合用 et al,而无生命的场合用 etc.(et cetera)。
et 后不要加“.”,因为 et 不是缩写。另外,与 etc. 不同,et al. 的前面不要逗号。
i.e.
这是id est(“that is” , “in other words”:也就是) 的缩写。目的是用来进一步解释前面所说的观点(不是像e.g.那样引入实例来形象化),意思是“那就是说,换句话说”。
例句5:In 2005, American had the lowest personal saving rate since 1933. In fact it was outright negavetive—i.e., consumers spent more money that they made.
例句6:There are three meals in the day (i.e., breakfast, lunch, and dinner)
使用中,i.e.的第一个”.”也常常被错误地漏掉了。它后面紧跟着一个逗号,再跟一个解释。
如同e.g., i.e.也最好放入括号中,如同例句6那样。
比较下面两个例句。
例句7:I like to eat boardwalk food, i.e., funnel cake and french fries.
例句8:I like to eat boardwalk food, e.g., funnel cake and french fries.
例句7表示只有 funnel cake and french fries这两样boardwalk食物,我喜欢。例句8表示我喜欢boardwalk食物,比如 funnel cake and french fries;其实snow cones and corn dogs等其他类型,我也喜欢。
为了方便记忆,你可把”i.e.” 与 “in essence” 联想起来。
viz.
这是 videlicet(“namely”, “towit”, “precisely”, “that is to say”:即) 的缩写,与 e.g. 不同,viz. 位于同位列表之前,要把它前面单词所包含的项目全部列出。
例句9:“Each symbol represents one of the four elements, viz. earth, air, fire, and water.”(每个符号代表如下四个元素之一,即: 地球,空气,火焰和水)。
例句10: The noble gases, viz. helium, neon, argon, xenon, krypton and radon, show a non-expected behaviour when exposed to this new element.
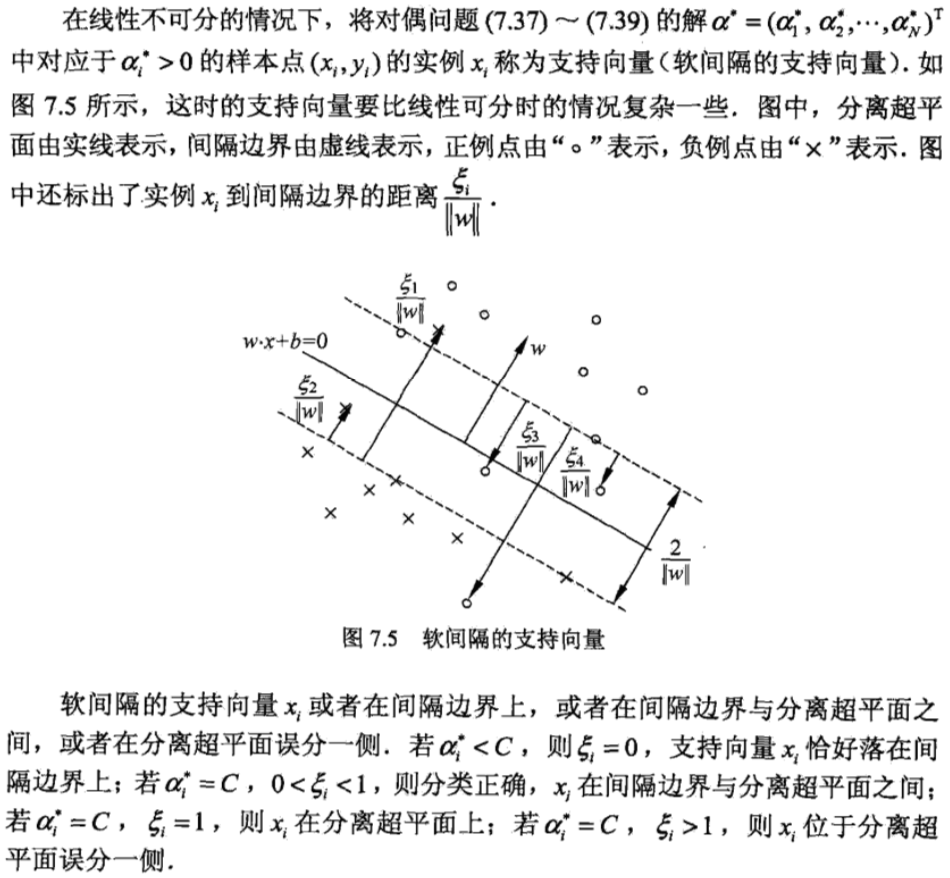
注意 viz.后面无逗号。

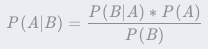
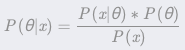


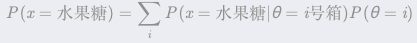


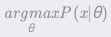




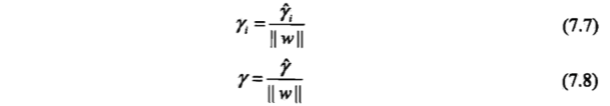
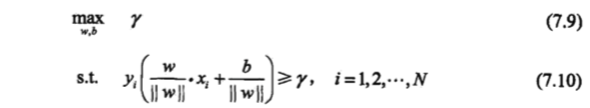
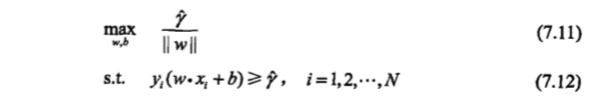




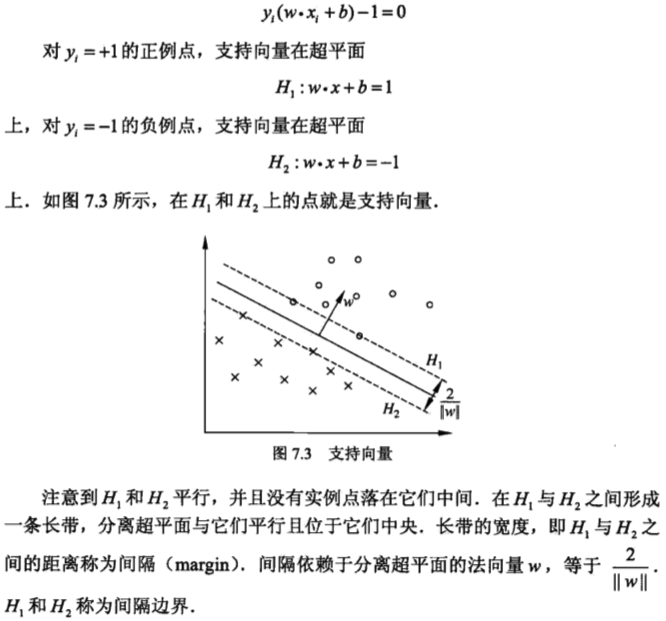
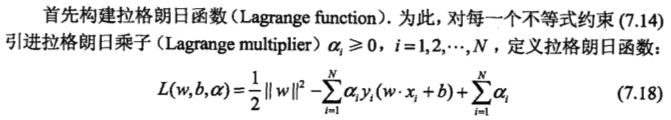




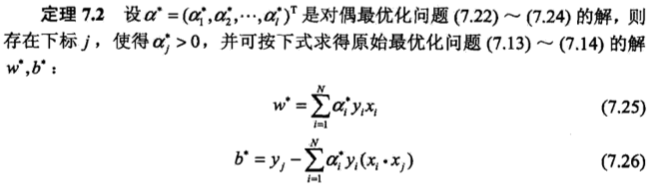
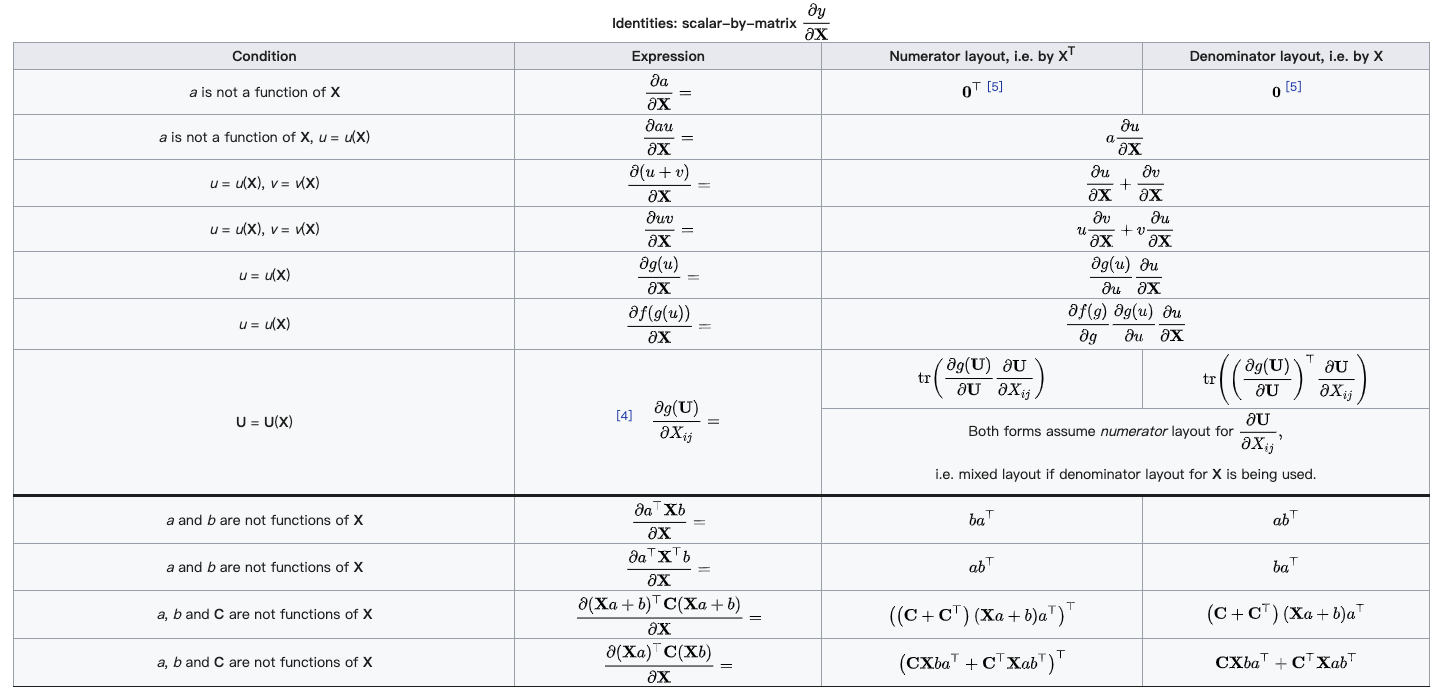
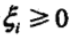 ,使函数间隔加上松弛变量大于等于 1.这样,约束条件变为
,使函数间隔加上松弛变量大于等于 1.这样,约束条件变为 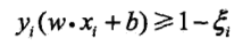
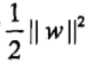 变成
变成 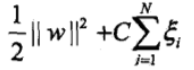
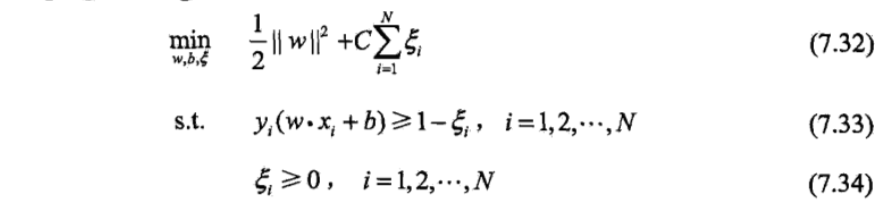











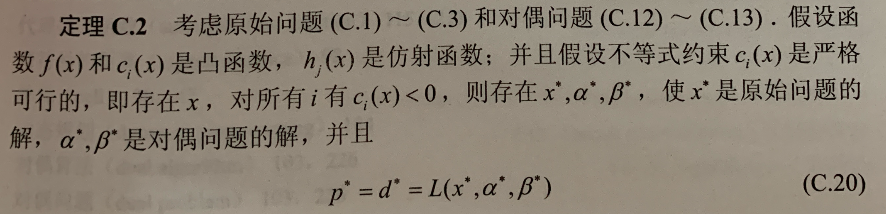


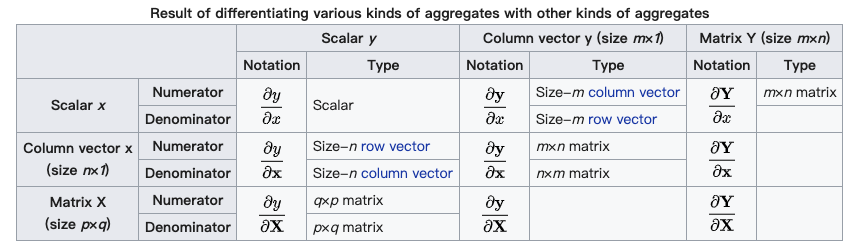
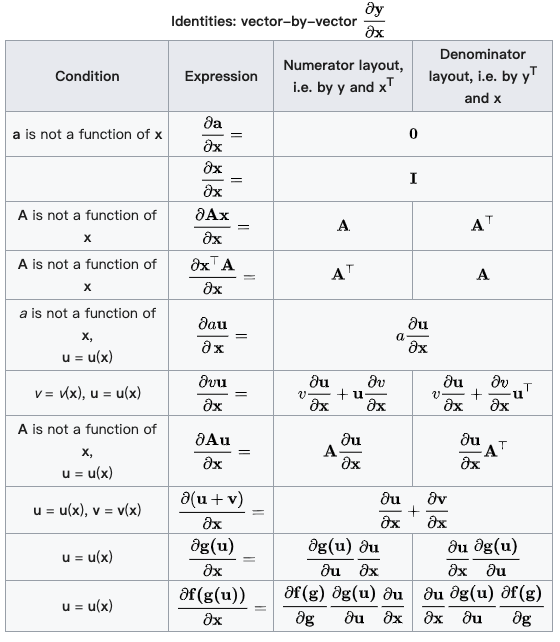
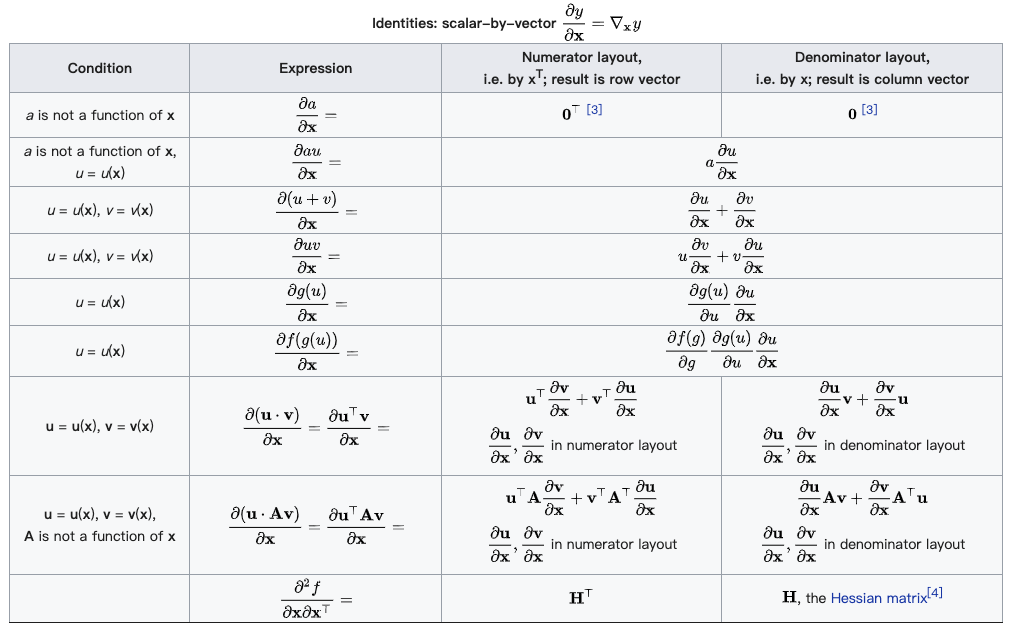
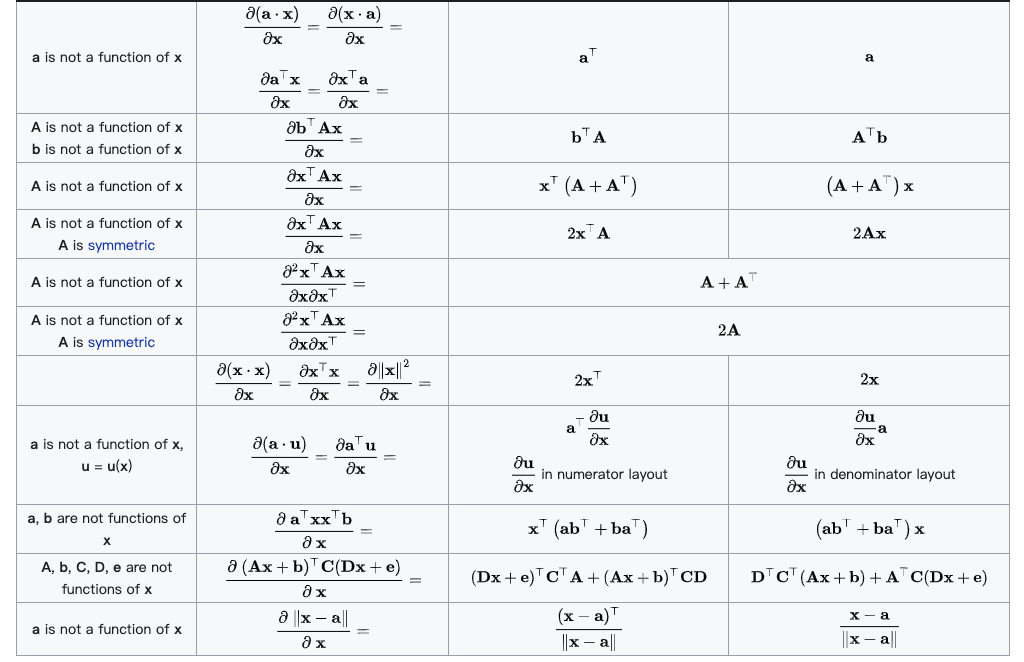
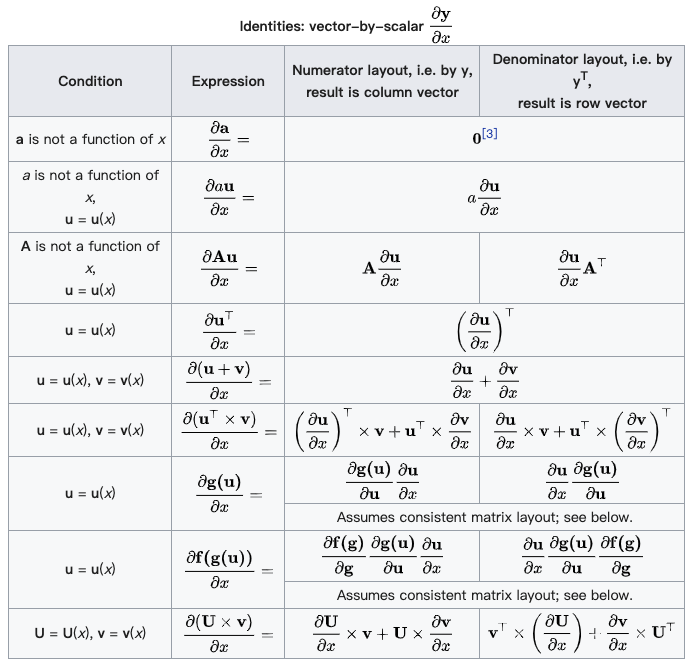
 (分母的向量为行向量)
(分母的向量为行向量)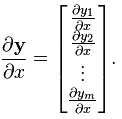 (分子的向量为列向量)
(分子的向量为列向量) (分子为列向量横向平铺,分母为行向量纵向平铺)
(分子为列向量横向平铺,分母为行向量纵向平铺)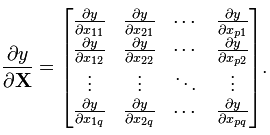 (注意这个矩阵部分是转置的,而下面的分母布局是非转置的)
(注意这个矩阵部分是转置的,而下面的分母布局是非转置的)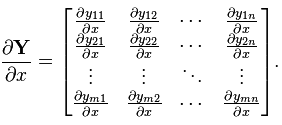
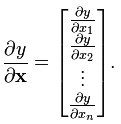 (分母的向量为列向量)
(分母的向量为列向量)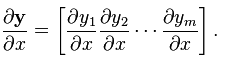 (分子的向量为行向量)
(分子的向量为行向量)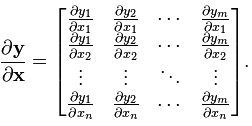 (分子为行向量纵向平铺,分母为列向量横向平铺)
(分子为行向量纵向平铺,分母为列向量横向平铺) (矩阵部分为原始矩阵)
(矩阵部分为原始矩阵)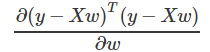
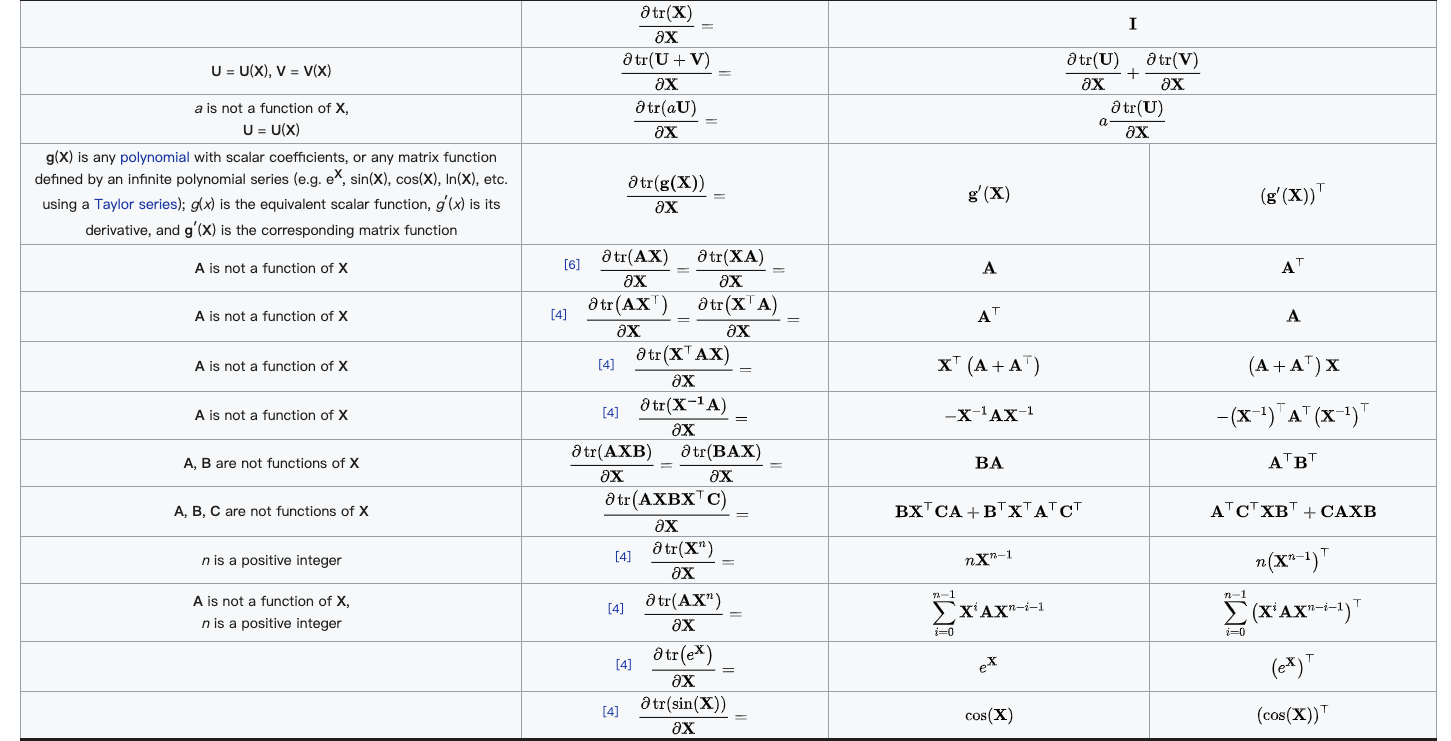
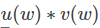 的形式,这种形式一般求导较为复杂,因此为了简化运算,我们先把式子展开成下面的样子(注意:
的形式,这种形式一般求导较为复杂,因此为了简化运算,我们先把式子展开成下面的样子(注意: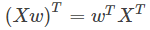 : )
: )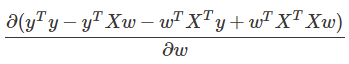
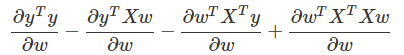
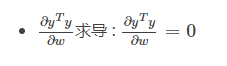
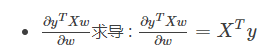
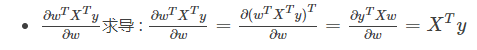
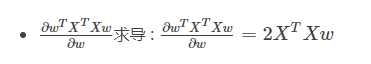
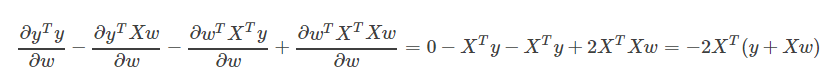
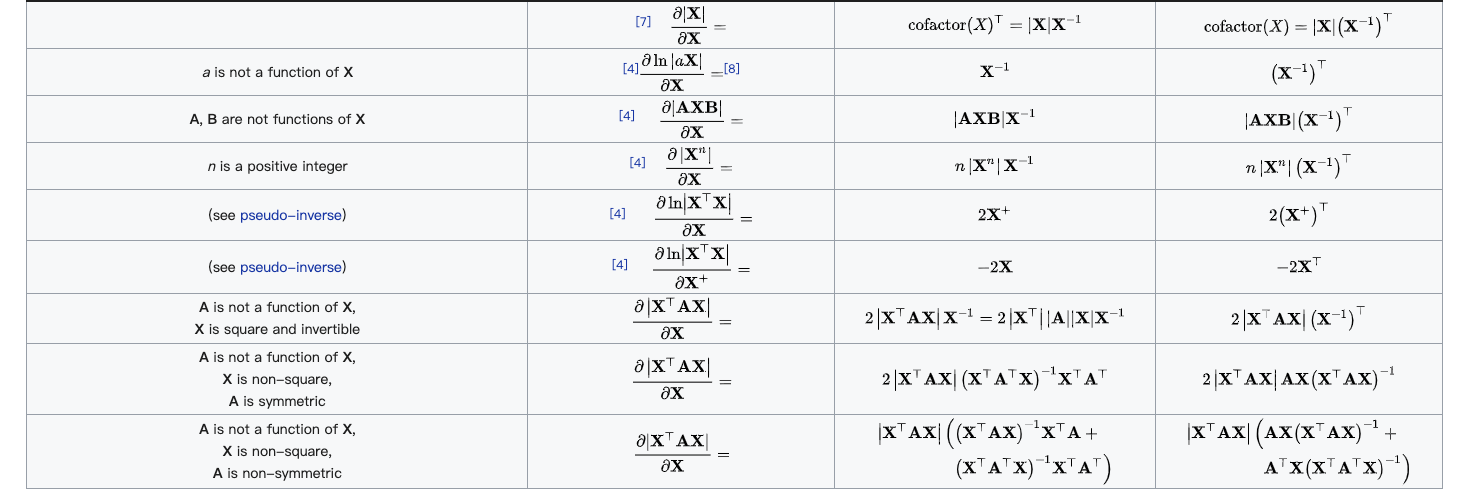
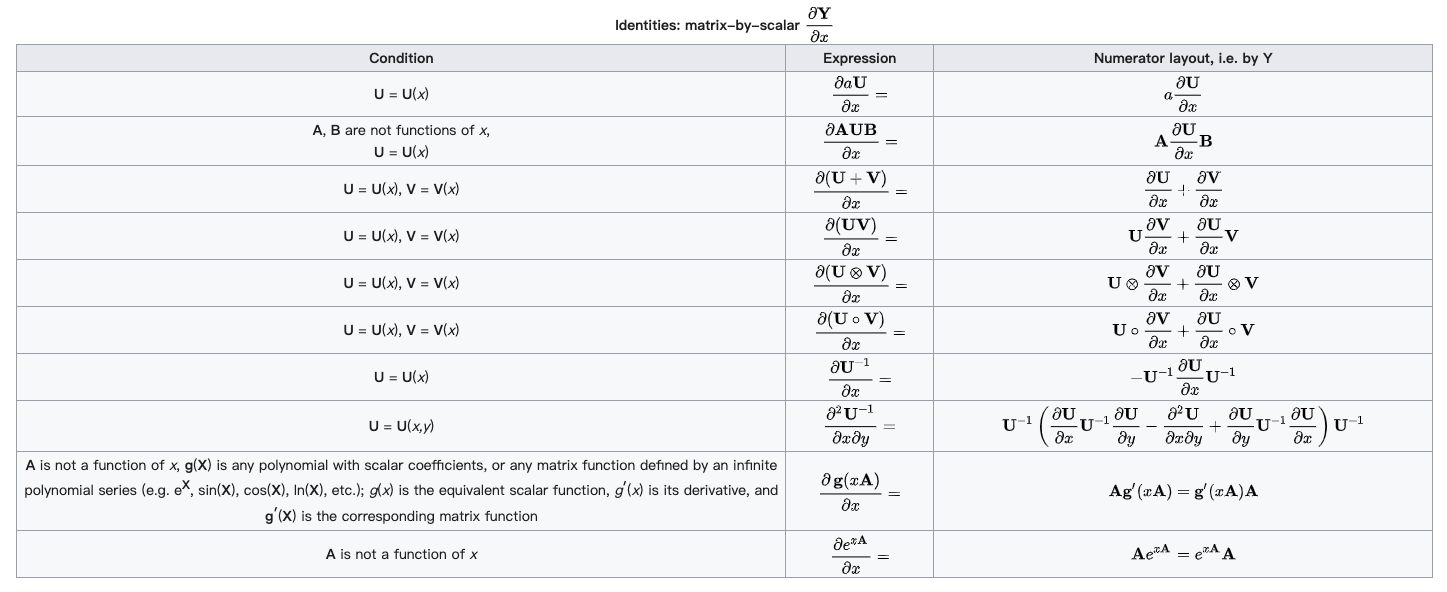
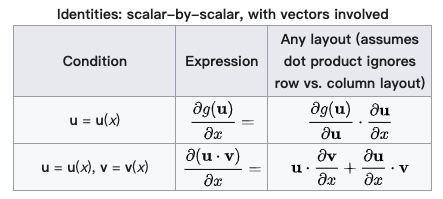
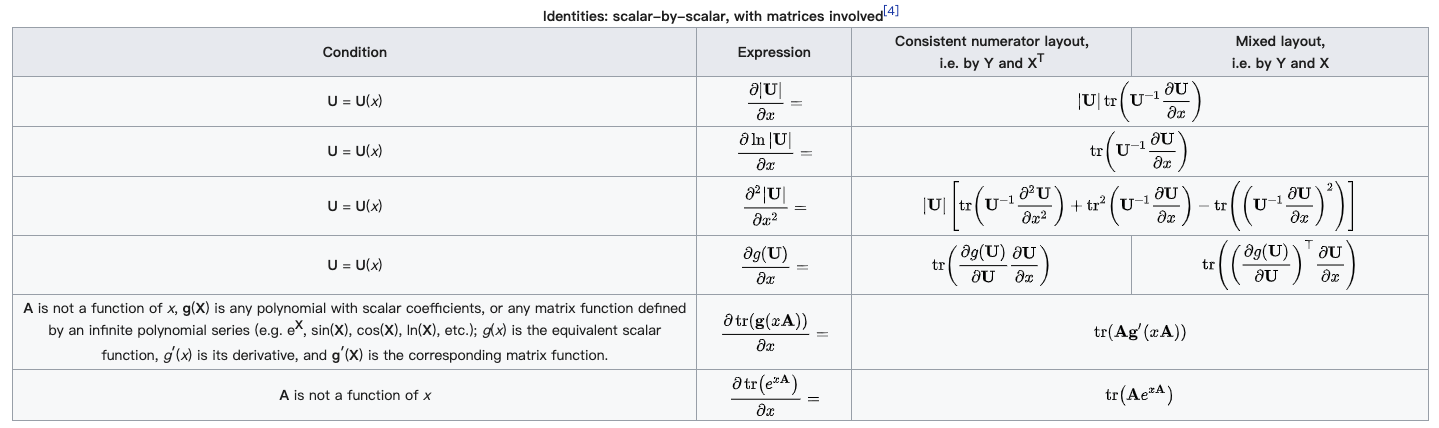


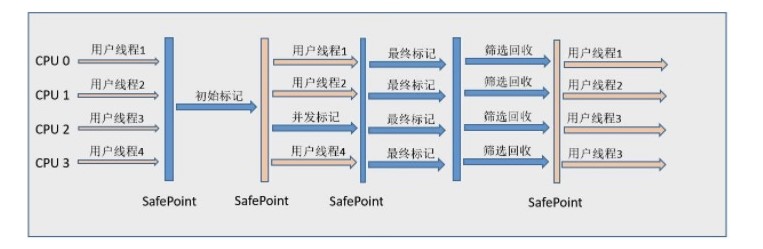
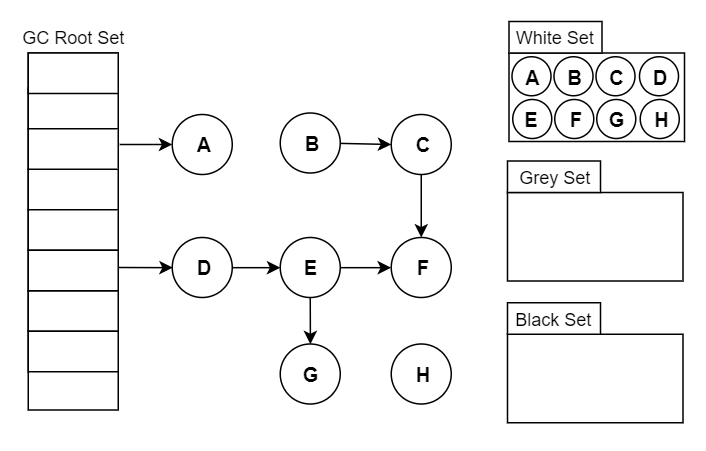
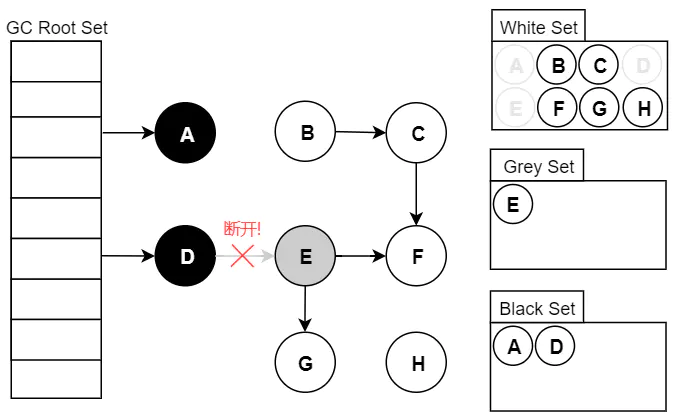
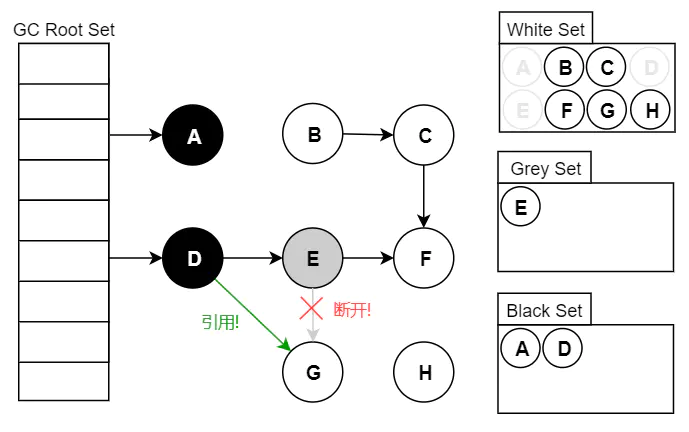





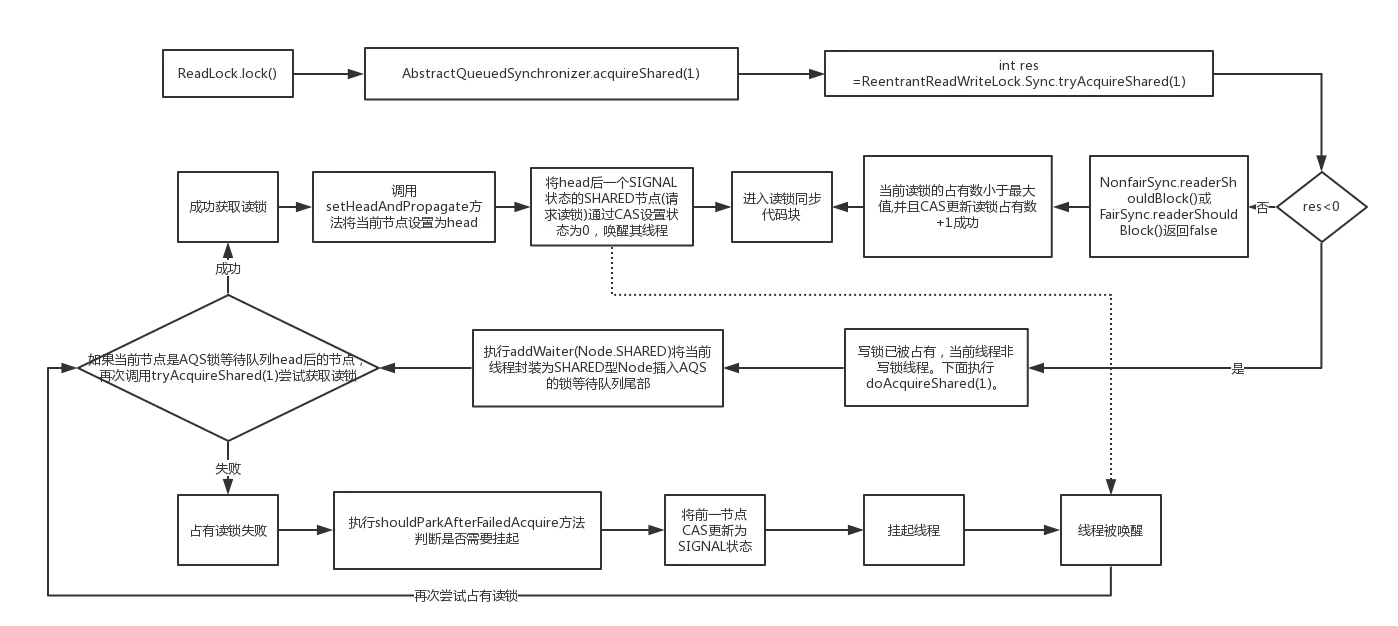
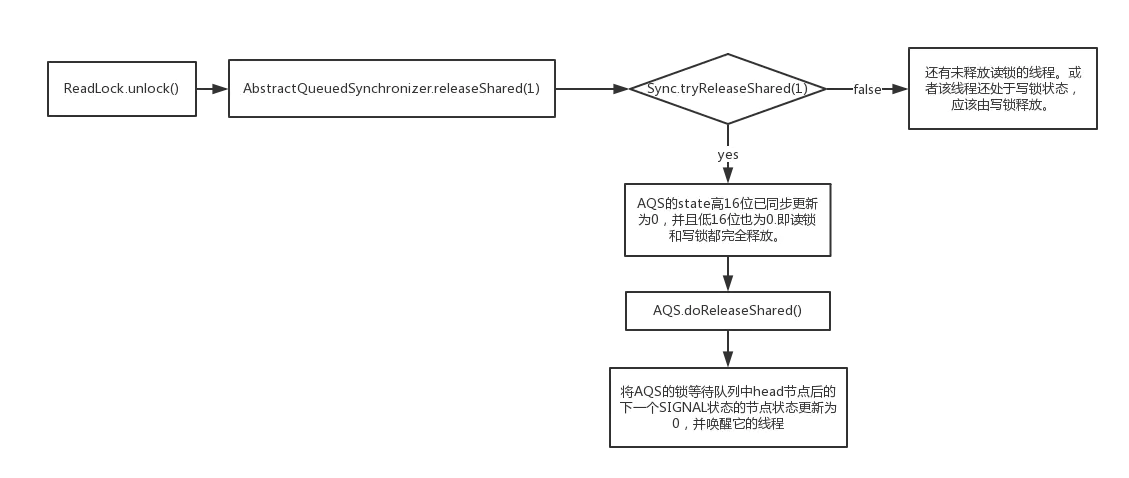
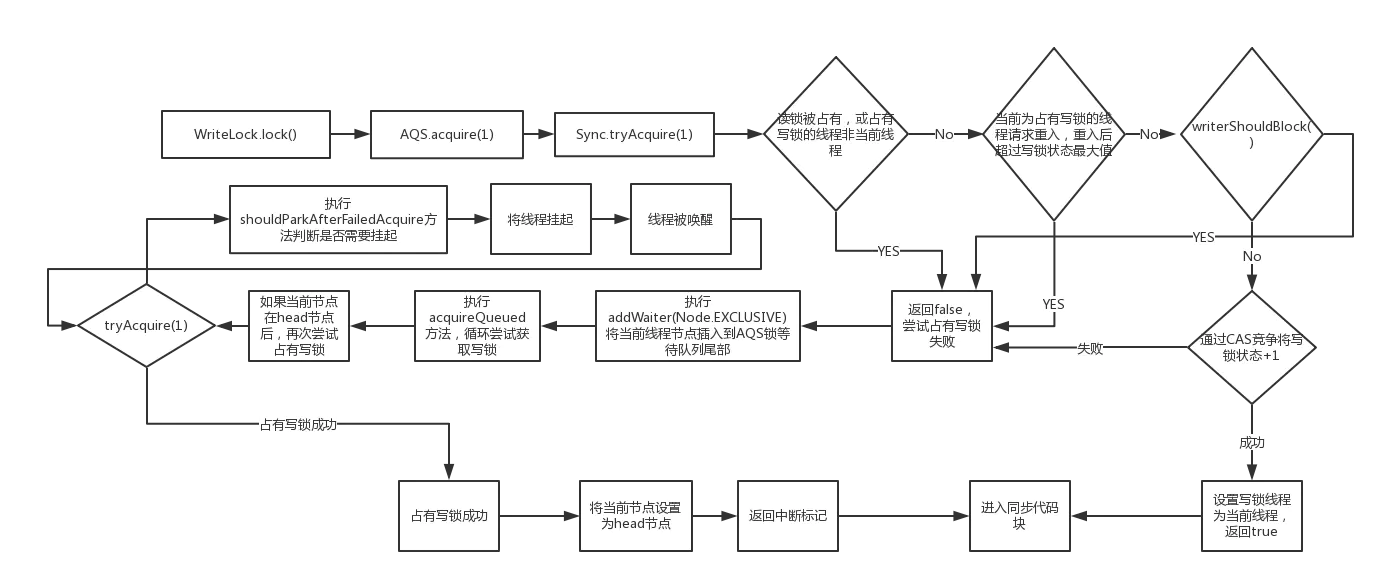
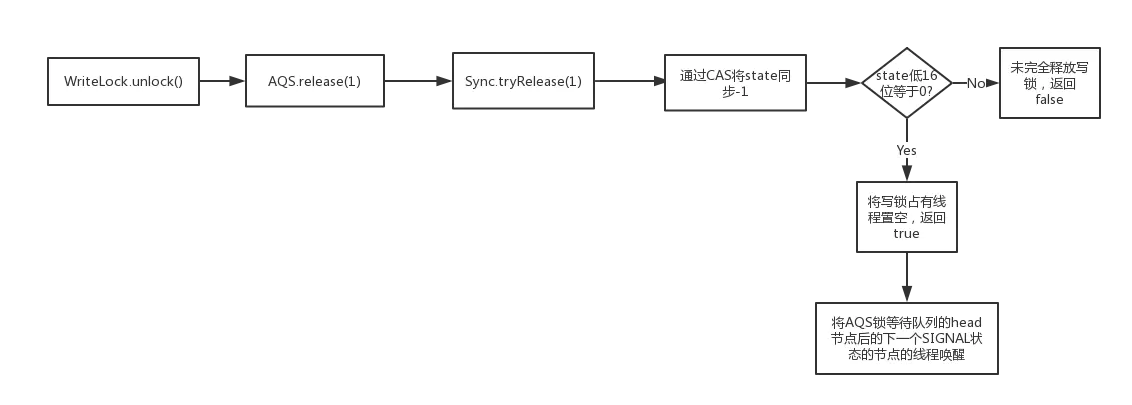
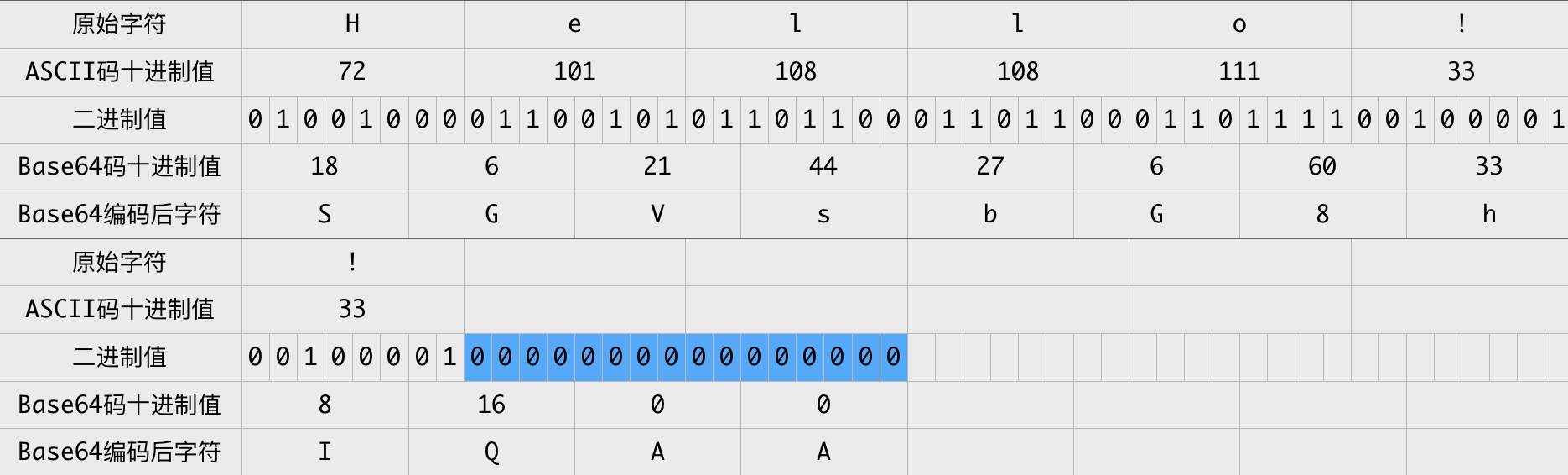
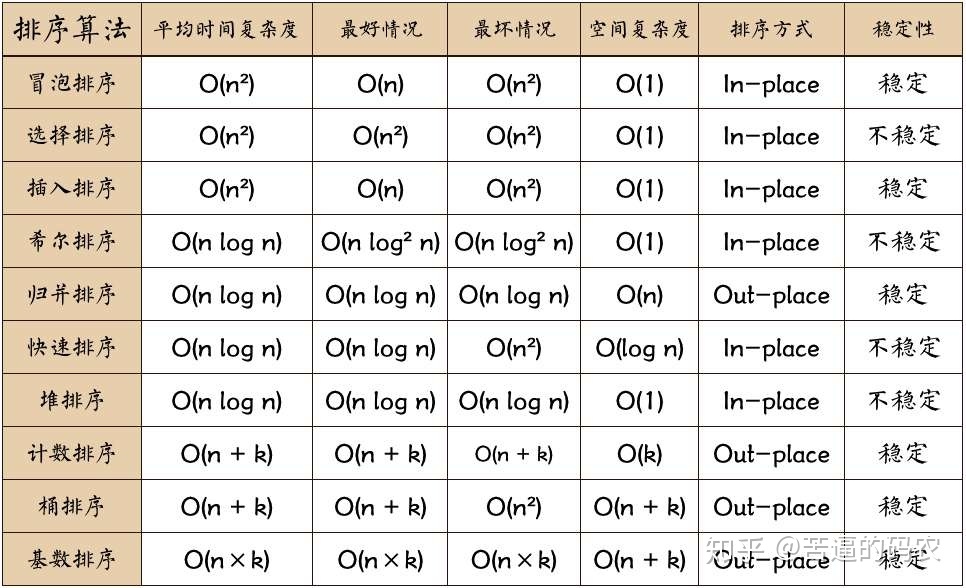



.gif)