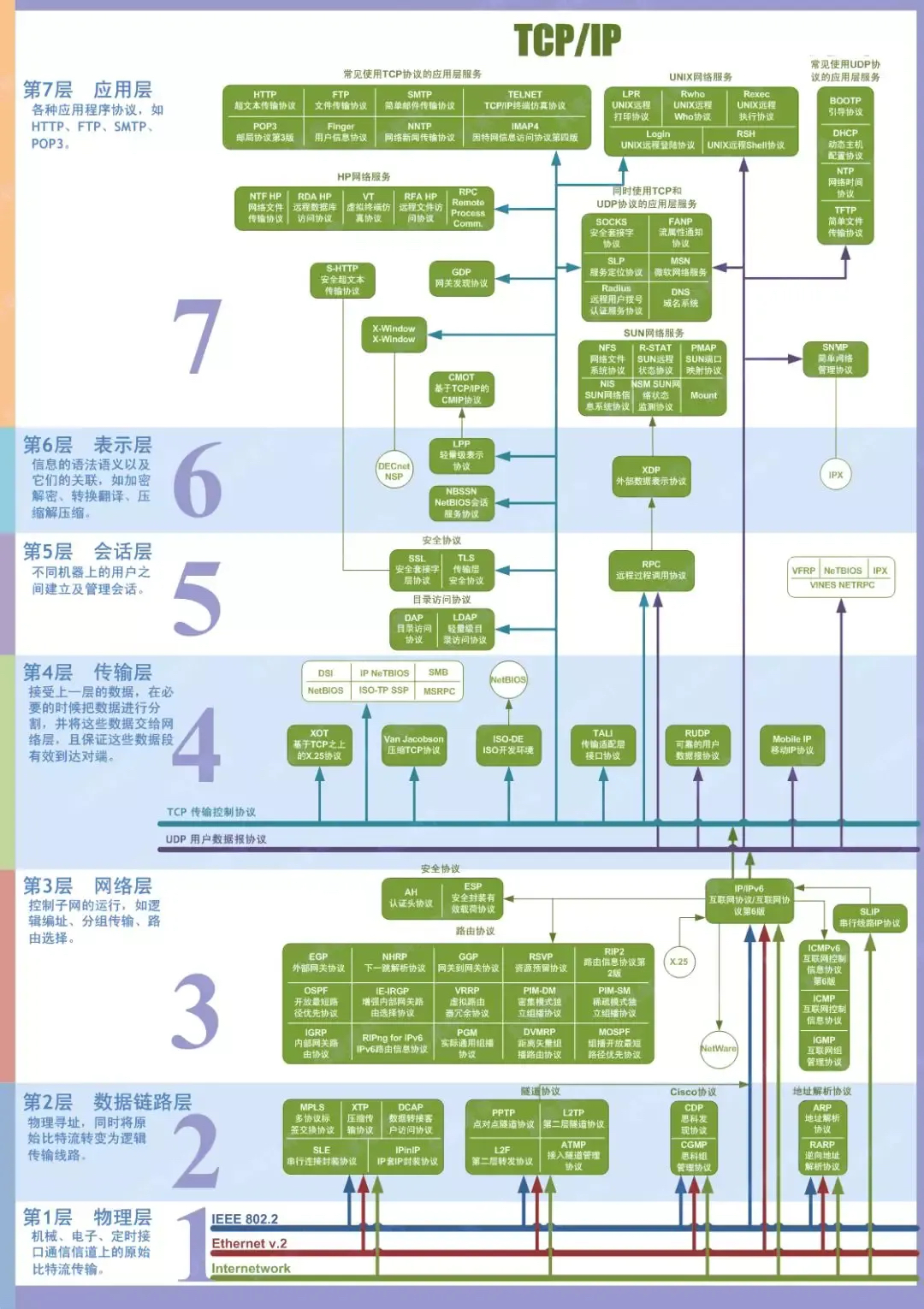
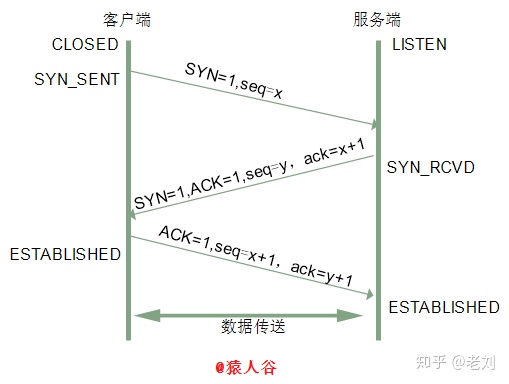
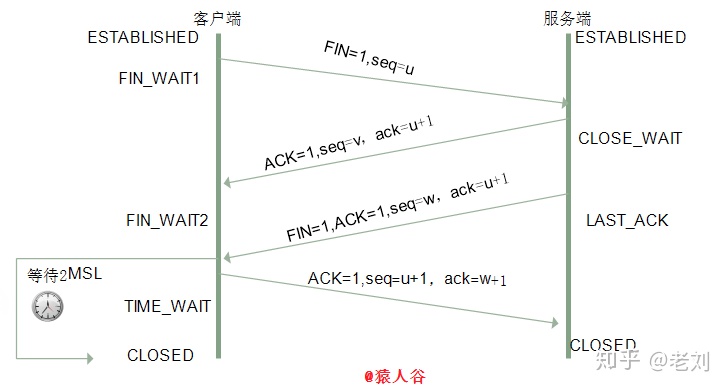
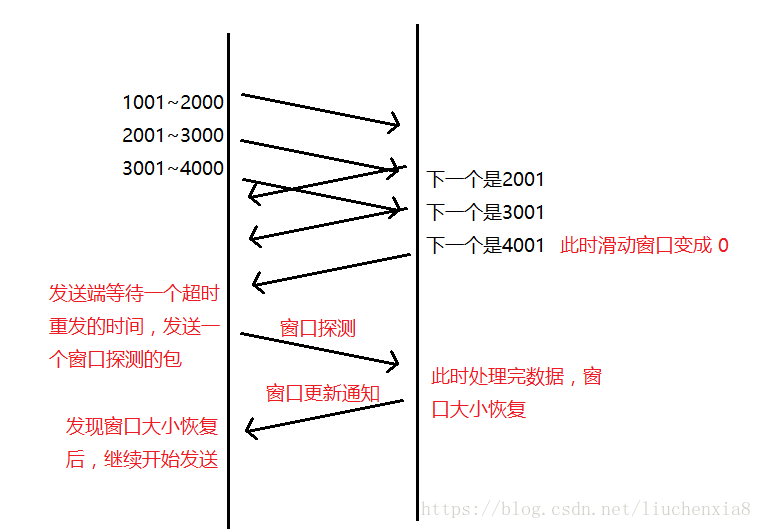
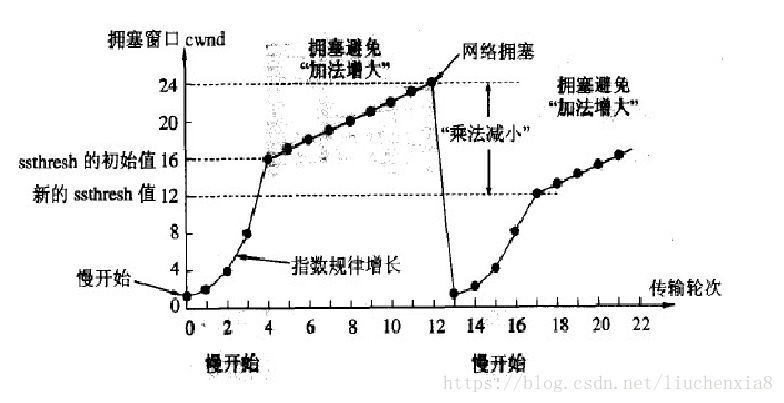
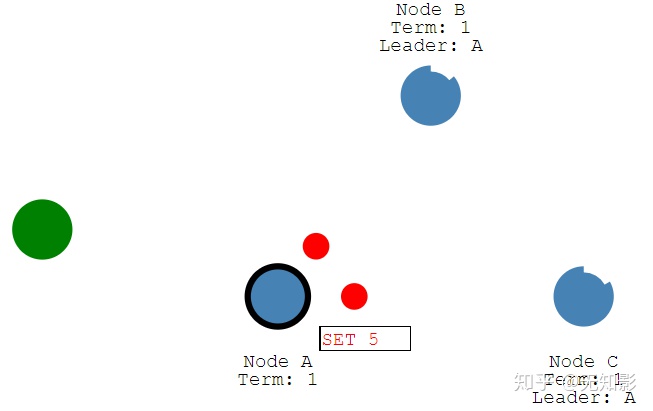
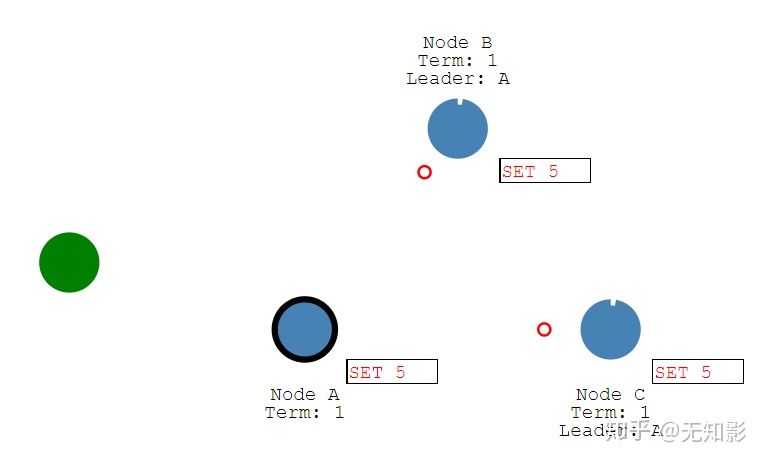
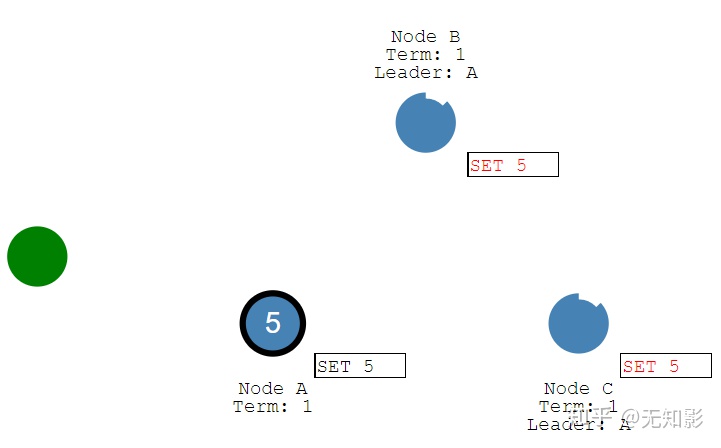
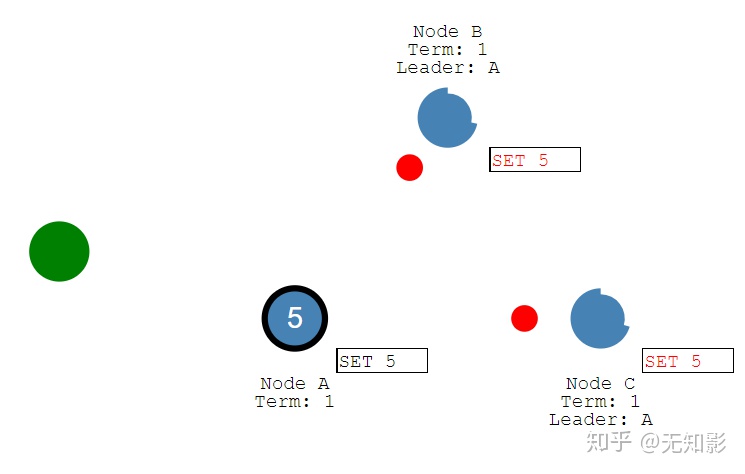
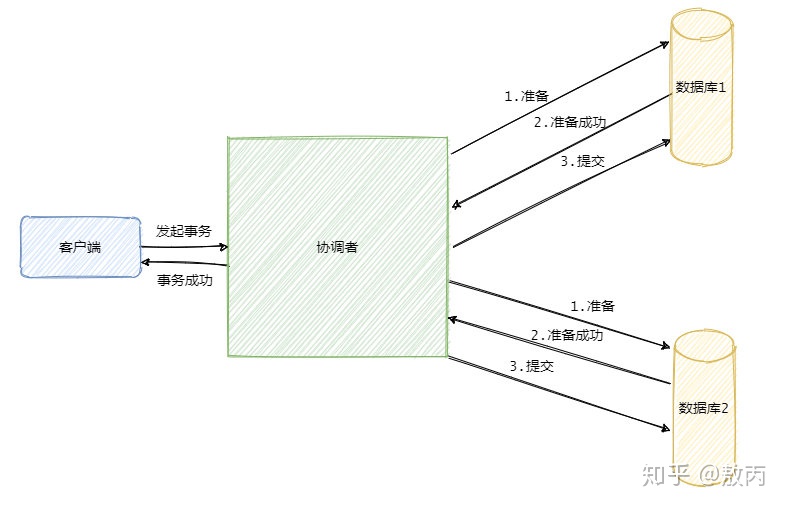
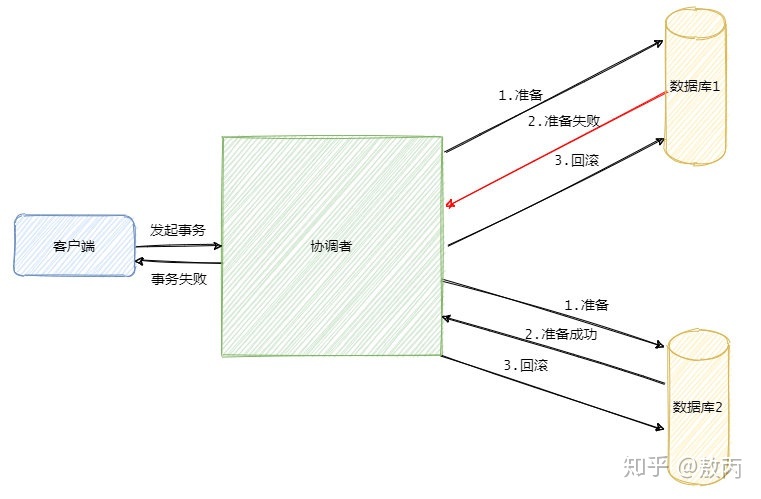
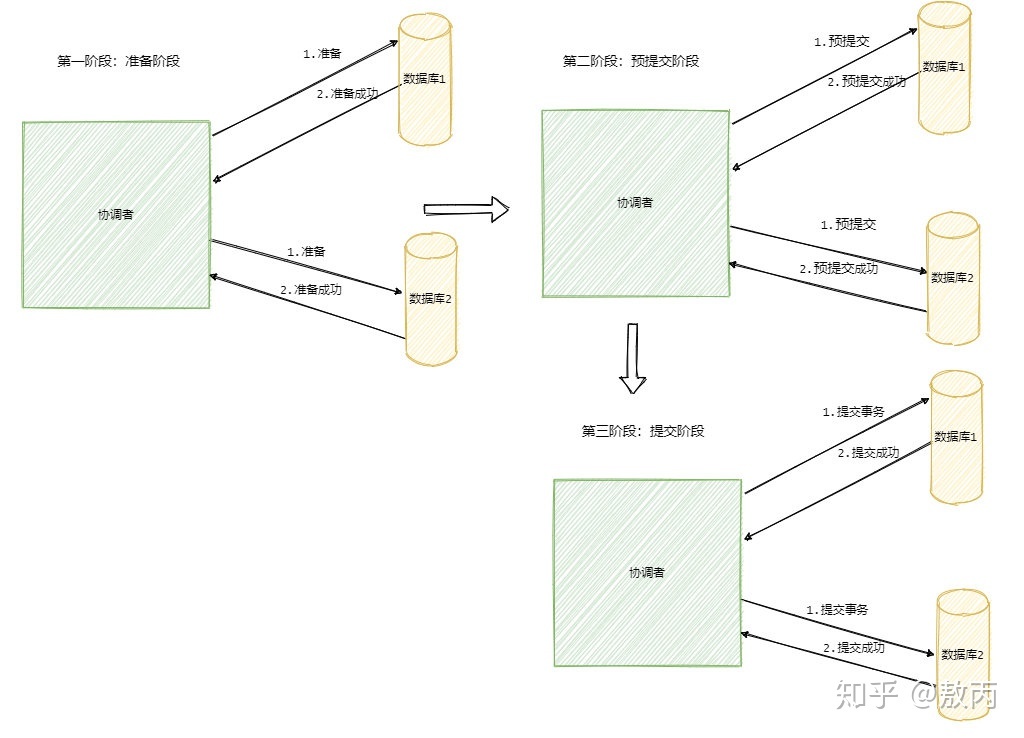
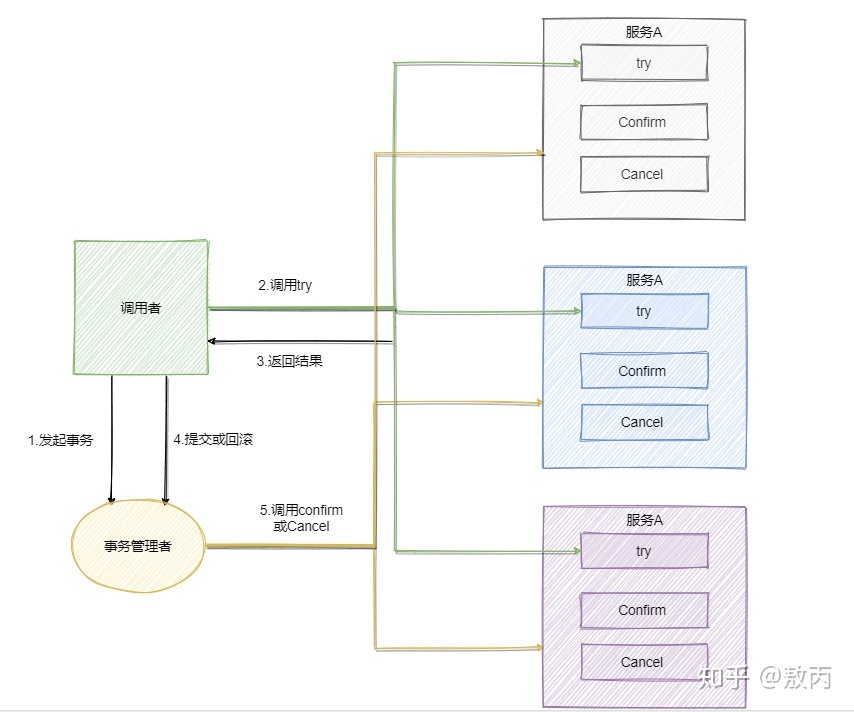
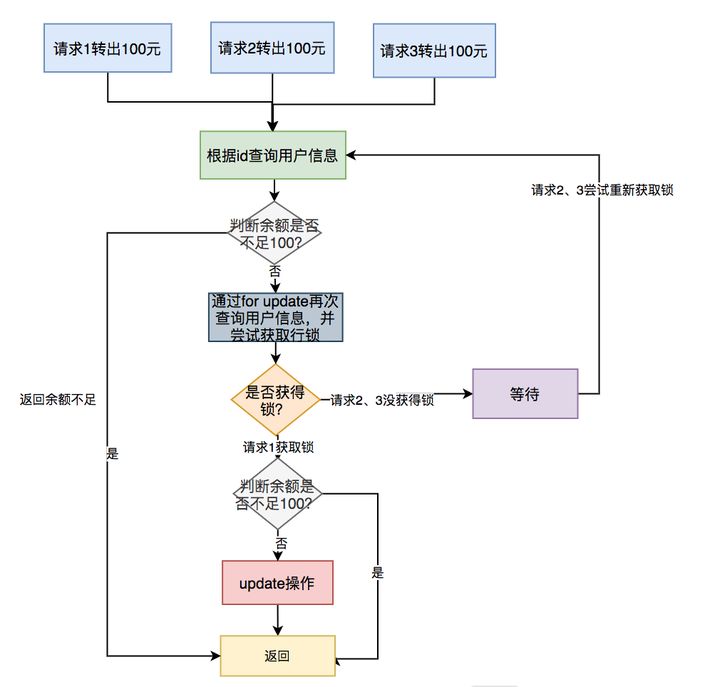
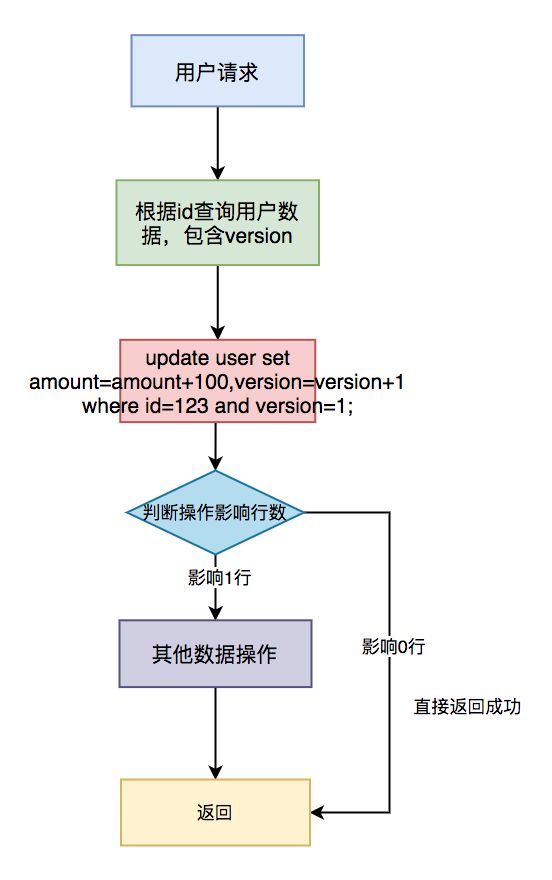
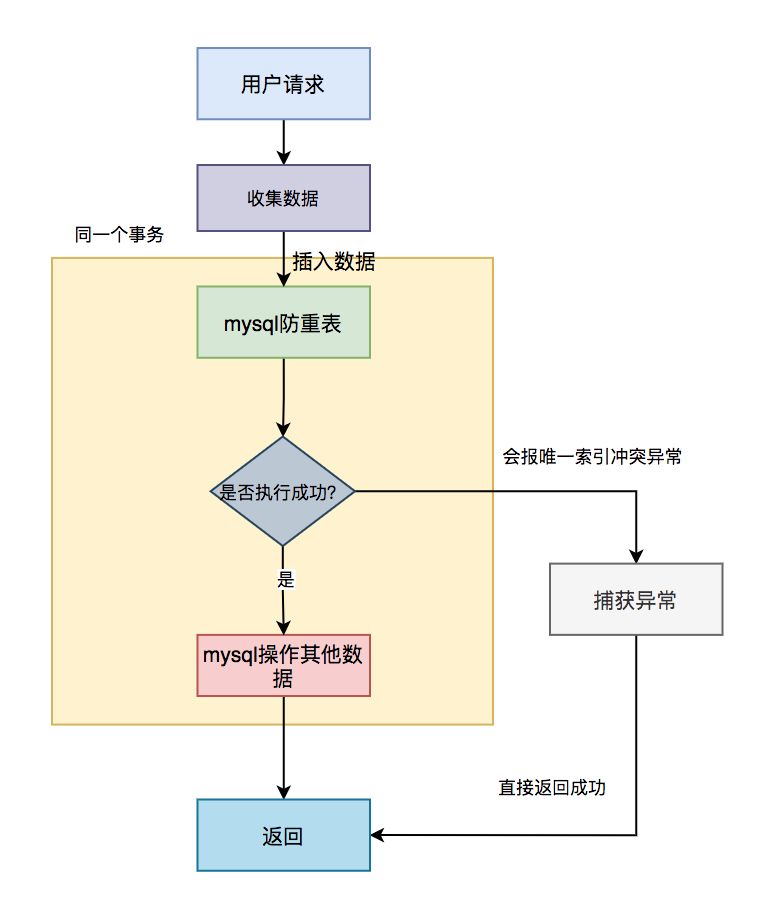
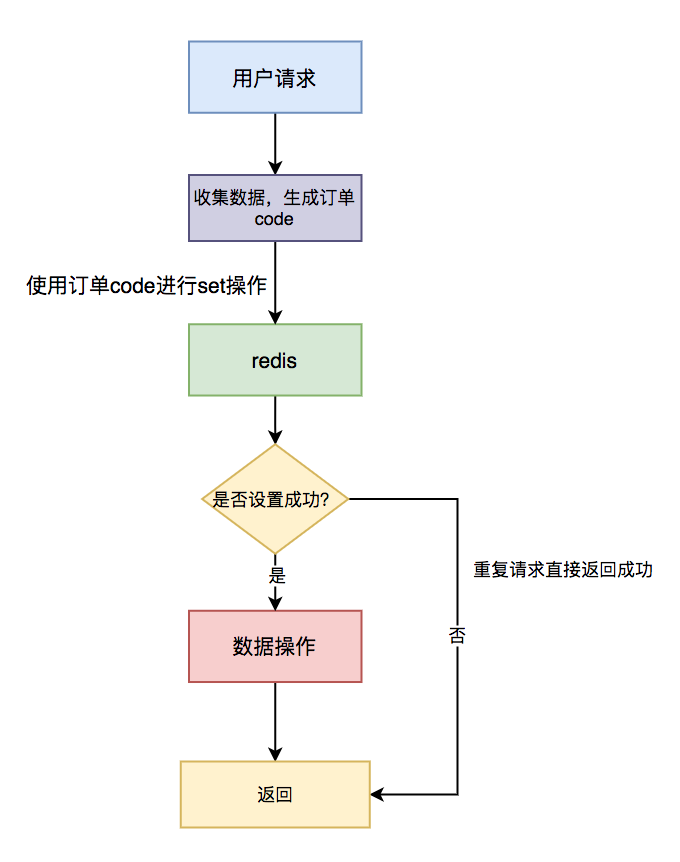
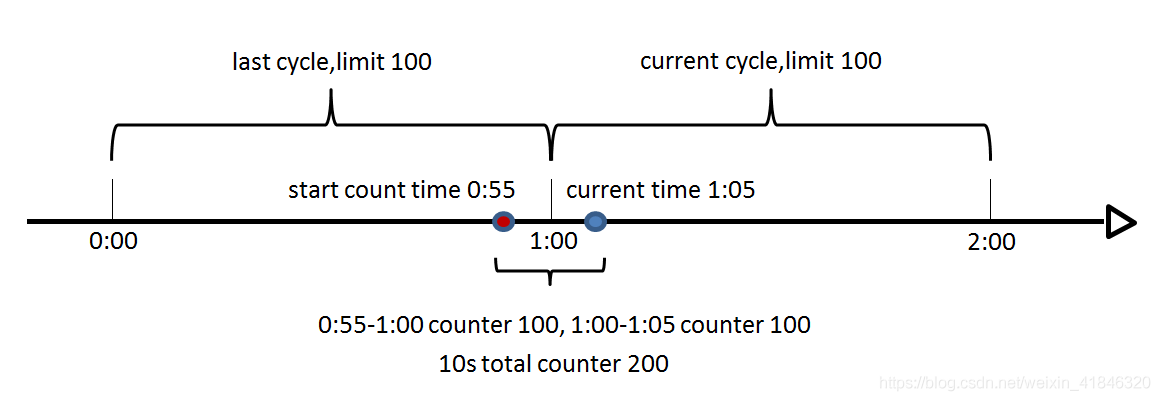
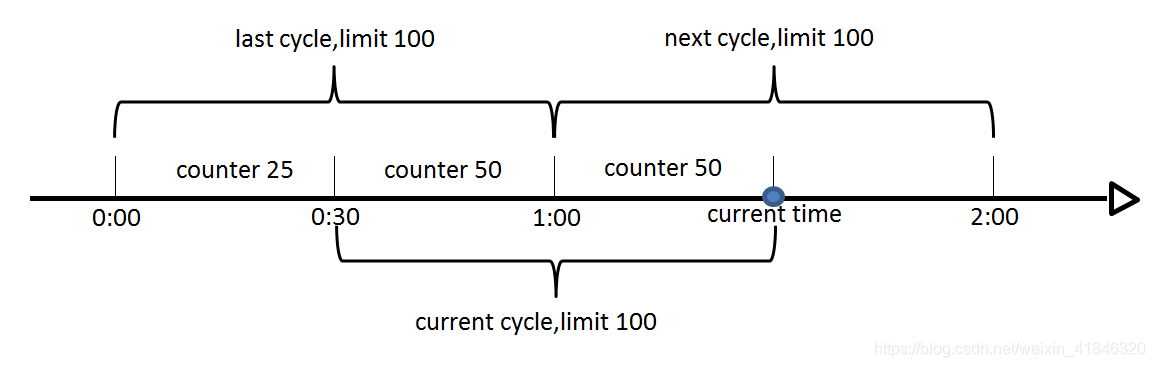
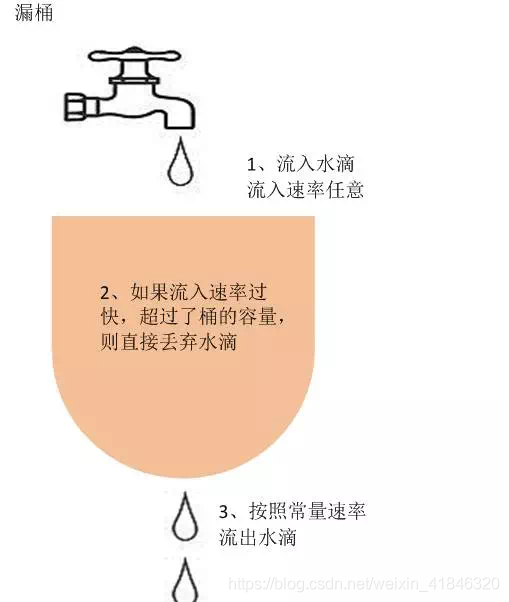
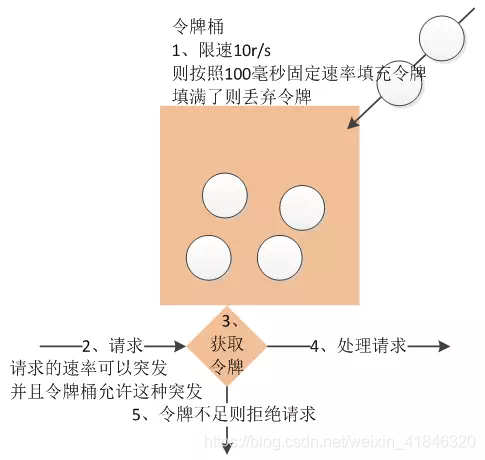
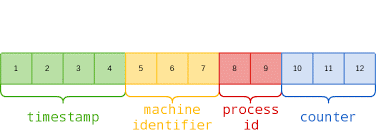
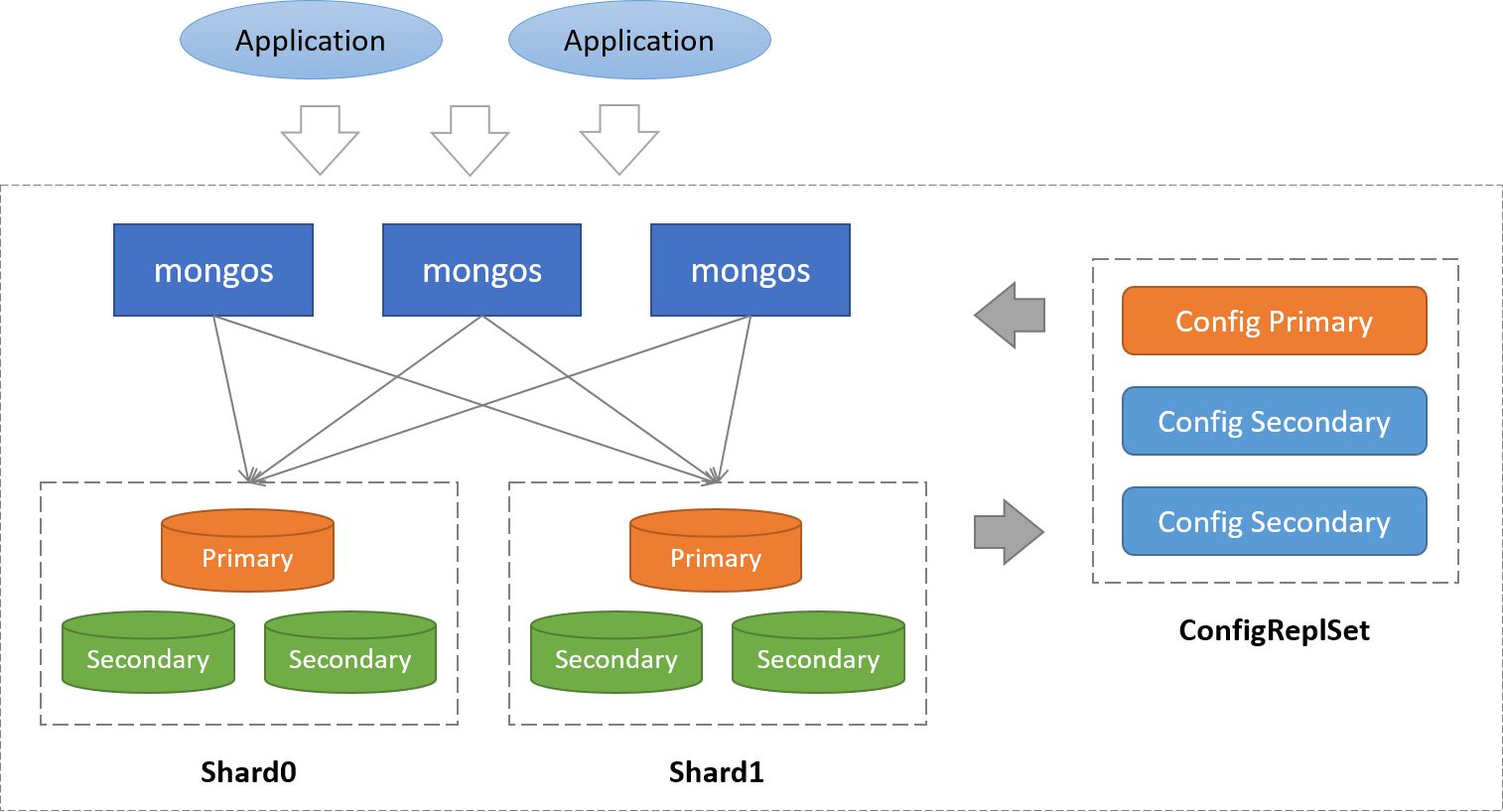
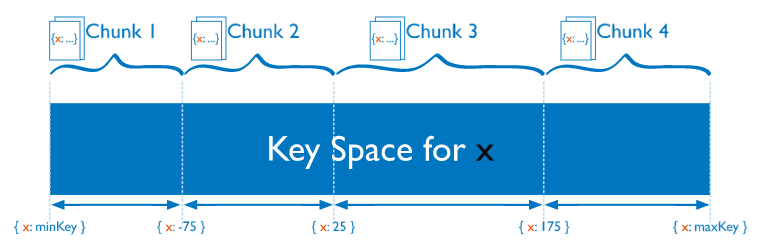
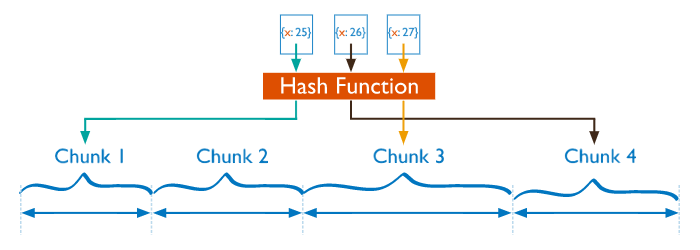
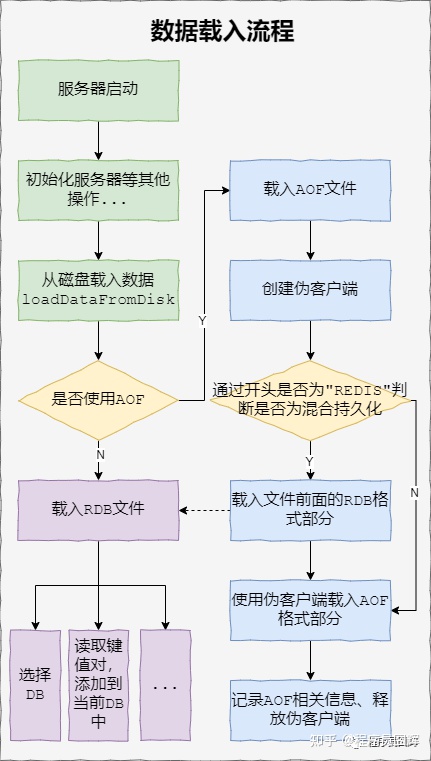
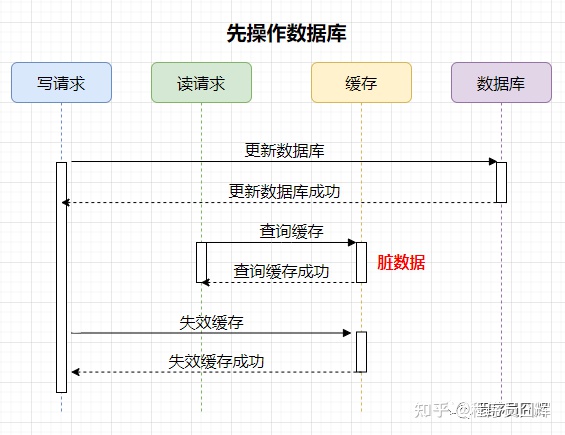
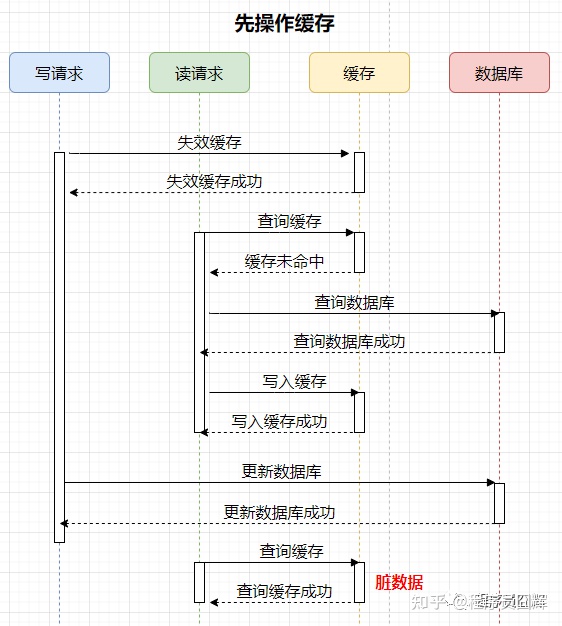
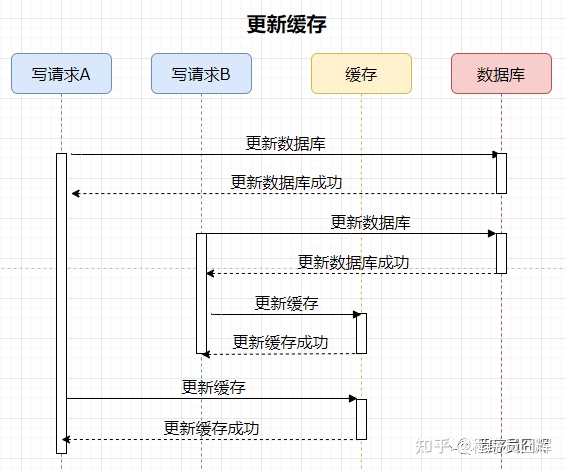
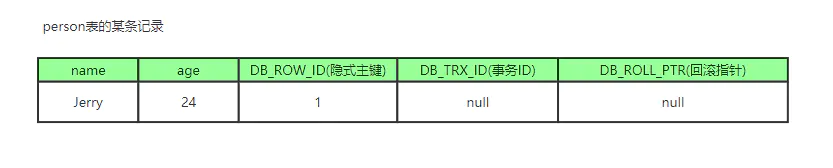
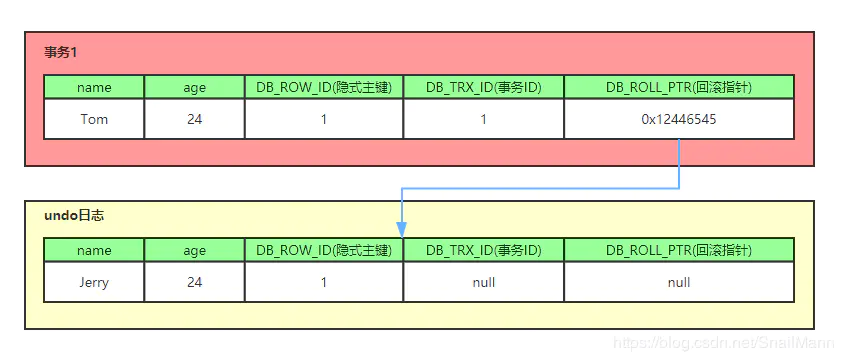
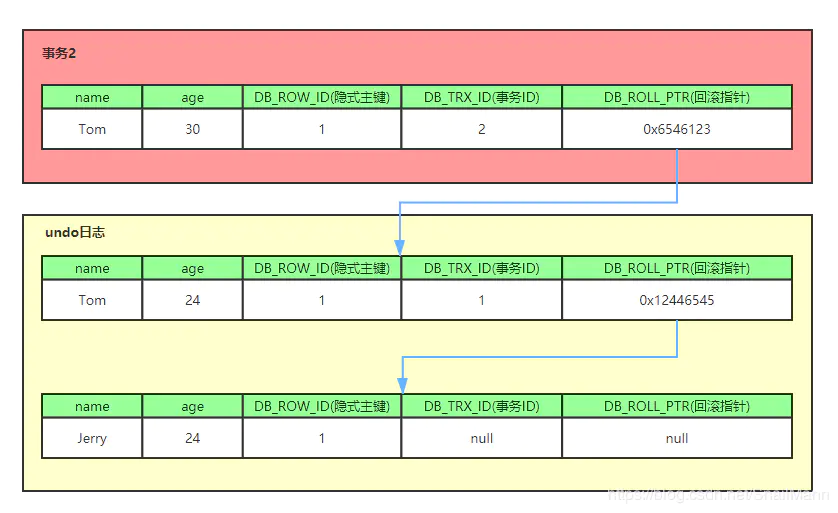
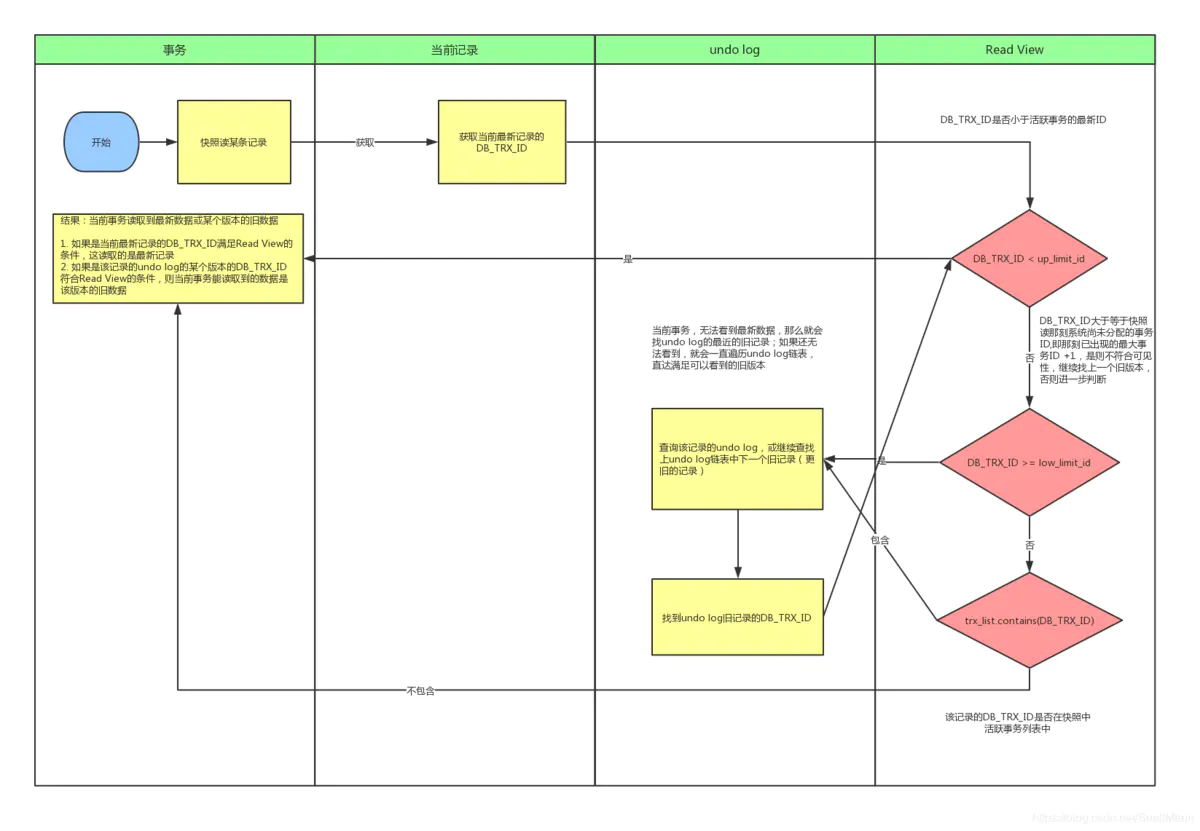
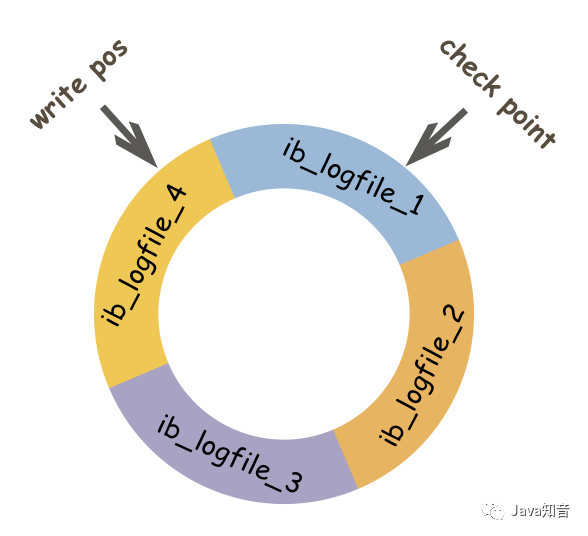
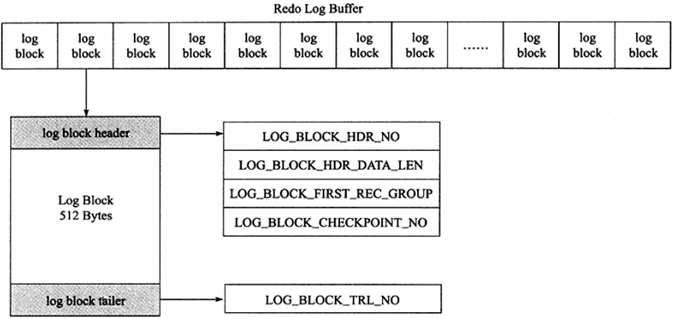
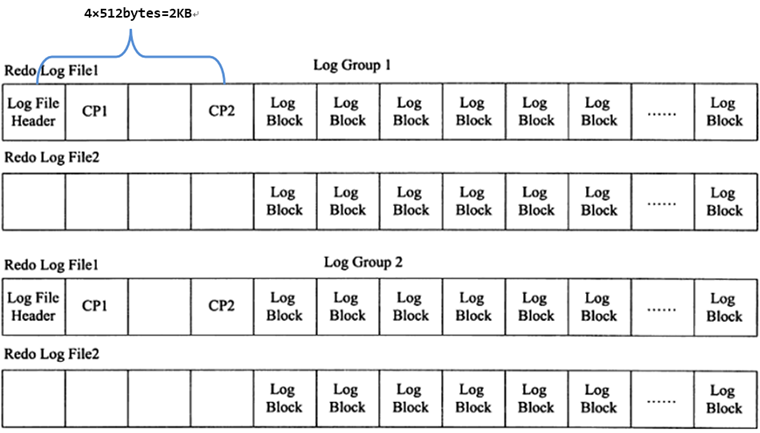
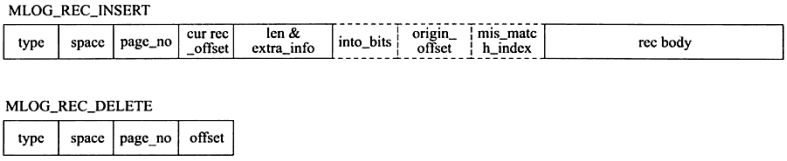
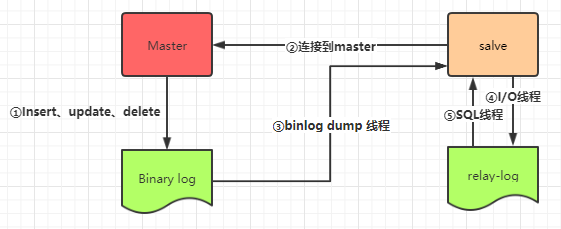
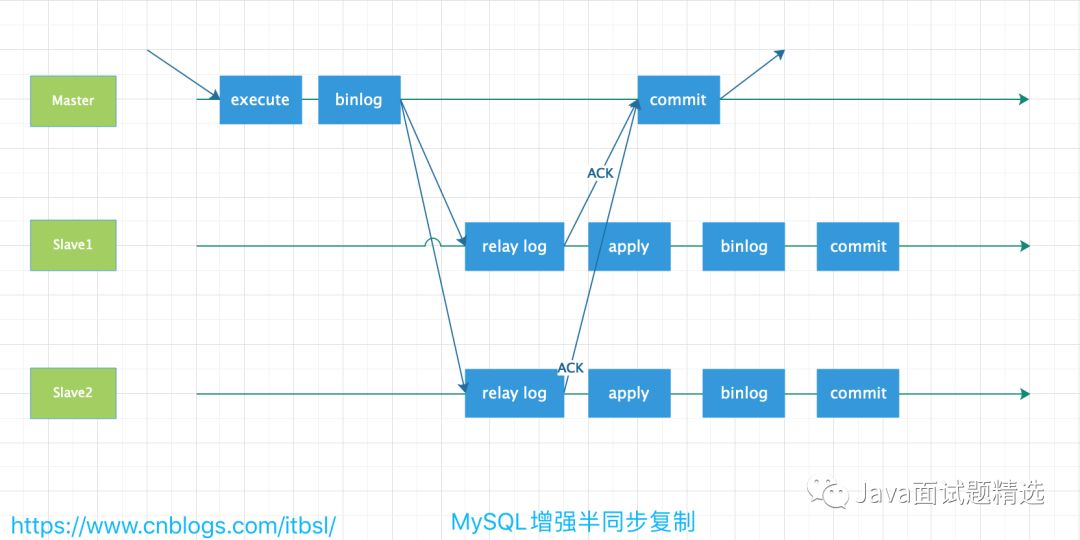
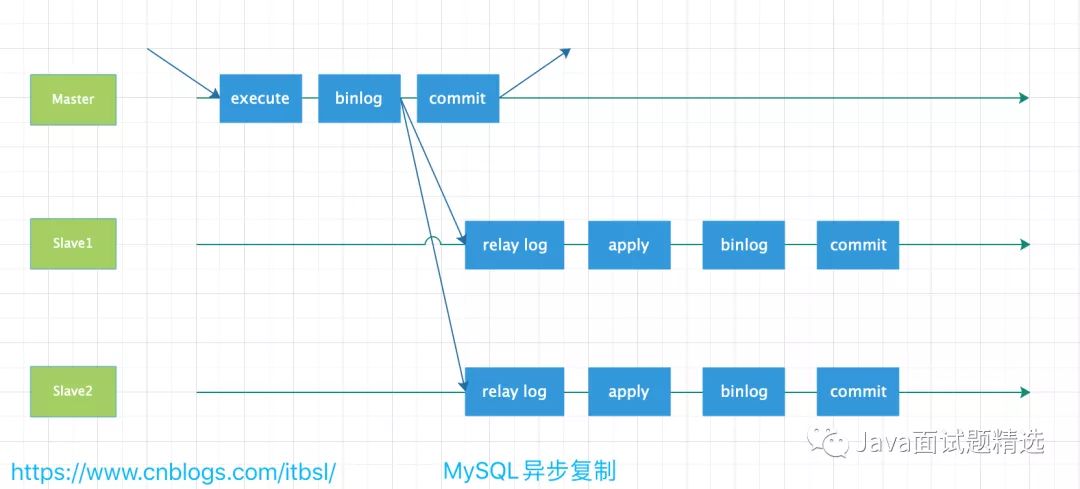
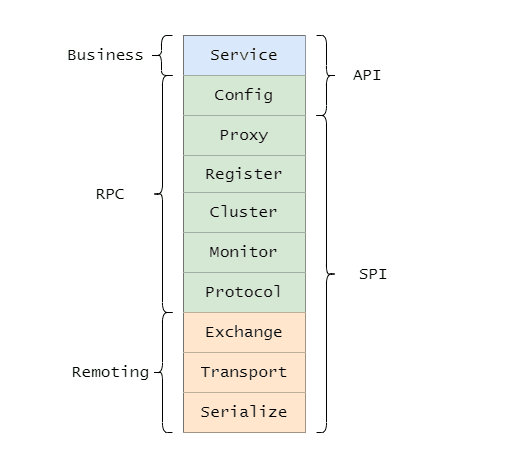
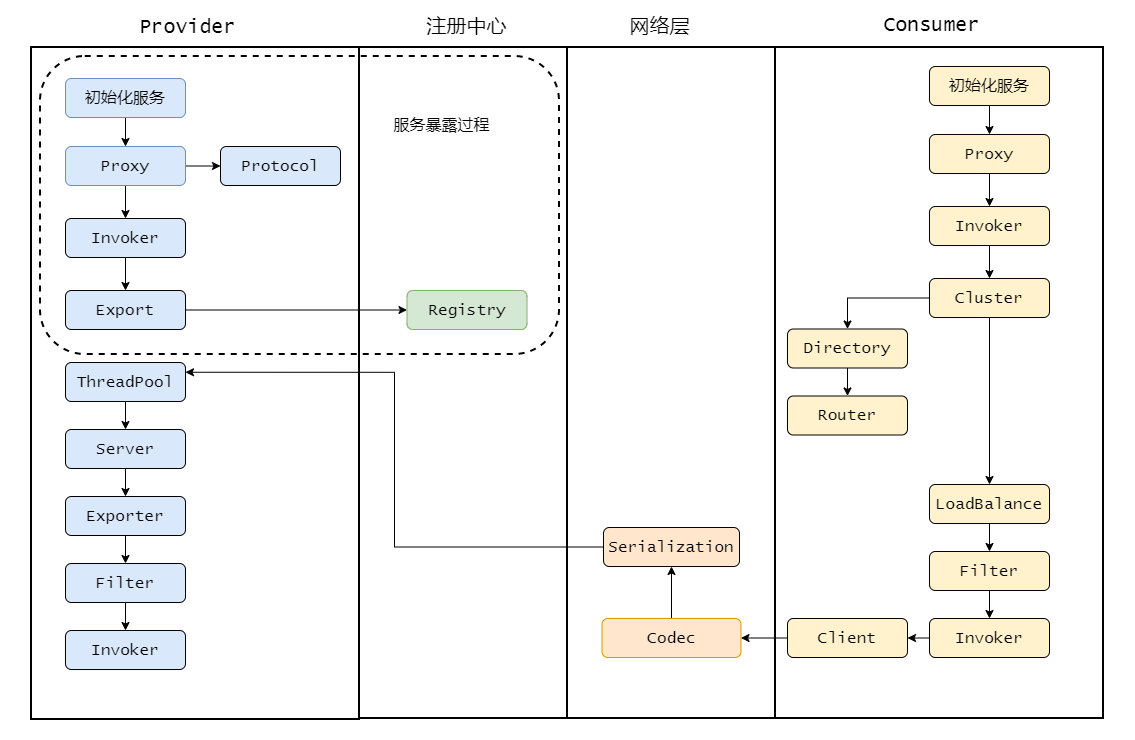
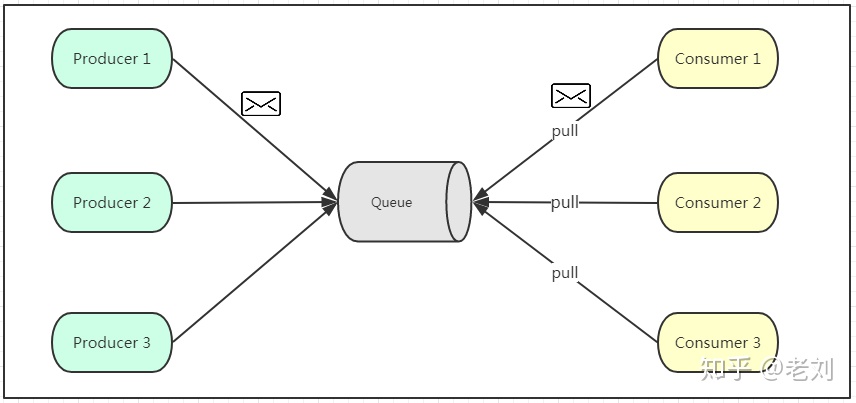
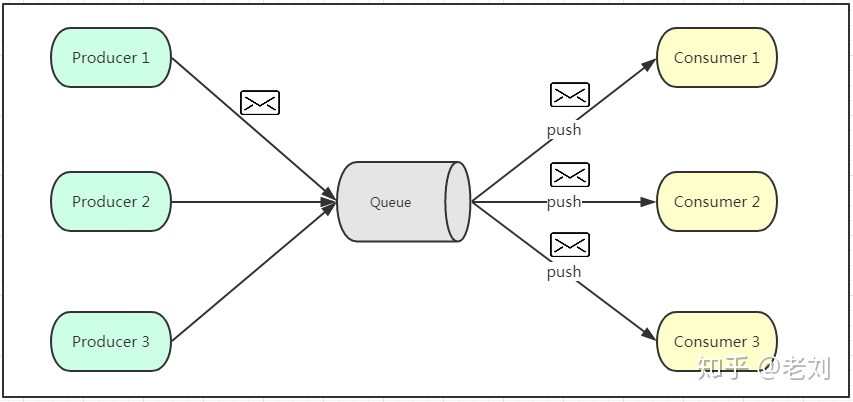
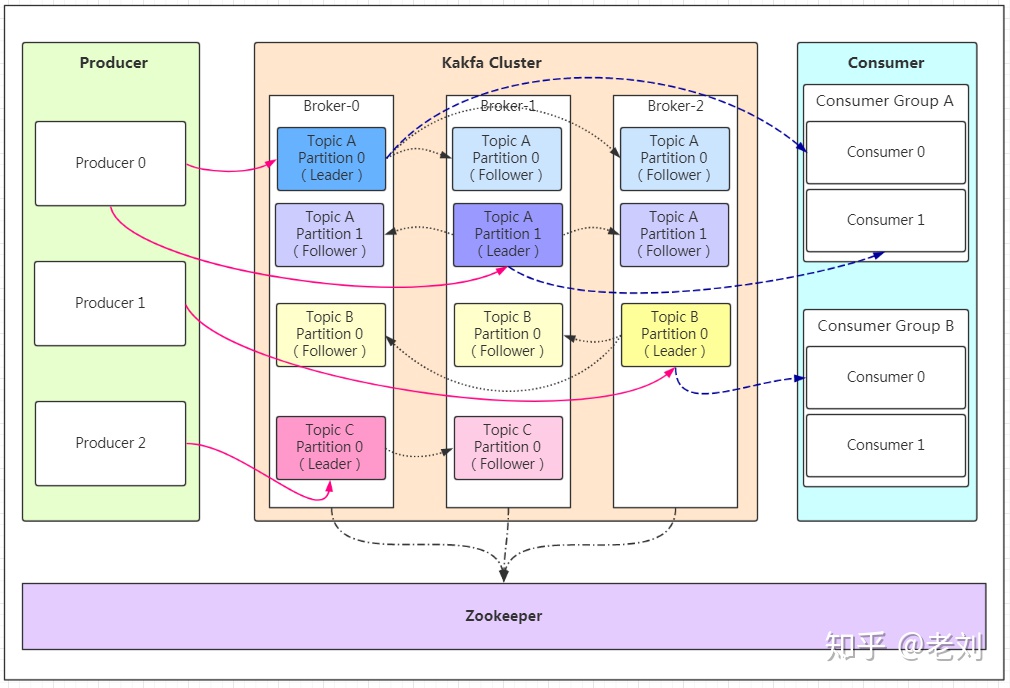
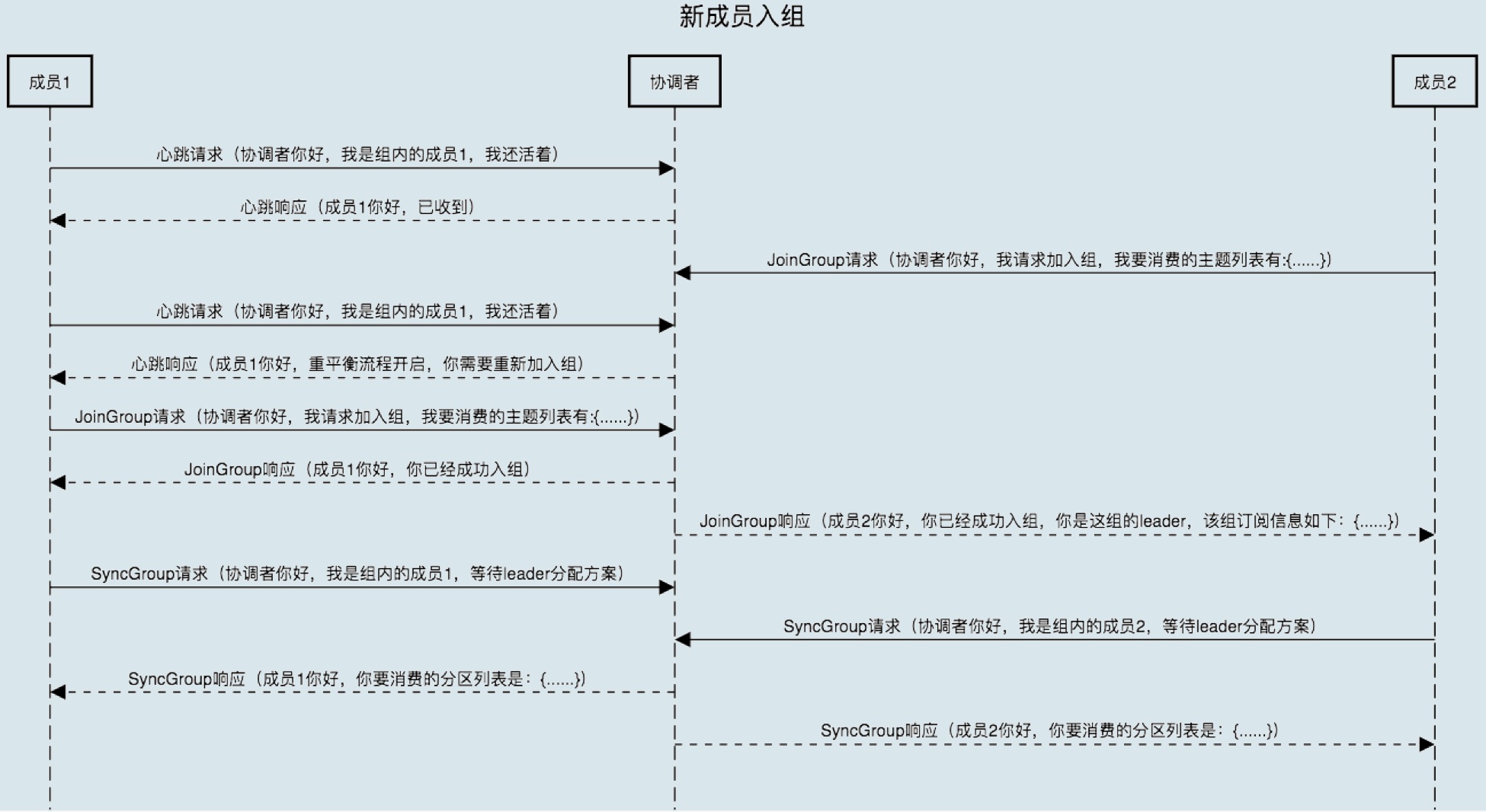
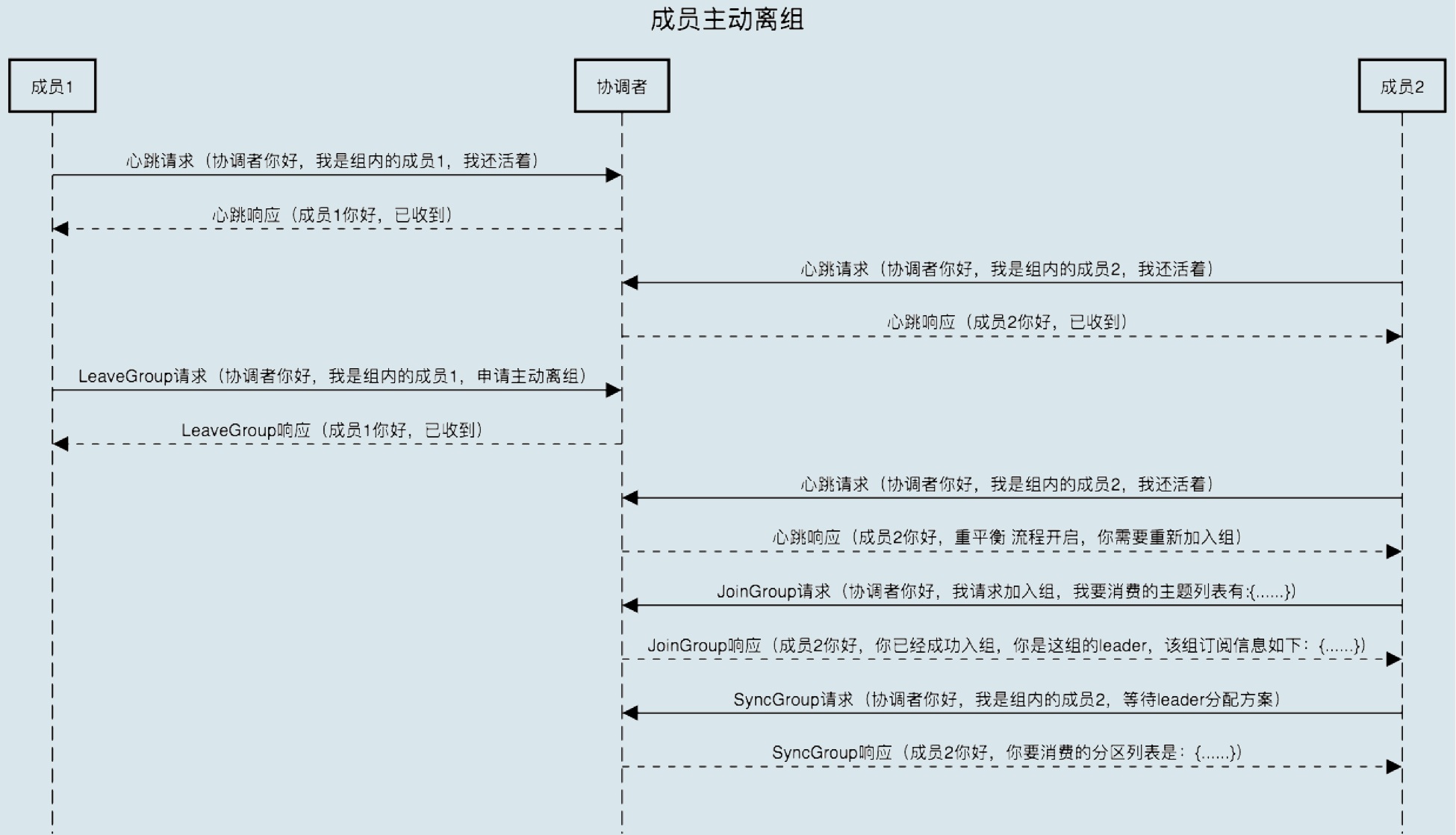
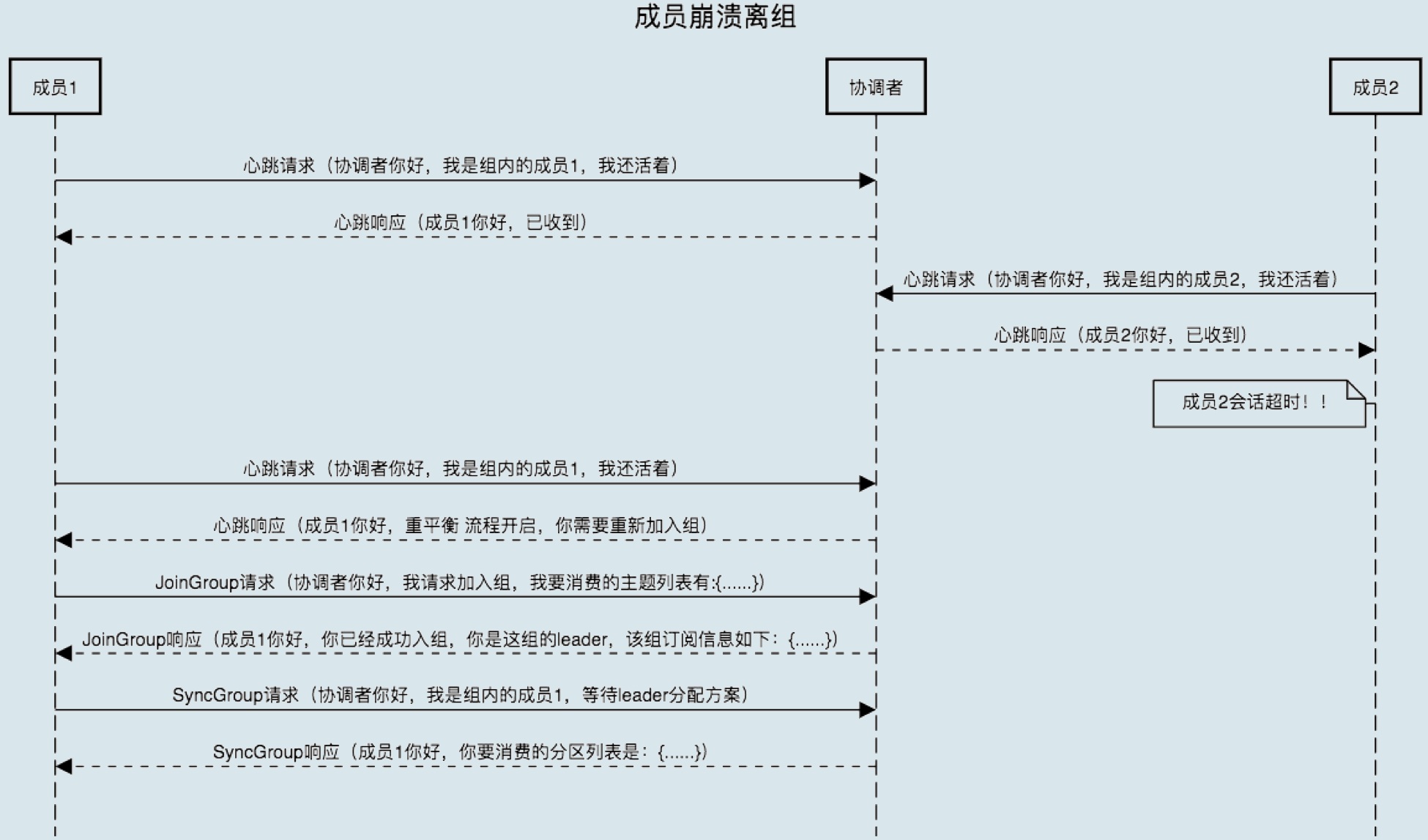
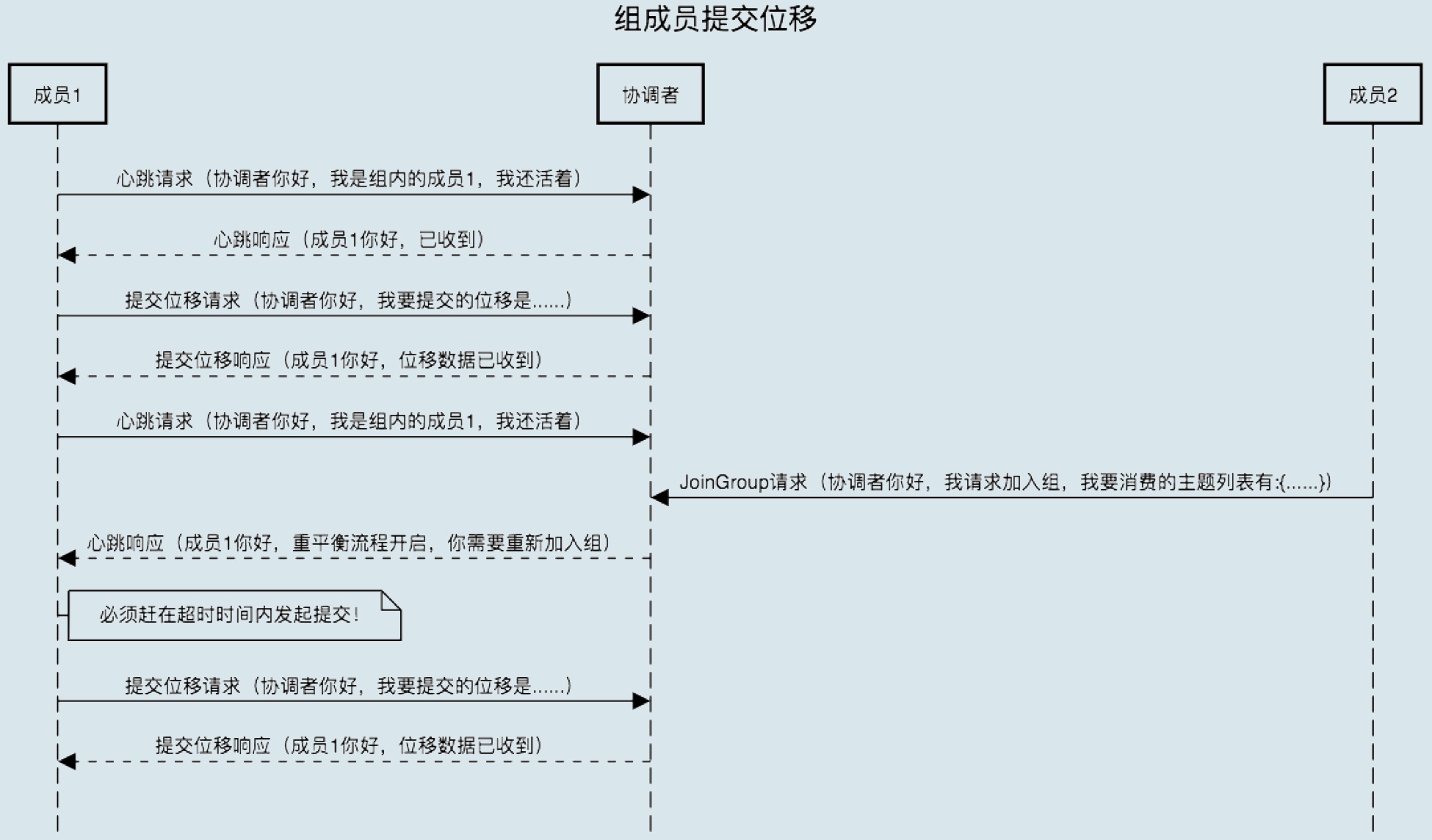
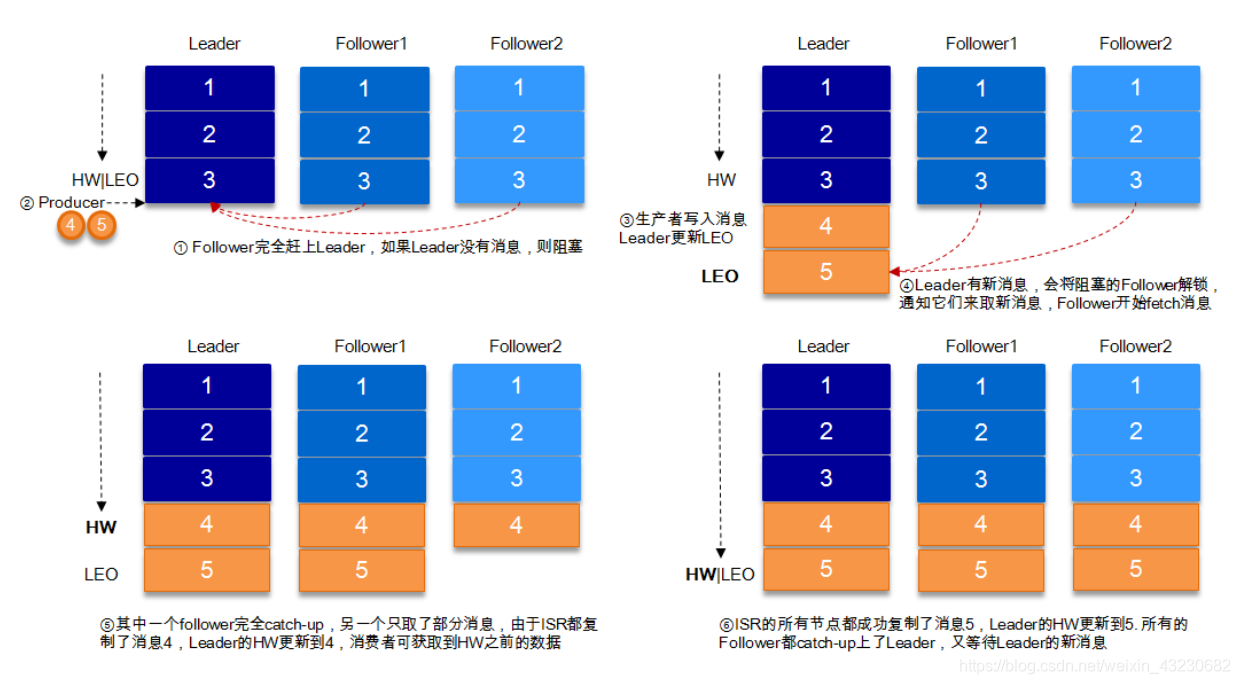
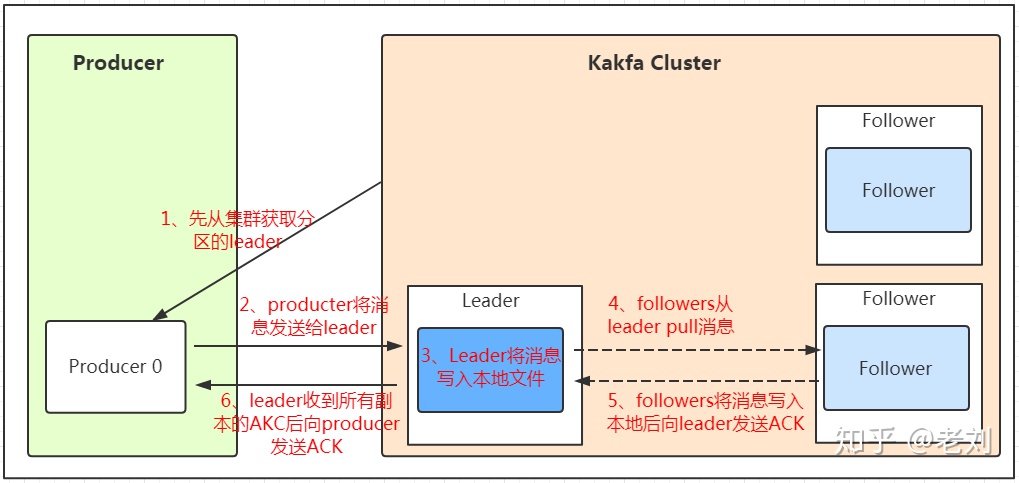
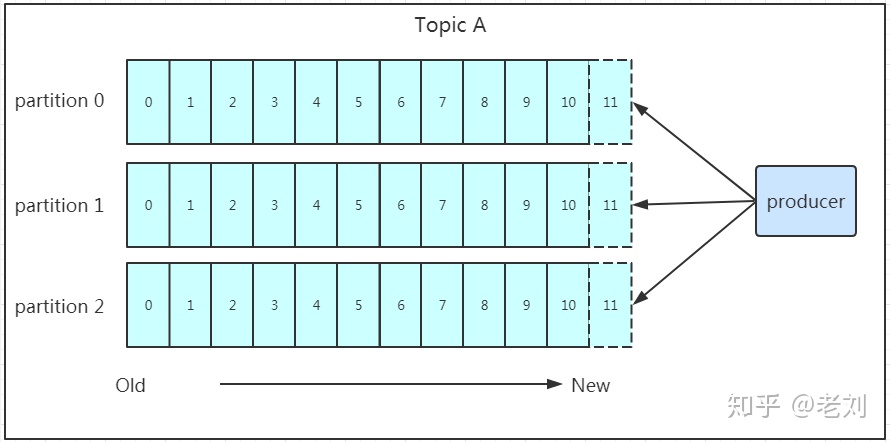
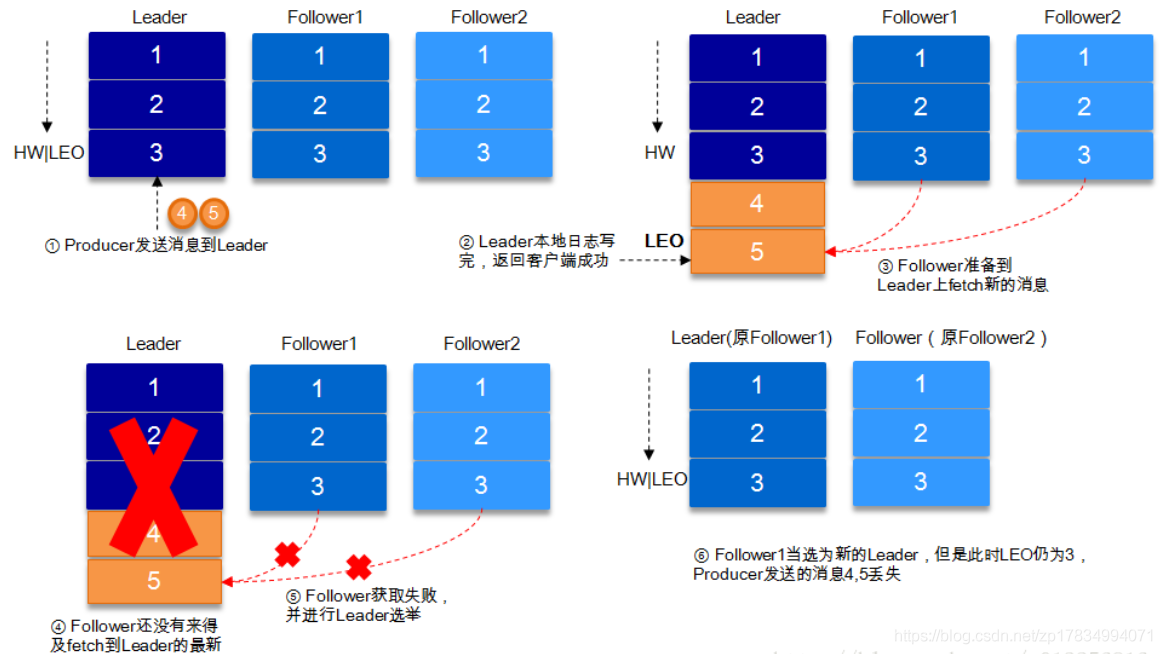
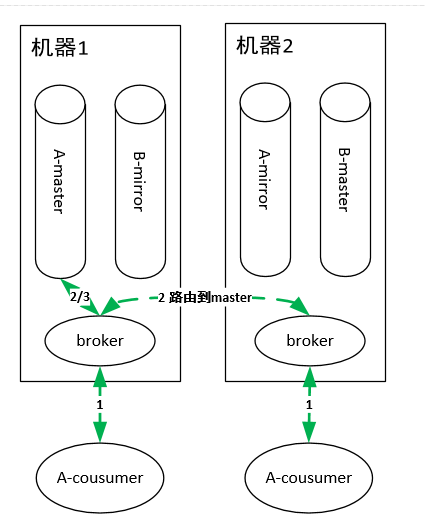
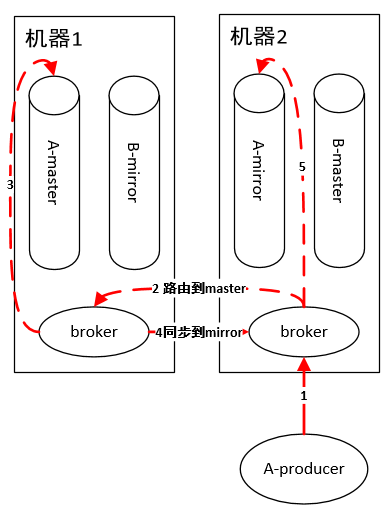
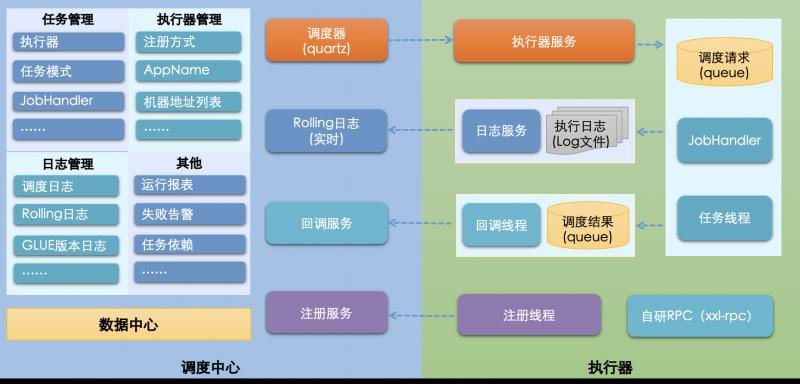
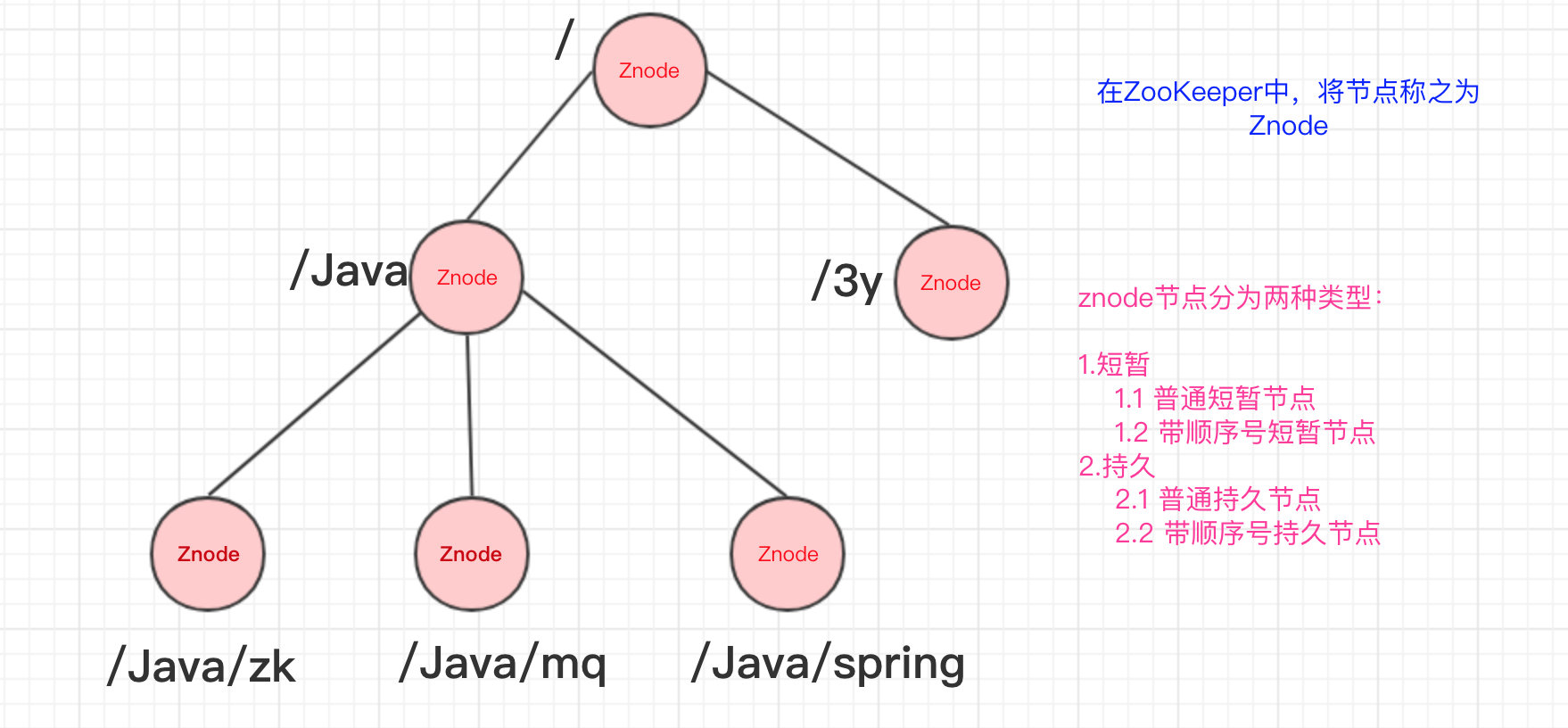
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
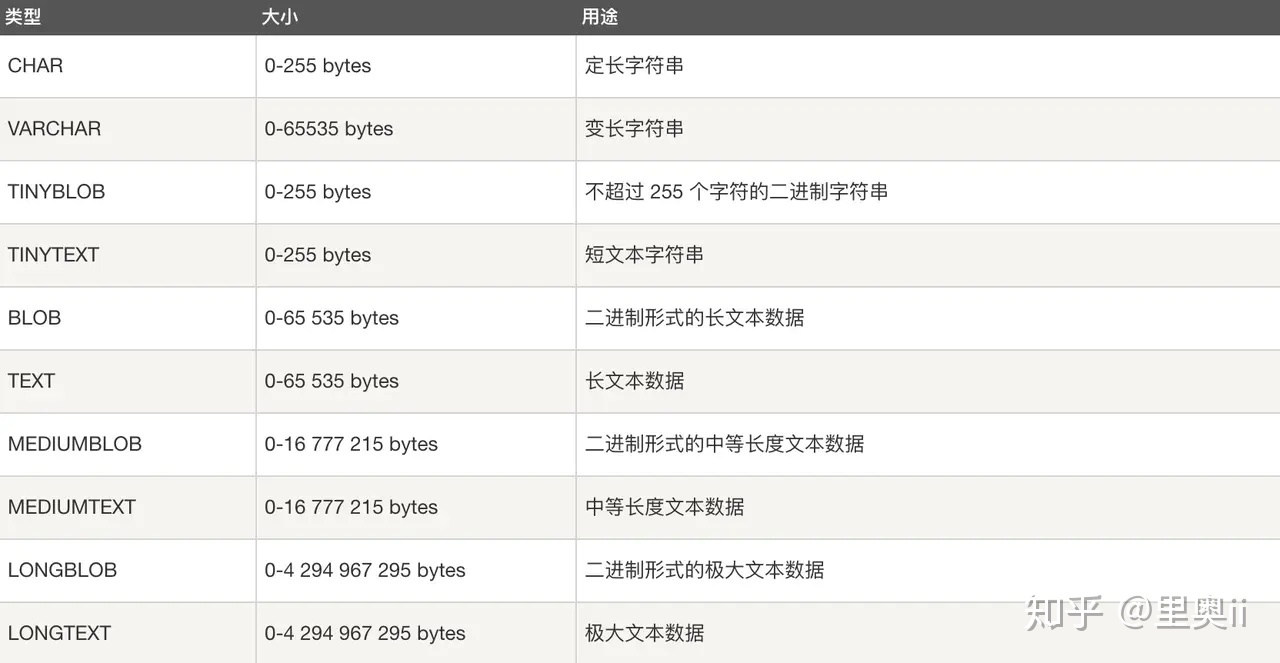
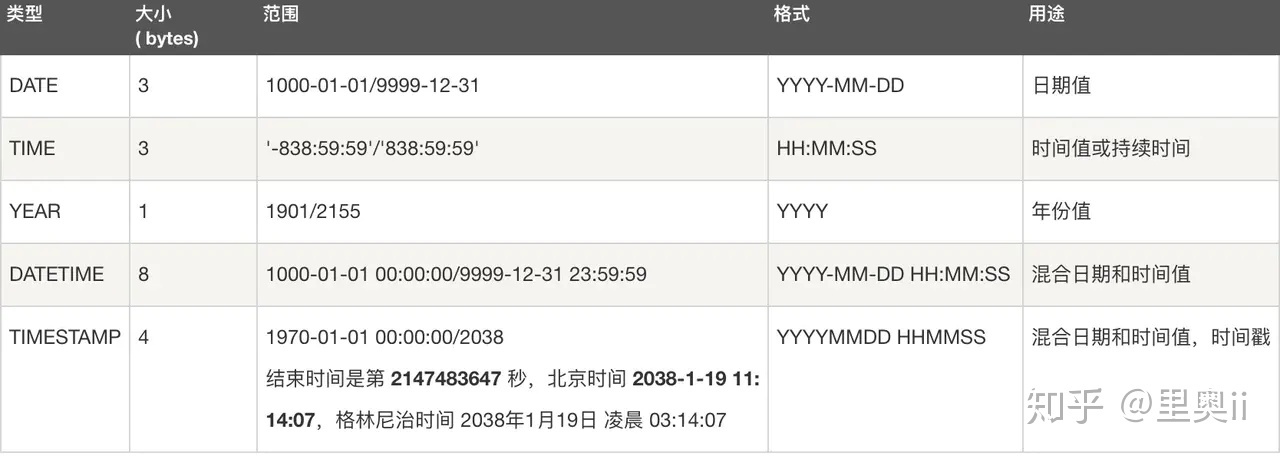
| - 版本区别
- Redis3.2 之前,统一使用一个版本的 sdshdr。
- Redis3.2 开始,对数据结构做出了修改,针对不同的长度范围定义了不同的结构。
- sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用于存储不同的长度的字符串,分别代表 $2^5=32B$,$2^8=256B$,$2^16=64KB$,$2^32=4GB$,$2^64$ 约等于无穷大,但实际官方字符串 value 最大值为 512M。
- 版本区别
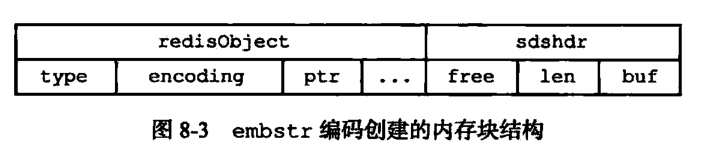
- Redis 的 embstr 编码方式和 raw 编码方式在 3.0 版本之前是以 39 字节为分界的
- 在 3.2 版本之后,则变成了 44 字节为分界
- 在 44 字节以内,使用 embstr 实现
- 超过了 44 字节,使用 raw 存储
- 相关问题
- **Redis 字符串与 C 语言中的字符串区别?**
- 复杂度问题
- SDS 由于存储了 len 属性,所以获取字符长度的时间复杂度为 $O(1)$,而 C 字符串并不记录本身长度,故获取字符串长度需要遍历整个字符串,直到遇到空字符,时间复杂度为 $O(N)$。
- 内存分配释放策略
- SDS 是预分配+惰性释放
- SDS 的内存分配策略:
- 如果对 SDS 字符串修改后,len 的值小于 1MB,那么程序会分配和 len 同样大小的空间,此时 len 和 free 的值是相同的,例如,如果 SDS 的字符串长度修改为 15 字节,那么会分配 15 字节空间给 free,SDS 的 buf 属性长度为 15(len)+15(free)+1(空字符)= 31 字节。
- 如果SDS字符串修改后,len 大于等于 1MB,那么程序会分配 1MB 的空间给 free,例如,SDS 字符串长度修改为 50MB 那么程序会分配 1MB 的未使用空间给 free,SDS 的 buf 属性长度为 50MB(len)+1MB(free)+1byte(空字符)。
- SDS 的内存释放策略:
- 当需要缩短 SDS 字符串时,程序并不立刻将内存释放,而是使用 free 属性将这些空间记录下来,以备将来使用。
- 缓冲区溢出问题
- SDS 的字符串的内存预分配策略能有效避免缓冲区溢出问题
- C 字符串每次操作增加长度时,都要分配足够长度的内存空间,否则就会产生缓冲区溢出(buffer overflow)。
- 二进制安全问题
- SDS 字符串 API 都是以处理二进制的方式处理 buf 数组里的数据,程序不会对其中的数据进行过滤、操作等,所以 SDS 是二进制数据安全的。
- C 字符串的字符则必须符合某种编码(ASCII),并且字符串的中间不能包含空字符,否则字符串就会被截断,所以 C 字符串智能保存文本数据,而不能保存图片、音视频等数据类型。
- **为什么 Redis 的 embstr 与 raw 编码方式不再以 39 字节为界?**
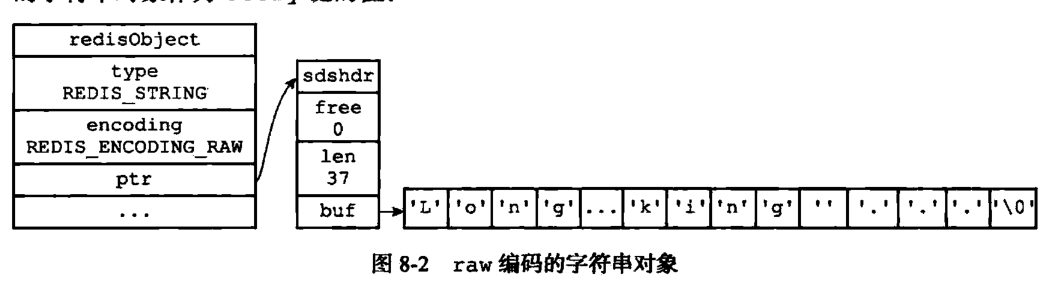
- embstr 是一块连续的内存区域,由 redisObject 和 sdshdr 组成。其中 redisObject 占 16 个字节,当 buf 内的字符串长度是 39 时,sdshdr 的大小为 8+39+1=48,那一个字节是'\0'。加起来刚好 64。
- 从 2.4 版本开始,redis 开始使用 jemalloc 内存分配器。这个比 glibc 的 malloc 要好不少,还省内存。在这里可以简单理解,jemalloc 会分配 8,16,32,64 等字节的内存。embstr 最小为 16+8+8+1=33,所以最小分配 64 字节。当字符数小于 39 时,都会分配 64 字节。这个默认 39 就是这样来的。
- 本身就是针对短字符串的 embstr 自然会使用最小的 sdshdr8,而 sdshdr8 与之前的 sdshdr 相比正好减少了 5 个字节(sdsdr8 = uint8_t * 2 + char = 1*2+1 = 3, sdshdr = unsigned int * 2 = 4 * 2 = 8),所以其能容纳的字符串长度增加了 5 个字节变成了 44。
- list(列表)
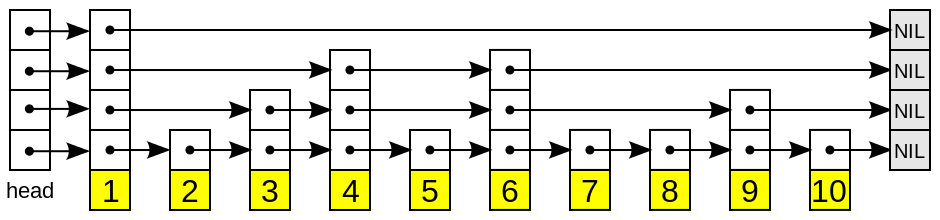
- Redis 链表是一个双向无环链表结构,可以通过 push 和 pop 操作从列表的头部或者尾部添加或者删除元素,这样 list 即可以作为栈,也可以作为队列。很多发布订阅、慢查询、监视器功能都是使用到了链表来实现。
- 原理
- 底层有 linkedList、zipList 和 quickList 这三种存储方式。
- 数据结构
- linkedList、zipList
- 当列表对象中元素的长度较小或者数量较少时,通常采用 zipList 来存储;当列表中元素的长度较大或者数量比较多的时候,则会转而使用双向链表 linkedList 来存储。
- 双向链表 linkedList 便于在表的两端进行 push 和 pop 操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还有额外保存两个指针;其次,双向链表的各个节点都是单独的内存块,地址不连续,容易形成内存碎片。
- zipList 存储在一块连续的内存上,所以存储效率很高。但是它不利于修改操作,插入和删除操作需要频繁地申请和释放内存。特别是当 zipList 长度很长时,一次 realloc 可能会导致大量的数据拷贝。
- quickList
- 在 Redis3.2 版本之后,list 的底层实现方式又多了一种,quickList。qucikList 是由 zipList 和双向链表 linkedList 组成的混合体。它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
- 
- hash(散列)
- hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
- 原理
- 哈希对象的编码有两种,分别是:ziplist、dict。
- 数据结构
- ziplist
- 使用压缩列表实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的节点推入到压缩列表的表尾,然后再将保存了值的节点推入到压缩列表表尾。
- 
- dict
- 使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值来保存,跟 java 中的 HashMap 类似。
- 
- 切换条件
- 当哈希对象保存的键值对数量小于 512,并且所有键值对的长度都小于 64 字节时,使用压缩列表存储;否则使用 dict 存储。
- 扩容流程(渐进式 rehash)
1. 计算新表 size、掩码,为新表 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
2. 将 rehash 索引计数器变量 rehashidx 的值设置为 0,表示 rehash 正式开始。
3. rehash 进行期间,每次对字典执行添加、删除、査找、更新操作时,程序除了执行指定的操作以外,还会触发额外的 rehash 操作,在源码中的 _dictRehashStep 方法。
- 该方法会从 ht[0] 表的 rehashidx 索引位置上开始向后查找,找到第一个不为空的索引位置,将该索引位置的所有节点 rehash 到 ht[1],当本次 rehash 工作完成之后,将 ht[0] 索引位置为 rehashidx 的节点清空,同时将 rehashidx 属性的值加一。
4. 将 rehash 分摊到每个操作上确实是非常妙的方式,但是万一此时服务器比较空闲,一直没有什么操作,难道 redis 要一直持有两个哈希表吗?
- 答案当然不是的。我们知道,redis 除了文件事件外,还有时间事件,redis 会定期触发时间事件,这些时间事件用于执行一些后台操作,其中就包含 rehash 操作:当 redis 发现有字典正在进行 rehash 操作时,会花费 1 毫秒的时间,一起帮忙进行 rehash。
5. 随着操作的不断执行,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 至 ht[1],此时 rehash 流程完成,会执行最后的清理工作:释放 ht[0] 的空间、将 ht[0] 指向 ht[1]、重置 ht[1]、重置 rehashidx 的值为 -1。
- sets(集合)
- Redis 提供的 set 数据结构,可以存储一些集合性的数据。set 中的元素是没有顺序的。
- 原理
- 集合对象的编码有两种,分别是:intset、dict。
- 切换条件
- set 的底层存储 intset 和 dict 是存在编码转换的,使用 intset 存储必须满足下面两个条件,否则使用 dict,条件如下:
- 结合对象保存的所有元素都是整数值
- 集合对象保存的元素数量不超过 512 个
- sorted set(有序集合)
- sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列
- 原理
- 底层数据结有序集合对象的编码有两种,分别是:ziplist、skiplist。
- 数据结构
- ziplist
- 当保存的元素长度都小于 64 字节,同时数量小于 128 时,使用该编码方式,否则会使用 skiplist。
- 
- skiplist
- zset 实现,一个 zset 同时包含一个字典(dict)和一个跳跃表(zskiplist)
- 
- 切换条件
- 当有序集合的长度小于 128,并且所有元素的长度都小于 64 字节时,使用压缩列表存储;否则使用 skiplist 存储。
### 高级
- HyperLogLog
- 通常用于基数统计。使用少量固定大小的内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是一个带有 0.81% 标准差(standard error)的近似值。
- HyperLogLog 适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的 UV 统计。
- 在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
- 基数
- 比如数据集 `{1, 3, 5, 7, 5, 7, 8}`,那么这个数据集的基数集为 `{1, 3, 5 ,7, 8}`, 基数(不重复元素)为 5。基数估计就是在误差可接受的范围内,快速计算基数。
- Geo
- 可以将用户给定的地理位置信息储存起来,并对这些信息进行操作:获取 2 个位置的距离、根据给定地理位置坐标获取指定范围内的地理位置集合。
- Bitmap
- 位图。
- Stream
- 主要用于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
### 原理
- RedisObject
- 为了便于操作,Redis 定义了 RedisObject 结构体来表示 string、hash、list、set、zset 五种数据类型。
- 
- 结构
- 源码
- ```
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 对齐位
unsigned notused:2;
// 编码方式
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock)
unsigned lru:22;
// 引用计数
int refcount;
// 指向对象的值
void *ptr;
} robj;
|