- 进程管理
- 进程和线程
- 进程
- 进程是具有一定功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源调度和分配的一个独立单位。
- 进程的通信方式
- 管道
- 管道是一种半双工的通信方式,数据只能单项流动,并且只能在具有亲缘关系的进程间流动,进程的亲缘关系通常是父子进程
- 分类
- 普通管道 PIPE
- 流管道(s_pipe)
- 命名管道(name_pipe)
- 命名管道也是半双工的通信方式,它允许无亲缘关系的进程间进行通信
- 系统 IPC(包括消息队列、信号量、共享存储)
- 信号量是一个计数器,用来控制多个进程对资源的访问,它通常作为一种锁机制。
- 消息队列是消息的链表,存放在内核中并由消息队列标识符标识。
- 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 共享内存就是映射一段能被其它进程访问的内存,这段共享内存由一个进程创建,但是多个进程可以访问。
- SOCKET
- 管道
- 进程同步机制
- 原子操作
- 信号量机制
- 自旋锁管程
- 会合
- 分布式系统
- 进程调度策略
- FCFS(先来先服务)
- 该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列。在进程调度中采用 FCFS 算法时,则每次调度是从就绪队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行。该进程一直运行到完成或发生某事件而阻塞后才放弃处理机。
- 优先级
- 短作业(进程)优先调度算法
- 短作业(进程)优先调度算法 SJ(P)F,是指对短作业或短进程优先调度的算法。它们可以分别用于作业调度和进程调度。短作业优先(SJF)的调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。而短进程优先(SPF)调度算法则是从就绪队列中选出一个估计运行时间最短的进程,将处理机分配给它,使它立即执行并一直执行到完成,或发生某事件而被阻塞放弃处理机时再重新调度。
- 高优先权优先调度算法
- 优先权调度算法的类型
- 非抢占式优先权算法
- 在这种方式下,系统一旦把处理机分配给就绪队列中优先权最高的进程后,该进程便一直执行下去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可再将处理机重新分配给另一优先权最高的进程。这种调度算法主要用于批处理系统中;也可用于某些对实时性要求不严的实时系统中。
- 抢占式优先权调度算法
- 在这种方式下,系统同样是把处理机分配给优先权最高的进程,使之执行。但在其执行期间,只要又出现了另一个其优先权更高的进程,进程调度程序就立即停止当前进程(原优先权最高的进程)的执行,重新将处理机分配给新到的优先权最高的进程。
- 非抢占式优先权算法
- 高响应比优先调度算法
- 在批处理系统中,短作业优先算法是一种比较好的算法,其主要的不足之处是长作业的运行得不到保证。如果我们能为每个作业引入动态优先权,并使作业的优先级随着等待时间的增加而以速率 a 提高,则长作业在等待一定的时间后,必然有机会分配到处理机。
- 优先权调度算法的类型
- 短作业(进程)优先调度算法
- 时间片轮转
- 在早期的时间片轮转法中,系统将所有的就绪进程按先来先服务的原则排成一个队列,每次调度时,把 CPU 分配给队首进程,并令其执行一个时间片。时间片的大小从几 ms 到几百 ms。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾;然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间。换言之,系统能在给定的时间内响应所有用户的请求。
- 多级反馈
- 前面介绍的各种用作进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。
- 实施过程
- 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第 i+1 个队列的时间片要比第 i 个队列的时间片长一倍。
- 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地按 FCFS 原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第 n 队列后,在第 n 队列便采取按时间片轮转的方式运行。
- 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第 1~(i-1) 队列均空时,才会调度第 i 队列中的进程运行。如果处理机正在第 i 队列中为某进程服务时,又有新进程进入优先权较高的队列(第 1~(i-1) 中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第 i 队列的末尾,把处理机分配给新到的高优先权进程。
- FCFS(先来先服务)
- 进程的 5 种状态及转换过程

- 就绪状态:进程已获得除处理机以外的所需资源,等待分配处理机资源
- 运行状态:占用处理机资源运行,处于此状态的进程数小于等于 CPU 数
- 阻塞状态:进程等待某种条件,在条件满足之前无法执行
- 线程
- 线程是进程的实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
- 线程同步的方式
- 互斥量(CMutex)
- 采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。
- 信号量(CSemphore)
- 它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
- 事件(信号)
- 通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
- 互斥量(CMutex)
- 线程与进程的区别
- 因为进程拥有独立的堆栈空间和数据段,所以每当启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这对于多进程来说十分“奢侈”,系统开销比较大,而线程不一样,线程拥有独立的堆栈空间,但是共享数据段,它们彼此之间使用相同的地址空间,共享大部分数据,比进程更节俭,开销比较小,切换速度也比进程快,效率高,但是正由于进程之间独立的特点,使得进程安全性比较高,也因为进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。一个线程死掉就等于整个进程死掉。
- 体现在通信机制上面,正因为进程之间互不干扰,相互独立,进程的通信机制相对很复杂,譬如管道,信号,消息队列,共享内存,套接字等通信机制,而线程由于共享数据段所以通信机制很方便。
- 体现在 CPU 系统上面,线程使得 CPU 系统更加有效,因为操作系统会保证当线程数不大于 CPU 数目时,不同的线程运行于不同的 CPU 上。
- 体现在程序结构上,举一个简明易懂的列子:当我们使用进程的时候,我们不自主的使用 if else 嵌套来判断 pid,使得程序结构繁琐,但是当我们使用线程的时候,基本上可以甩掉它,当然程序内部执行功能单元需要使用的时候还是要使用,所以线程对程序结构的改善有很大帮助。
- 进程
- 同步和互斥
- 同步是多个进程因为合作而使得进程的执行有一定的先后顺序。比如某个进程需要另一个进程提供的消息,获得消息之前进入阻塞态;
- 互斥是多个进程在同一时刻只有一个进程能进入临界区。
- 饥饿与死锁
- 饥饿
- 指一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行的状态;
- 死锁
- 指两个或两个以上的进程/线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
- 产生的四个条件(有一个条件不成立,则不会产生死锁)
- 互斥条件
- 一个资源一次只能被一个进程使用
- 请求与保持条件
- 一个进程因请求资源而阻塞时,对已获得资源保持不放
- 不剥夺条件
- 进程获得的资源,在未完全使用完之前,不能强行剥夺
- 循环等待条件
- 若干进程之间形成一种头尾相接的环形等待资源关系
- 互斥条件
- 解决死锁的基本方法
- 预防死锁
- 资源一次性分配:(破坏请求和保持条件)
- 可剥夺资源:即当某进程新的资源未满足时,释放已占有的资源(破坏不可剥夺条件)
- 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
- 避免死锁
- 预防死锁的几种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从而获得较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因而,系统在进行资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进入不安全状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银行家算法。
- 银行家算法如何解题?
- 列出各个资源的剩余情况,再列出各个进程完成需要的资源情况,最后根据前两种情况判断哪个进程可以执行完,执行完进程后会释放资源,再重复以上步骤即可。
- 银行家算法如何解题?
- 预防死锁的几种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从而获得较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因而,系统在进行资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进入不安全状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银行家算法。
- 检测死锁
- 首先为每个进程和每个资源指定一个唯一的号码;然后建立资源分配表和进程等待表。
- 解除死锁
- 当发现有进程死锁后,便应立即把它从死锁状态中解脱出来,常采用的方法有:
- 剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
- 撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态.消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
- 当发现有进程死锁后,便应立即把它从死锁状态中解脱出来,常采用的方法有:
- 预防死锁
- 解决死锁的常用策略
- 鸵鸟策略、预防策略、避免策略、检测与解除死锁
- 饥饿
- 进程和线程
- 内存管理
- 分页和分段
- 段是信息的逻辑单位,它是根据用户的需要划分的,因此段对用户是可见的;页是信息的物理单位,是为了管理主存的方便而划分的,对用户是透明的。
- 段的大小不固定,有它所完成的功能决定;页大大小固定,由系统决定
- 段向用户提供二维地址空间;页向用户提供的是一维地址空间
- 段是信息的逻辑单位,便于存储保护和信息的共享,页的保护和共享受到限制。
- 将用户程序变为可在内存中执行的程序的步骤
- 编译
- 链接
- 装入
- 程序的装入方式
- 绝对装入
- 动态运行装入
- 可重定位装入
- 内存连续分配管理方式
- 单一连续分配
- 固定分区分配
- 动态分区分配
- 页面置换算法
- 最佳置换算法
- 先进先出置换算法
- 最近最久未使用算法
- 时钟置换算法
- 堆栈(stack)、堆(heap)
- 栈
- 用户维护函数调用上下文。由高地址向低地址生长,通常以M为单位,由操作系统维护。
- 保存了一个函数调用所需要维护的信息,称为活动记录,包括
- 函数的返回地址,参数
- 临时变量
- 上下文:寄存器
- 空间管理
- 栈(英文名称是 stack)是系统自动分配空间的,例如我们定义一个
char a;系统会自动在栈上为其开辟空间 - 栈上的空间是自动分配自动回收的
- 栈(英文名称是 stack)是系统自动分配空间的,例如我们定义一个
- 栈上的数据的生存周期只是在函数的运行过程中,运行后就释放掉,不可以再访问
- 堆
- 空间管理
- 动态申请内存,即使用 new or malloc 等分配到的内存,可以比栈大很多,需用户自己释放
- malloc
- 对于申请内存这种特权操作,肯定是操作系统内核来做比较合适,但是频繁的进行系统调用,在用户态和内核态之间切换,也就是频繁的调用中断处理程序,性能是较差的。所以,事实上都是通过 c 语言的运行库封装好的库函数,预申请一块设当的内存,然后零售给程序用,可以采用空闲链表或者位图等来管理。这取决于运行库的实现了。
- malloc
- 动态申请内存,即使用 new or malloc 等分配到的内存,可以比栈大很多,需用户自己释放
- 堆上的数据只要程序员不释放空间,就一直可以访问到,不过缺点是一旦忘记释放会造成内存泄露。
- 空间管理
- 栈
- 分页和分段
- 文件管理
- 磁盘调度算法(先来先服务算法、最短寻道时间优先算法、扫描算法、循环扫描算法)
- I/O 管理
- I/O 控制方式
- 程序 I/O 方式
- 这种方式下,CPU 通过 I/O 指令询问指定外设当前的状态,如果外设准备就绪,则进行数据的输入或输出,否则 CPU 等待,循环查询。
- 中断驱动方式
- 每次中断均需保存断点(返回地址)和现场(各寄存器的值,包括标志寄存器),中断返回时,要恢复断点和现场。
- DMA 方式
- DMA(Direct Memory Access,直接存储器访问)。在 DMA 出现之前,CPU 与外设之间的数据传送方式有程序传送方式、中断传送方式。CPU 是通过系统总线与其他部件连接并进行数据传输。
- DMA 方式在数据传送过程中,没有保存现场、恢复现场之类的工作。
- 由于 CPU 根本不参加传送操作,因此就省去了 CPU 取指令、取数、送数等操作。内存地址修改、传送字个数的计数等等,也不是由软件实现,而是用硬件线路直接实现的。所以 DMA 方式能满足高速 I/O 设备的要求,也有利于 CPU 效率的发挥。
- I/O 通道控制方式
- 通道是一个用来控制外部设备工作的硬件机制,相当于一个功能简单的处理机。通道是独立于 CPU 的、专门负责数据的输入输出传输工作的处理器,它对外部设备实统一管理,代替 CPU 对 I/O 操作进行控制,从而使 I/O 操作可以与 CPU 并行工作。通道是实现计算机和传输并行的基础,以提高整个系统的效率。
- 程序 I/O 方式
- Spooling 技术
- Spooling 技术能够缓和 CPU 和外设的速度,提高 I/O 速度,将独占设备转化为共享设备,并实现虚拟设备功能。
- I/O 控制方式
数据结构-0-知识点汇总.md
数据结构
树
- 前缀树(字典树)
- 前缀树又名字典树,单词查找树,Trie 树,是一种多路树形结构,是哈希树的变种,和hash效率有一拼,是一种用于快速检索的多叉树结构。
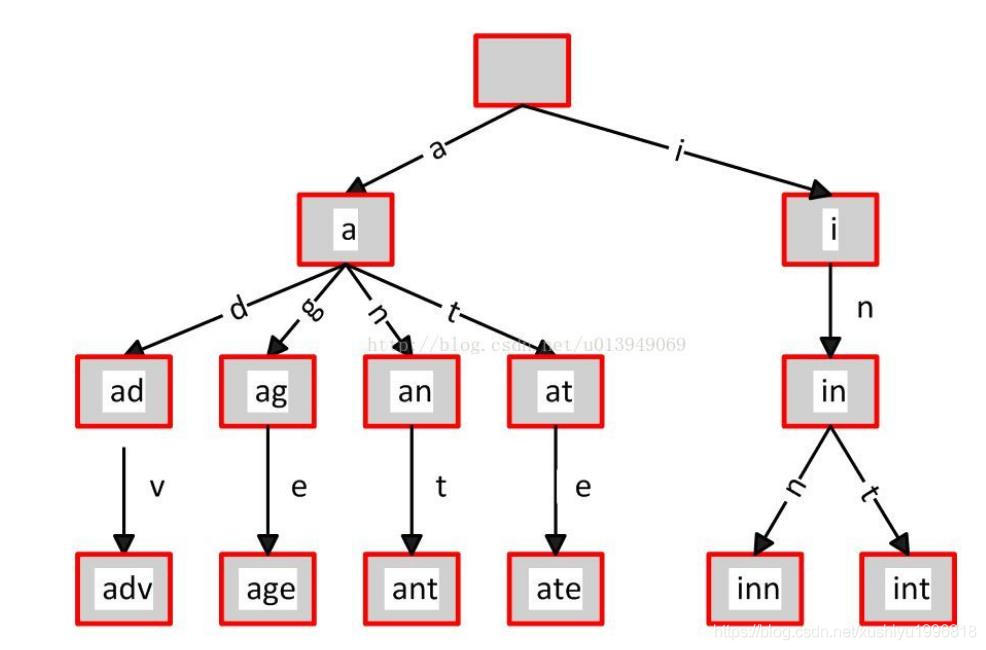
- 特性
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
- 从根节点到某一节点的路径上的字符连接起来,就是该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
- 每条边对应一个字母。每个节点对应一项前缀。叶节点对应最长前缀,即单词本身。
- 应用场景
- 字符串的快速检索
- 字符串排序
- 最长公共前缀
- 自动匹配前缀显示后缀
- B树
- 即二叉搜索树
- 结构特点
- 所有非叶子结点至多拥有两个儿子(Left 和 Right);
- 所有结点存储一个关键字;
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
- B-树
- B-tree,即 B树,而不要读成 B减树,它是一种多路搜索树(并不是二叉的)
- 结构特点
- 定义任意非叶子结点最多只有 M 个儿子;且 M>2;
- 根结点的儿子数为
[2, M]; - 除根结点以外的非叶子结点的儿子数为
[M/2, M]; - 每个结点存放至少 M/2-1(取上整)和至多 M-1 个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:
K[1], K[2], …, K[M-1];且K[i] < K[i+1]; - 非叶子结点的指针:
P[1], P[2], …, P[M];其中 P[1] 指向关键字小 于K[1] 的子树,P[M] 指向关键字大于 K[M-1] 的子树,其它 P[i] 指向关键字属于(K[i-1], K[i])的子树; - 所有叶子结点位于同一层;
- 特性
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
- 如果索引是采用 B 树结构存储的,所以对应的索引项并不会被删除,经过一段时间的增删改操作后,数据库中就会出现大量的存储碎片,这和磁盘碎片、内存碎片产生原理是类似的,这些存储碎片不仅占用了存储空间,而且降低了数据库运行的速度。如果发现索引中存在过多的存储碎片的话就要进行 “碎片整理”了,最方便的“碎片整理” 手段就是重建索引, 重建索引会将先前创建的索引删除然后重新创建索引
- B+树
- B+树是B-树的变体,也是一种多路搜索树
- 结构特点
- 其定义基本与 B-树同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针 P[i],指向关键字值属于
(K[i], K[i+1])的子树(B-树是开区间); - 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
- 其定义基本与 B-树同,除了:
- 特性
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
- 原因
- B+树空间利用率更高,因为 B+树的内部节点只是作为索引使用,而不像 B-树那样每个节点都需要存储硬盘指针。
- 增删文件(节点)时,效率更高,因为 B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
- 原因
- B*树
- 是 B+树的变体,在 B+树的非根和非叶子结点再增加指向兄弟的指针
- 平衡二叉树
- AVL 树
- 平衡二叉搜索树(Self-balancing binary search tree)又被称为 AVL 树(有别于 AVL 算法)
- 具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
- 红黑树
- 是一种平衡二叉树,但每个节点有一个存储位表示节点的颜色,可以是红或黑。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度<=红黑树),相对于要求严格的 AVL 树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,用红黑树。
- 对比
平衡二叉树类型 平衡度 调整频率 适用场景 AVL树 高 高 查询多,增/删少 红黑树 低 低 增/删频繁
- AVL 树
微积分-拉格朗日乘子法
转自:https://www.matongxue.com/madocs/939.html
与原点的最短距离
假如有方程: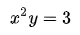
图像是这个样子滴: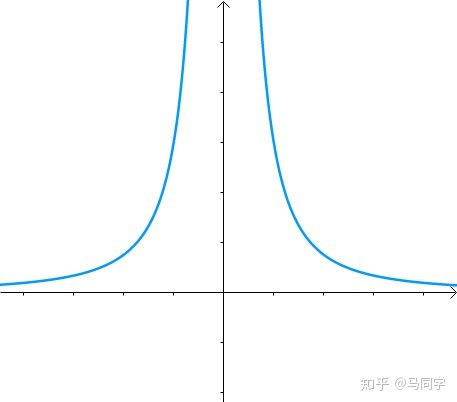
现在我们想求其上的点与原点的最短距离: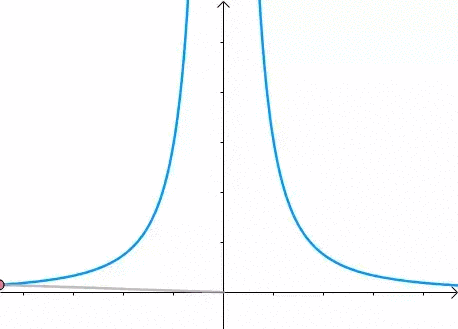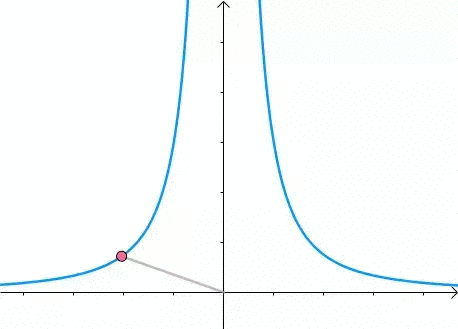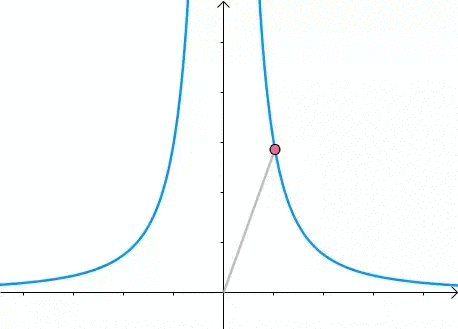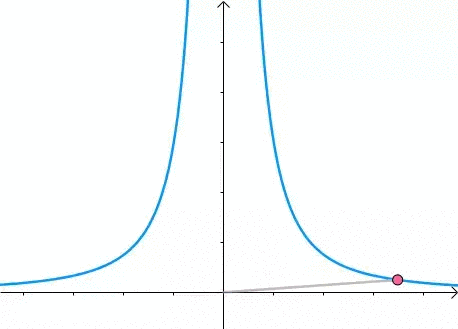
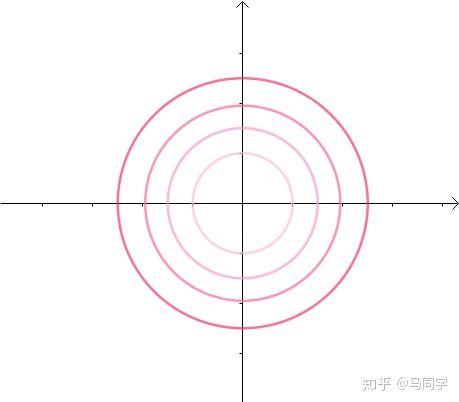
这里介绍一种解题思路。首先,与原点距离为 a 的点全部在半径为 a 的圆上: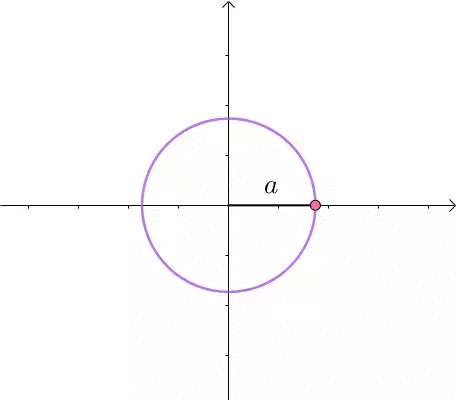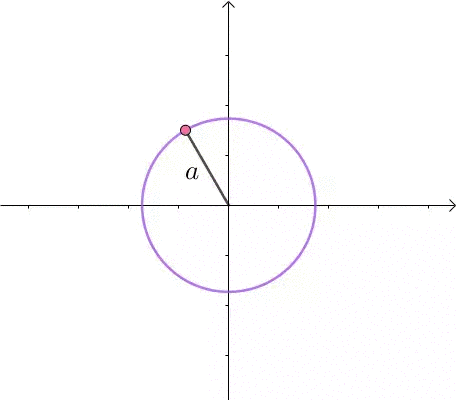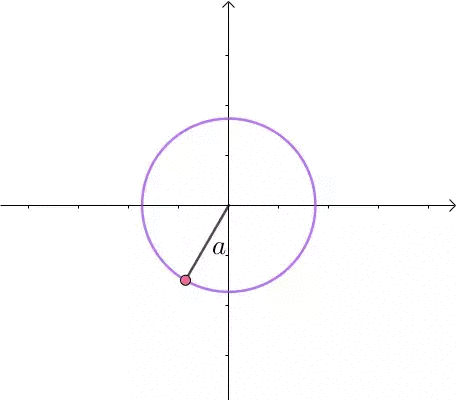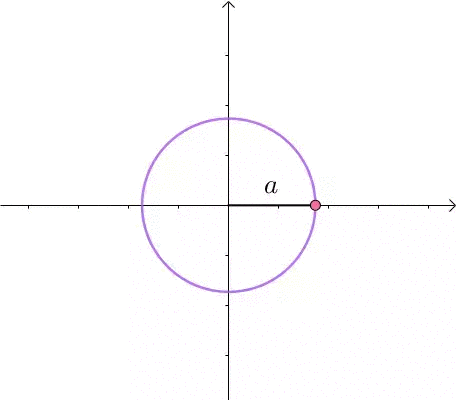
那么,我们逐渐扩大圆的半径: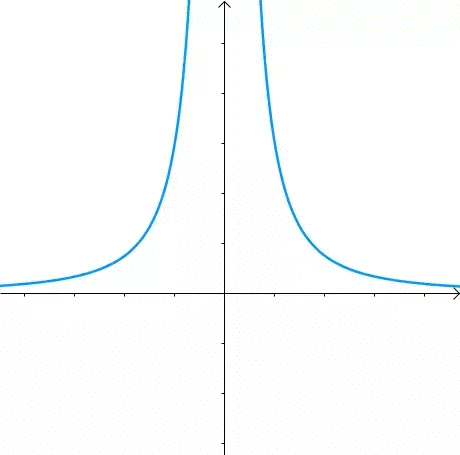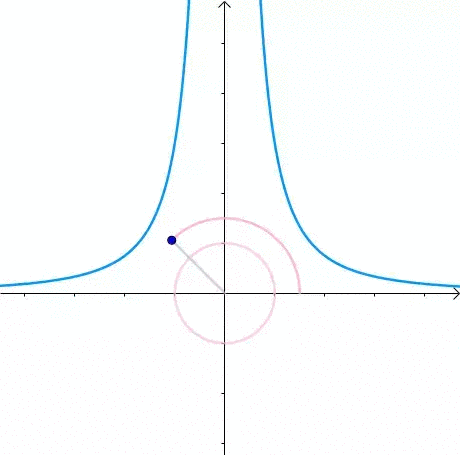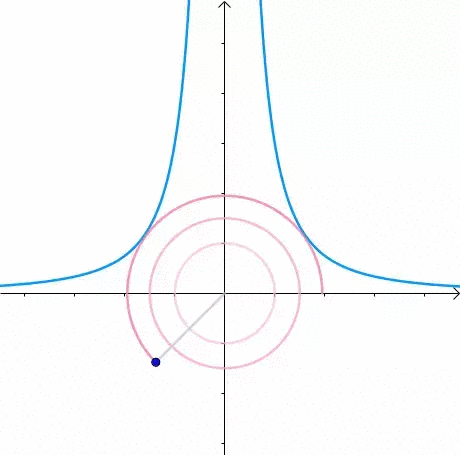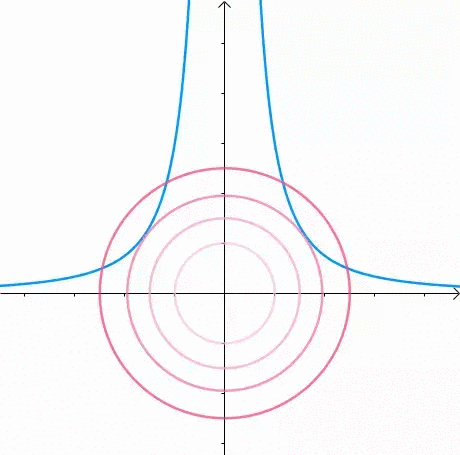
显然,第一次与 相交的点就是距离原点最近的点: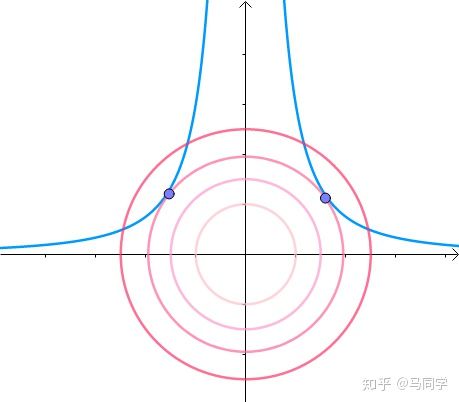
此时,圆和曲线相切,也就是在该点切线相同: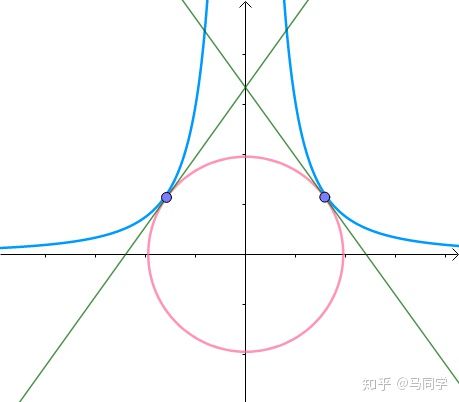
至此,我们分析出了:在极值点,圆与曲线相切
等高线
可以看作函数 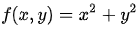 的等高线:
的等高线:
梯度向量: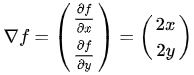
是等高线的法线: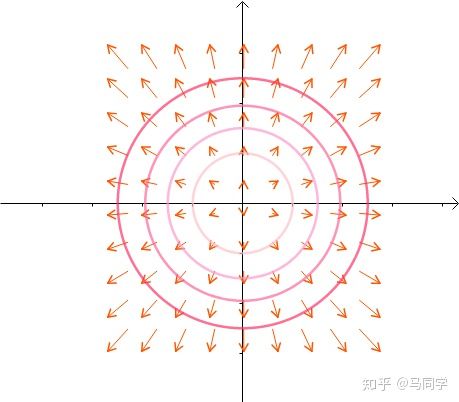
另外一个函数 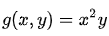 的等高线为:
的等高线为: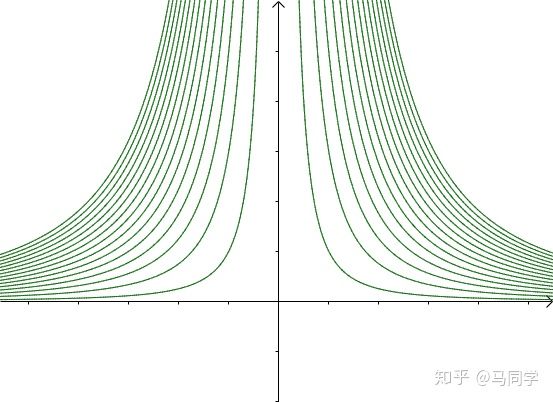
之前的曲线 就是其中值为3的等高线: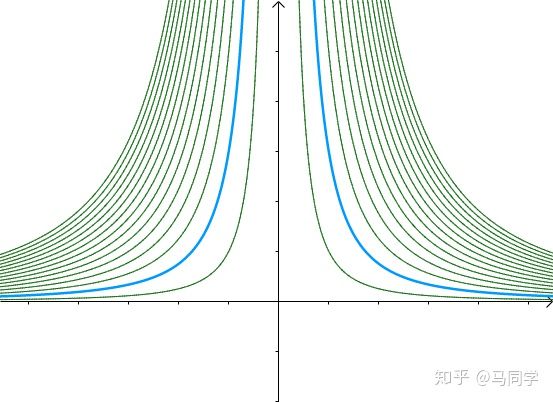
因此,梯度向量: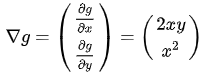
也垂直于等高线 :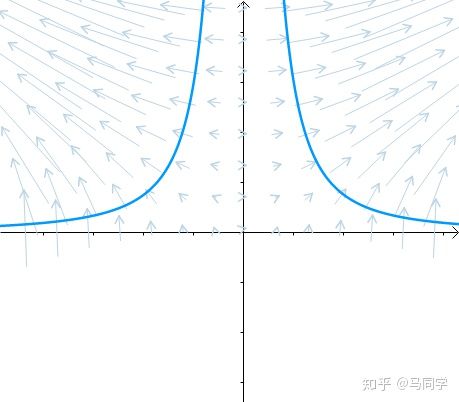
梯度向量是等高线的法线,更准确地表述是:梯度与等高线的切线垂直
拉格朗日乘子法
求解
根据之前的两个分析:
- 在极值点,圆与曲线相切
- 梯度与等高线的切线垂直
综合可知,在相切点,圆的梯度向量和曲线的梯度向量平行: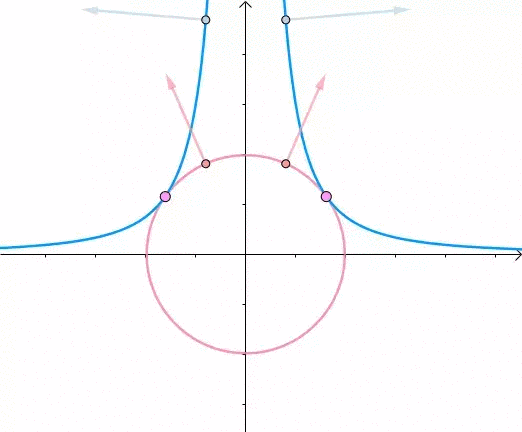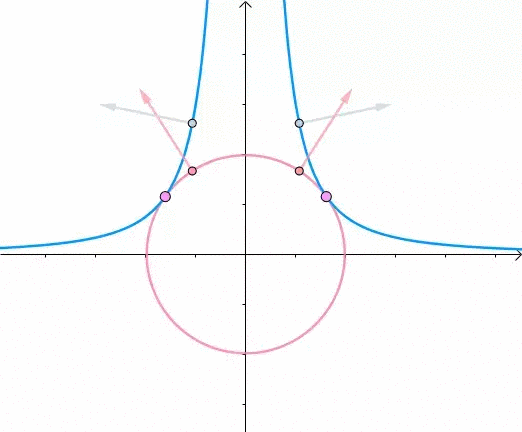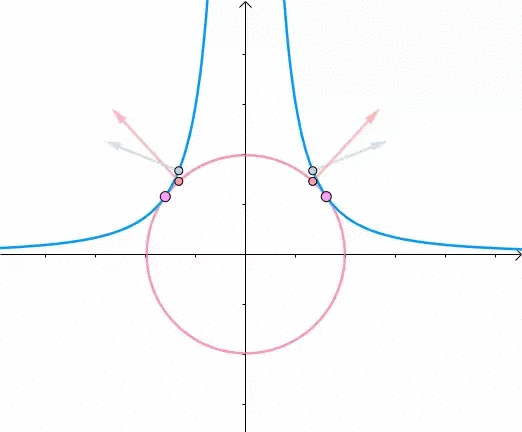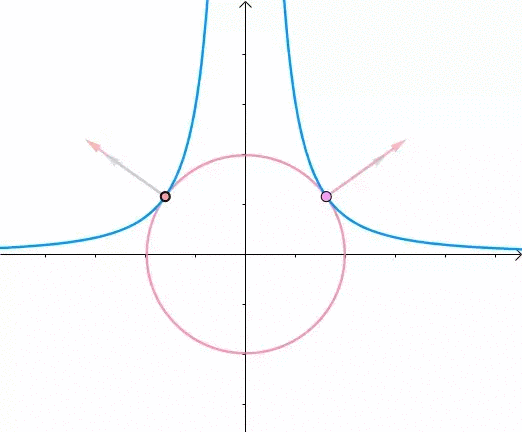
也就是梯度向量平行,用数学符号表示为: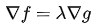
还必须引入 这个条件,否则这么多等高线,不知道指的是哪一根: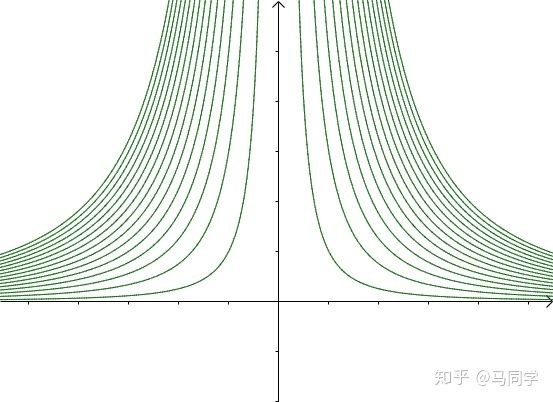
因此联立方程: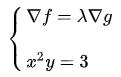
求一下试试: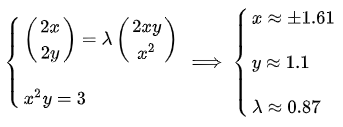
这就是拉格朗日乘子法。
定义
要求函数 f 在 g 约束下的极值这种问题可以表示为: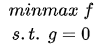
s.t. 意思是subject to,服从于,约束于的意思。
可以列出方程组进行求解: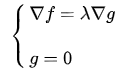
用这个定义来翻译下刚才的例子,要求:
令: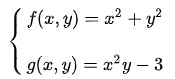
求: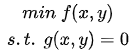
联立方程进行求解: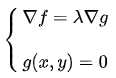
变形
这个定义还有种变形也比较常见,要求:
定义: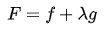
求解下面方程组即可得到答案: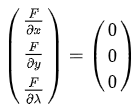
把等式左边的偏导算出来就和上面的定义是一样的了。
多个约束条件
如果增加一个约束条件呢?比如说: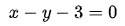
求: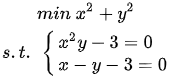
从图上看约束条件是这样的: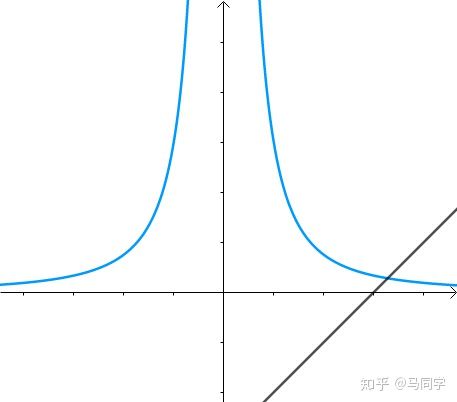
很显然所求的距离是这样的: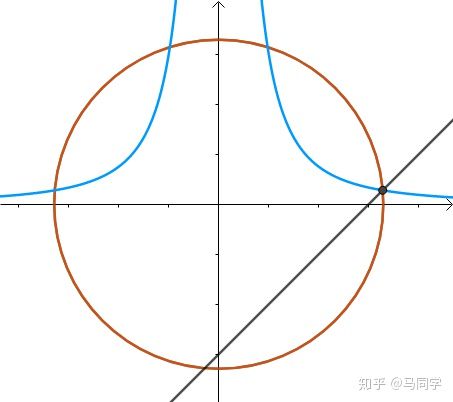
那这三者的法线又有什么关系呢?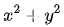 的法线是
的法线是 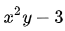 和
和 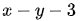 的法线的线性组合:
的法线的线性组合: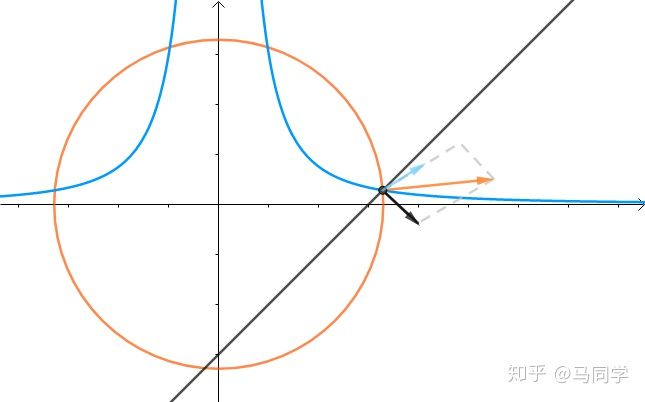
假设: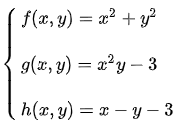
那么线性组合就表示为: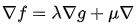
联立方程: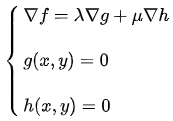
即可求解。
统计学系方法-第6章-逻辑斯谛回归与最大熵模型
逻辑斯谛回归(logistic regression)是统计学习中的经典分类方法。最大熵是概率模型学习的一个准则,将其推广到分类问题得到最大熵模型(maximum entropy model)。逻辑斯蒂回归模型与最大熵模型都属于对数线性模型。
逻辑斯谛回归模型
逻辑斯谛分布
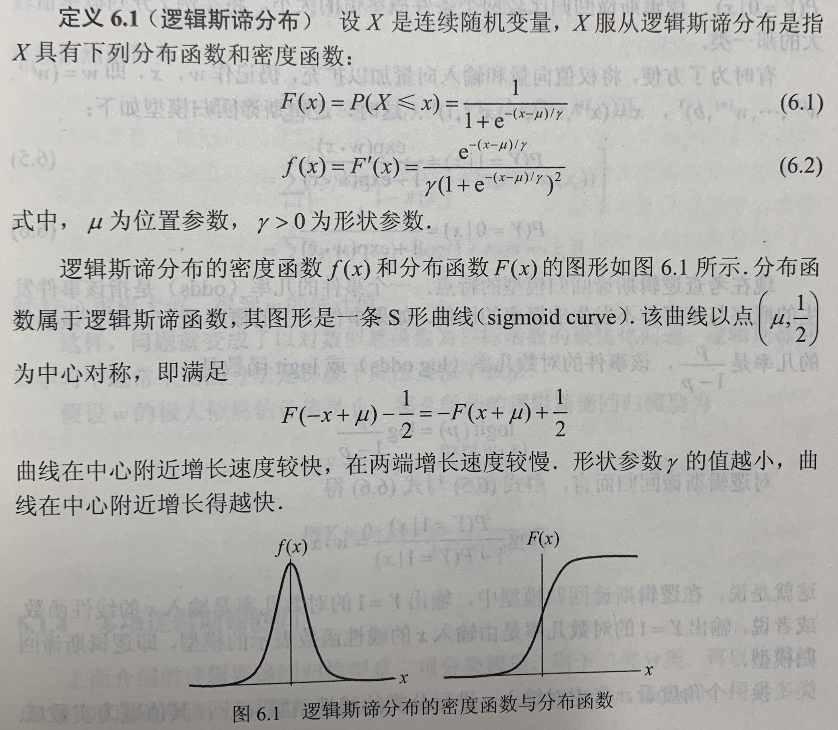
二项逻辑斯谛回归模型
二项逻辑斯谛回归模型(binomial logistic regression model)是一种分类模型,由条件概率分布 P(Y|X) 表示,形式为参数化的逻辑斯谛分布。这里,随机变量 X 取值为实数,随机变量 Y 取值为 1 或 0。

一个事件的几率(odds)是指该事件发生的概率与该事件不发生的概率的比值。如果事件发生的概率是 p,那么该事件的几率是 p/(1-p),该事件的对数几率(log odds)或 logit 函数是 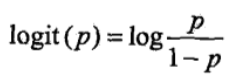
对逻辑斯谛回归而言,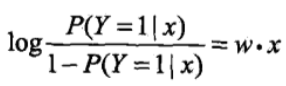
这就是说,在逻辑斯谛回归模型中,输出 Y=1 的对数几率是输入 x 的线性函数。或者说,输出 Y=1 的对数几率是由输入 x 的线性函数表示的模型,即逻辑斯谛回归模型。
模型参数估计

多项逻辑斯谛回归

最大熵模型
最大熵模型(maximum entropy model)由最大熵原理推导实现。
最大熵原理
最大熵原理是概率模型学习的一个准则。最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足条件的模型集合中选取熵最大的模型。


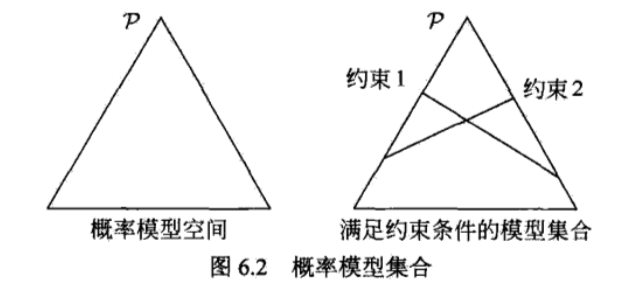
最大熵模型的定义


最大熵模型的学习
最大熵模型的学习过程就是求解最大熵模型的过程。最大熵模型的学习可以形式化为约束最优化问题。

求解上述约束最优问题,所得出的解,就是最大熵模型学习的解。
将约束最优化的原始问题转换为无约束最优化的对偶问题。通过求解对偶问题求解原始问题。

由于拉格朗日函数 L(P, w) 是 P 的凸函数,原始问题(6.18)的解与对偶问题(6.19)的解是等价的。


极大似然估计


模型学习的最优化算法
逻辑斯谛回归模型、最大熵模型学习归结为似然函数为目标函数的最优化问题,通常通过迭代算法求解。从最优化的观点看,这时的目标函数具有很好的性质。它是光滑的凸函数,因此多种最优化的方法都适用,保证能找到全局最优解。常用的方法有改进的迭代尺度法、梯度下降法、牛顿法或拟牛顿法。牛顿法或拟牛顿法一般收敛速度更快。
改进的迭代尺度法
改进的迭代尺度法(improved iterative scaling, IIS)是一种最大熵模型学习的最优化算法。



拟牛顿法

Logistic Regression:根据周志华老师的讲法,这里 logistic 是对数几率的意思,所以正确的翻译方法应该叫 __对数几率回归__,所以不要以为这个东西叫 __逻辑回归__,逻辑回归是错误的翻译。
Java-框架、相关技术-0-知识点汇总
框架
Spring
特点
- 控制反转(IOC)
- 注入方式
- 构造器注入
- setter 注入方式
- 注解注入
- 接口注入
- 循环依赖
- singletonObjects:第一级缓存,里面放置的是实例化好的单例对象;
- earlySingletonObjects:第二级缓存,里面存放的是提前曝光的单例对象;
- singletonFactories:第三级缓存,里面存放的是要被实例化的对象的对象工厂
- 注入步骤
- 创建 bean 的时候 Spring 首先从一级缓存 singletonObjects 中获取。
- 如果获取不到,并且对象正在创建中,就再从二级缓存 earlySingletonObjects 中获取。
- 如果还是获取不到就从三级缓存 singletonFactories 中取。(Bean 调用构造函数进行实例化后,即使属性还未填充,就可以通过三级缓存向外提前暴露依赖的引用值(提前曝光),根据对象引用能定位到堆中的对象,其原理是基于 Java的 引用传递),取到后从三级缓存移动到了二级缓存完全初始化之后将自己放入到一级缓存中供其他使用。
- 因为加入 singletonFactories 三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
- 构造器循环依赖解决办法
- 在构造函数中使用 @Lazy 注解延迟加载。在注入依赖时,先注入代理对象,当首次使用时再创建对象。
- 构造器循环依赖解决办法
- 注入方式
- 面向切面编程(AOP)
- 名词
- 切面(Aspect):切面是通知和切点的结合。通知和切点共同定义了切面的全部内容。 在 Spring AOP 中,切面可以使用通用类(基于模式的风格) 或者在普通类中以 @AspectJ 注解来实现。
- 连接点(Join point):指方法,在 Spring AOP 中,一个连接点总是代表一个方法的执行。应用可能有数以千计的时机应用通知。这些时机被称为连接点。连接点是在应用执行过程中能够插入切面的一个点。这个点可以是调用方法时、抛出异常时、甚至修改一个字段时。切面代码可以利用这些点插入到应用的正常流程之中,并添加新的行为。
- Spring 只支持方法级别的连接点
- 因为 Spring 基于动态代理,所以 Spring 只支持方法连接点。Spring 缺少对字段连接点的支持,而且它不支持构造器连接点。方法之外的连接点拦截功能,我们可以利用 Aspect 来补充。
- Spring 只支持方法级别的连接点
- 通知(Advice):在 AOP 术语中,切面的工作被称为通知。
- 5 种类型的通知
- 前置通知(Before):在目标方法被调用之前调用通知功能;
- 后置通知(After):在目标方法完成之后调用通知,此时不会关心方法的输出是什么;
- 返回通知(After-returning):在目标方法成功执行之后调用通知;
- 异常通知(After-throwing):在目标方法抛出异常后调用通知;
- 环绕通知(Around):通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的行为。
- 5 种类型的通知
- 切入点(Pointcut):切点的定义会匹配通知所要织入的一个或多个连接点。我们通常使用明确的类和方法名称,或是利用正则表达式定义所匹配的类和方法名称来指定这些切点。
- 引入(Introduction):引入允许我们向现有类添加新方法或属性。
- 目标对象(Target Object):被一个或者多个切面(aspect)所通知(advise)的对象。它通常是一个代理对象。也有人把它叫做被通知(adviced)对象。 既然 Spring AOP 是通过运行时代理实现的,这个对象永远是一个被代理(proxied)对象。
- 织入(Weaving):织入是把切面应用到目标对象并创建新的代理对象的过程。在目标对象的生命周期里有多少个点可以进行织入
- 编译期:切面在目标类编译时被织入。AspectJ 的织入编译器是以这种方式织入切面的。
- 类加载期:切面在目标类加载到 JVM 时被织入。需要特殊的类加载器,它可以在目标类被引入应用之前增强该目标类的字节码。AspectJ5 的加载时织入就支持以这种方式织入切面。
- 运行期:切面在应用运行的某个时刻被织入。一般情况下,在织入切面时,AOP 容器会为目标对象动态地创建一个代理对象。SpringAOP 就是以这种方式织入切面。
- 通过动态代理方式实现
- JDK 动态代理
- 实现原理
- 通过实现 InvocationHandlet 接口创建自己的调用处理器;
- 通过为 Proxy 类指定 ClassLoader 对象和一组 interface 来创建动态代理;
- 通过反射机制获取动态代理类的构造函数,其唯一参数类型就是调用处理器接口类型;
- 通过构造函数创建动态代理类实例,构造时调用处理器对象作为参数参入;
- 是面向接口的代理模式,如果被代理目标没有接口那么 Spring 也无能为力,Spring 通过 Java 的反射机制生产被代理接口的新的匿名实现类,重写了其中 AOP 的增强方法。
- 实现原理
- CGLib 动态代理
- Spring 在运行期间通过 CGlib 继承要被动态代理的类,重写父类的方法,实现 AOP 面向切面编程呢。CGLib 动态代理是通过字节码底层继承要代理类来实现(如果被代理类被 final 关键字所修饰,那么会失败)。
- JDK 动态代理
- 配置 AOP 执行顺序
- 通过实现 org.springframework.core.Ordered 接口
- 通过
@Order()注解 - 通过配置文件配置
- 名词
Spring 容器
基础组件
BeanFactory
- Spring 底层容器,定义了最基本的容器功能
- BeanFactory 位于整个容器类体系结构的顶端,其基本实现类为 DefaultListableBeanFactory。之所以称其为核心容器,是因为该类容器实现 IOC 的核心功能:比如配置文件的加载解析,Bean 依赖的注入以及生命周期的管理等。BeanFactory 作为 Spring 框架的基础设施,面向 Spring 框架本身,一般不会被用户直接使用。
ApplicationContext
扩展于 BeanFactory,拥有更丰富的功能。例如:添加事件发布机制、父子级容器,一般都是直接使用 ApplicationContext。
通常译为应用上下文,不过称其为应用容器可能更形象些。它在 BeanFactory 提供的核心 IOC 功能之上作了扩展。通常 ApplicationContext 的实现类内部都持有一个 BeanFactory 的实例,IOC 容器的核心功能会交由它去完成。而 ApplicationContext 本身,则专注于在应用层对 BeanFactory 作扩展,比如提供对国际化的支持,支持框架级的事件监听机制以及增加了很多对应用环境的适配等。ApplicationContext 面向的是使用 Spring 框架的开发者。开发中经常使用的 ClassPathXmlApplicationContext 就是典型的 Spring 的应用容器,也是要进行解读的 IOC 容器。
相关类
AbstractApplicationContext
ApplicationContext 接口的抽象实现类,能够自动检测并注册各种后置处理器(PostProcessor)和事件监听器(Listener),以模板方法模式定义了一些容器的通用方法,比如启动容器的真正方法
refresh()就是在该类中定义的。refresh()方法```
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {// Prepare this context for refreshing. // 准备,记录容器的启动时间 startupDate,标记容器为激活,初始化上下文环境如文件路径信息,验证必填属性是否填写 prepareRefresh(); // Tell the subclass to refresh the internal bean factory. // 这步比较重要(解析),告诉子类去刷新 bean 工厂,这步完成后配置文件就解析成一个个 bean 定义,注册到 BeanFactory(但是未被初始化,仅将信息写到了 beanDefination 的 map 中) ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); // Prepare the bean factory for use in this context. // 设置 beanFactory 类加载器,添加多个 beanPostProcesser prepareBeanFactory(beanFactory); try { // Allows post-processing of the bean factory in context subclasses. // 允许子类上下文中对 beanFactory 做后期处理 postProcessBeanFactory(beanFactory); // Invoke factory processors registered as beans in the context. // 调用 BeanFactoryPostProcessor 各个实现类的方法 invokeBeanFactoryPostProcessors(beanFactory); // Register bean processors that intercept bean creation. // 注册 BeanPostProcessor 的实现类,注意看和 BeanFactoryPostProcessor 的区别 // 此接口两个方法: postProcessBeforeInitialization 和 postProcessAfterInitialization // 两个方法分别在 Bean 初始化之前和初始化之后得到执行。注意,到这里 Bean 还没初始化 registerBeanPostProcessors(beanFactory); // Initialize message source for this context. //初始化 ApplicationContext 的 MessageSource initMessageSource(); // Initialize event multicaster for this context. // 初始化 ApplicationContext 事件广播器 initApplicationEventMulticaster(); // Initialize other special beans in specific context subclasses. // 初始化子类特殊 bean(钩子方法) onRefresh(); // Check for listener beans and register them. // 注册事件监听器 registerListeners(); // Instantiate all remaining (non-lazy-init) singletons. // 初始化所有 singleton bean finishBeanFactoryInitialization(beanFactory); // Last step: publish corresponding event. // 广播事件,ApplicationContext 初始化完成 finishRefresh(); } catch (BeansException ex) { if (logger.isWarnEnabled()) { logger.warn("Exception encountered during context initialization - " + "cancelling refresh attempt: " + ex); } // Destroy already created singletons to avoid dangling resources. destroyBeans(); // Reset 'active' flag. cancelRefresh(ex); // Propagate exception to caller. throw ex; } finally { // Reset common introspection caches in Spring's core, since we // might not ever need metadata for singleton beans anymore... resetCommonCaches(); }}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137- AbstractRefreshableApplicationContext
- 继承 AbstractApplicationContext 的抽象类。内部持有一个 DefaultListableBeanFactory 的实例,使得继承 AbstractRefreshableApplicationContext 的 Spring 的应用容器内部默认有一个 Spring 的核心容器,那么 Spring 容器的一些核心功能就可以委托给内部的核心容器去完成。
- AbstractRefreshableApplicationContext 在内部定义了创建、销毁以及刷新核心容器 BeanFactory 的方法。
- ClassPathXmlApplicationContext
- 最常用的 Spring 的应用容器之一。在启动时会加载类路径下的 xml 文件作为容器的配置信息。
- BeanFactoryPostProcessor
- 实现该接口,可以在 Spring 的 bean 创建之前,修改 bean 的定义属性。也就是说,Spring 允许 BeanFactoryPostProcessor 在容器实例化任何其它 bean 之前读取配置元数据,并可以根据需要进行修改,例如可以把 bean 的 scope 从 singleton 改为 prototype,也可以把 property 的值给修改掉。可以同时配置多个 BeanFactoryPostProcessor,并通过设置'order'属性来控制各个 BeanFactoryPostProcessor 的执行次序。
- BeanFactoryPostProcessor 是在 spring 容器加载了 bean 的定义文件之后,在 bean 实例化之前执行的。接口方法的入参是 ConfigurrableListableBeanFactory,使用该参数,可以获取到相关 bean 的定义信息。
- Spring 中,有内置的一些 BeanFactoryPostProcessor 实现类,常用的有:
- org.springframework.beans.factory.config.PropertyPlaceholderConfigurer
- org.springframework.beans.factory.config.PropertyOverrideConfigurer
- org.springframework.beans.factory.config.CustomEditorConfigurer:用来注册自定义的属性编辑器
- BeanPostProcessor
- BeanPostProcessor,可以在 Spring 容器实例化 bean 之后,在执行 bean 的初始化方法前后,添加一些自己的处理逻辑。
- 这里说的初始化方法,指的是下面两种:
- bean 实现了 InitializingBean 接口,对应的方法为 afterPropertiesSet
- 在 bean 定义的时候,通过 init-method 设置的方法
- BeanPostProcessor 是在 Spring 容器加载了 bean 的定义文件并且实例化 bean 之后执行的。BeanPostProcessor 的执行顺序是在 BeanFactoryPostProcessor 之后。
- Spring中,有内置的一些 BeanPostProcessor 实现类,例如:
- org.springframework.context.annotation.CommonAnnotationBeanPostProcessor:支持 @Resource 注解的注入
- org.springframework.beans.factory.annotation.RequiredAnnotationBeanPostProcessor:支持 @Required 注解的注入
- org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor:支持 @Autowired 注解的注入
- org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor:支持 @PersistenceUnit 和 @PersistenceContext 注解的注入
- org.springframework.context.support.ApplicationContextAwareProcessor:用来为 bean 注入 ApplicationContext 等容器对象
- Resource
- bean 配置文件,一般为 xml 文件。可以理解为保存 bean 信息的文件。
- BeanDefinition
- BeanDefinition 定义了 bean 的基本信息,根据它来创造 bean。
- 容器启动步骤
- 
1. 资源定位:找到配置文件
2. BeanDefinition 载入和解析
3. BeanDefinition 注册
4. bean 的实例化和依赖注入
- BeanFactory
- BeanFactory 定义的标准处理顺序
1. BeanNameAware's setBeanName
2. BeanClassLoaderAware's setBeanClassLoader
3. BeanFactoryAware's setBeanFactory
4. ResourceLoaderAware's setResourceLoader (only applicable when running in an application context)
5. ApplicationEventPublisherAware's setApplicationEventPublisher (only applicable when running in an application context)
6. MessageSourceAware's setMessageSource (only applicable when running in an application context)
7. ApplicationContextAware's setApplicationContext (only applicable when running in an application context)
8. ServletContextAware's setServletContext (only applicable when running in a web application context)
9. postProcessBeforeInitialization methods of BeanPostProcessors
10. InitializingBean's afterPropertiesSet
11. a custom init-method definition
12. postProcessAfterInitialization methods of BeanPostProcessors
- 第 9 点和 12 点是通过 BeanPostProccessor 接口进行处理的
- 第 10 点是通过 InitializingBean 接口去实现的
- BeanFactory 关闭的处理顺序
1. DisposableBean's destroy
2. a custom destroy-method definition
#### Spring 事件监听机制
- 说明
- 事件监听机制可以理解为是一种观察者模式,有数据发布者(事件源)和数据接受者(监听器);
- 在 Java 中,事件对象都是继承 java.util.EventObject 对象,事件监听器都是 java.util.EventListener 实例;
- EventObject 对象不提供默认构造器,需要外部传递 source 参数,即用于记录并跟踪事件的来源;
- Spring 事件
- Spring 事件对象为 ApplicationEvent,继承 EventObject
- Spring 事件监听器为 ApplicationListener,继承 EventListener
- 实现 Spring 事件监听有两种方式:
- 面向接口编程,实现 ApplicationListener 接口;
- 基于注解驱动,@EventListener(Spring 自定义的注解);
- Spring 自带的监听器
- ContextLoaderListener
- 在启动 Web 容器时,自动装配 Spring applicationContext.xml 的配置信息。
- 因为它实现了 ServletContextListener 这个接口,在 web.xml 配置这个监听器,启动容器时,就会默认执行它实现的方法。在 ContextLoaderListener 中关联了 ContextLoader 这个类,所以整个加载配置过程由 ContextLoader 来完成。
- RequestContextListener
- Spring2.0 中新增了三个 web 作用域:request、session、global session,如果希望 web 容器中的某个 bean 具有新的作用域,除了在 bean 中配置相应的 scope 属性外,还需要在容器中进行额外的初始化配置。
#### SpringMVC
- MVC 模式代表 Model-View-Controller(模型-视图-控制器)模式。
- 原理
- 
- 执行流程
- 用户向服务器发送请求,请求会到 DispatcherServlet,DispatcherServlet 对请求 URL 进行解析,得到请求资源标识符(URI),然后根据该 URI,调用 HandlerMapping 获得该 Handler 配置的所有相关的对象(包括一个 Handler 处理器对象、多个 HandlerInterceptor 拦截器对象),最后以 HandlerExecutionChain 对象的形式返回。
- DispatcherServlet 根据获得的 Handler,选择一个合适的 HandlerAdapter。提取 Request 中的模型数据,填充 Handler 入参,开始执行 Handler(Controller)。 在填充 Handler 的入参过程中,根据你的配置,Spring 将帮你做一些额外的工作:
- HttpMessageConveter: 将请求消息(如 Json、xml 等数据)转换成一个对象,将对象转换为指定的响应信息
- 数据转换:对请求消息进行数据转换。如 String 转换成 Integer、Double 等
- 数据格式化:对请求消息进行数据格式化。 如将字符串转换成格式化数字或格式化日期等
- 数据验证: 验证数据的有效性(长度、格式等),验证结果存储到 BindingResult 或 Error 中
- Handler 执行完成后,向 DispatcherServlet 返回一个 ModelAndView 对象;根据返回的 ModelAndView,选择一个适合的 ViewResolver 返回给 DispatcherServlet;ViewResolver 结合 Model 和 View,来渲染视图,最后将渲染结果返回给客户端。
#### 注解
- 注入相关
- @Qualifier
- 用处:当一个接口有多个实现的时候,为了指名具体调用哪个类的实现。
- @Resource
- 可以通过 byName 和 byType 的方式注入,默认先按 byName 的方式进行匹配,如果匹配不到,再按 byType 的方式进行匹配。
- 由 JSR-250 提供
- @Autowired
- 按 byType 方式注入,如果按 byType 冲突或找不到的话可以用 @Qualifier 来找 byName
- 由 spring 提供
- @Inject
- 由 JSR-330 提供
- 注意
- 使用前需要导入 jar 包——javax.inject;
- 支持 @Primary 注解,而且因为没有精确匹配,@Primary 的优先级最高;
- 不支持 required=false,即不能注入 null,如果找不到组件肯定报错;
- 默认按照属性名跟 bean 的名称匹配查找,如果不存在,再按类型匹配查找。
#### 事务
- 事务传播机制
- PROPAGATION_REQUIRED:如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常⻅的选择。
- PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行。
- PROPAGATION_MANDATORY:使用当前的事务,如果当前没有事务,就抛出异常。
- PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行。与 PROPAGATION_REQUIRED 类似的操作。
- 事务原理
- Spring 在扫描 bean 的时候会扫描方法上是否包含 @Transactional 注解,如果包含,Spring 会为这个 bean 动态地生成一个子类(即代理类,proxy),代理类是继承原来那个 bean 的。此时,当这个有注解的方法被调用的时候,实际上是由代理类来调用的,代理类在调用之前就会启动 transaction。
- ```
@Service
class A{
@Transactinal
method b(){...}
method a(){ //标记1
b();
}
}
//Spring扫描注解后,创建了另外一个代理类,并为有注解的方法插入一个startTransaction()方法:
class proxy$A{
A objectA = new A();
method b(){ //标记2
startTransaction();
objectA.b();
}
method a(){ //标记3
objectA.a(); //由于a()没有注解,所以不会启动transaction,而是直接调用A的实例的a()方法
}
}
@Transactional 注解事务不生效的情况
- 数据库
- 事务生效的前提是你的数据源得支持事务,比如 mysql 的 MyISAM 引擎就不支持事务,而 Innodb 支持事务
- 类内部访问
- 在一个 Service 内部,事务方法之间的嵌套调用,普通方法和事务方法之间的嵌套调用,都不会开启新的事务。
- 非事务方法 A 调用事务方法 B,方法 B 事务不生效
- 因为 spring 采用动态代理机制来实现事务控制,而动态代理最终都是要调用原始对象的,而原始对象在去调用方法时,是不会再触发代理了
- 在事务方法 A 中调用另外一个事务方法 B,被调用方法 B 的事务没起作用
- spring 是通过代理代管理事务的,当在第一个方法 insertUser1 内直接调用 insertUser2 的时候 ,insertUser2 上的事务是不会起作用的(也就是 insertUser2 是没有开启事务)
- 非事务方法 A 调用事务方法 B,方法 B 事务不生效
- 在一个 Service 内部,事务方法之间的嵌套调用,普通方法和事务方法之间的嵌套调用,都不会开启新的事务。
- 私有方法
- 在私有方法上,添加 @Transactional 注解也不会生效,私有方法外部不能访问,所以只能内部访问,上面的 case 不生效,这个当然也不生效了
- 异常不匹配
- @Transactional 注解默认处理运行时异常,即只有抛出运行时异常时,才会触发事务回滚,否则并不会如
- 多线程
- 在标记事务的方法内部,另起子线程执行 db 操作,此时事务同样不会生效
- 传播属性
- 几种传播方式是不走事务执行的
- 数据库
Bean
- Bean 的作用域
- singleton : bean 在每个 Spring ioc 容器中只有一个实例。
- prototype:一个 bean 的定义可以有多个实例。
- request:每次 http 请求都会创建一个 bean,该作用域仅在基于 web 的 Spring ApplicationContext 情形下有效。
- session:在一个 HTTP Session 中,一个 bean 定义对应一个实例。该作用域仅在基于 web 的 Spring ApplicationContext 情形下有效。
- global-session:在一个全局的 HTTP Session 中,一个 bean 定义对应一个实例。该作用域仅在基于 web 的 Spring ApplicationContext 情形下有效。
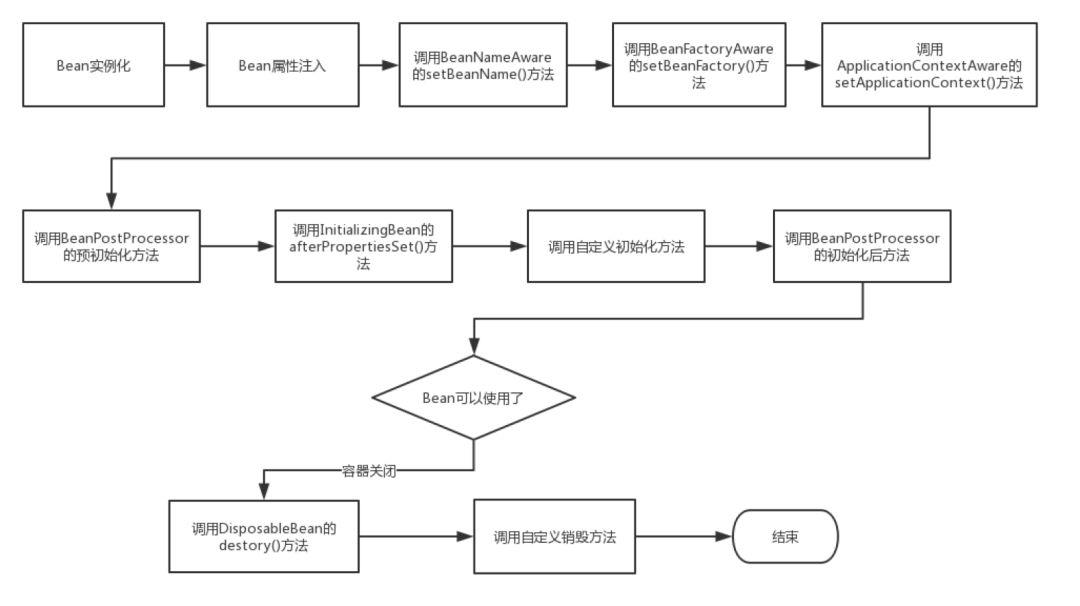
- Bean 的生命周期
- Spring 启动,查找并加载需要被 Spring 管理的 Bean,进行 Bean 的实例化
- Bean 实例化后对将 Bean 的引入和值注入到 Bean 的属性中
- 如果 Bean 实现了 BeanNameAware 接口的话,Spring 将 Bean 的 Id 传递给 setBeanName() 方法
- 如果 Bean 实现了 BeanFactoryAware 接口的话,Spring 将调用 setBeanFactory() 方法,将 BeanFactory 容器实例传入
- 如果 Bean 实现了 ApplicationContextAware 接口的话,Spring 将调用 Bean 的 setApplicationContext() 方法,将 Bean 所在应用上下文引用传入进来。
- 如果 Bean 实现了 BeanPostProcessor 接口,Spring 就将调用他们的 postProcessBeforeInitialization() 方法。
- 如果 Bean 实现了 InitializingBean 接口,Spring 将调用他们的 afterPropertiesSet() 方法。类似的,如果 Bean 使用 init-method 声明了初始化方法,该方法也会被调用
- 如果 Bean 实现了 BeanPostProcessor 接口,Spring 就将调用他们的 postProcessAfterInitialization() 方法。
- 此时,Bean 已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
- 如果 Bean 实现了 DisposableBean 接口,Spring 将调用它的 destory() 接口方法,同样,如果 Bean 使用了 destory-method 声明销毁方法,该方法也会被调用。
- 获取 bean 流程
- 相关问题
- Spring 框架中的单例 bean 是线程安全的吗?
- 不是,Spring 框架中的单例 bean 不是线程安全的。
- spring 中的 bean 默认是单例模式,spring 框架并没有对单例 bean 进行多线程的封装处理。
- 实际上大部分时候 spring bean 无状态的(比如 dao 类),所有某种程度上来说 bean 也是安全的,但如果 bean 有状态的话(比如 view model 对象),那就要开发者自己去保证线程安全了,最简单的就是改变 bean 的作用域,把“singleton”变更为“prototype”,这样请求 bean 相当于
new Bean()了,所以就可以保证线程安全了。
- Spring 框架中的单例 bean 是线程安全的吗?

用法
- application.yml 中的 MySQL 密码可以通过第三方包加密(jasypt)
相关问题
- Spring 框架中都用到了哪些设计模式?
- 工厂模式:BeanFactory 就是简单工厂模式的体现,用来创建对象的实例;
- 单例模式:Bean 默认为单例模式。
- 代理模式:Spring 的 AOP 功能用到了 JDK 的动态代理和 CGLIB 字节码生成技术;
- 模板方法:用来解决代码重复的问题。比如:RestTemplate, JmsTemplate, JpaTemplate。
- 观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如 Spring 中 listener 的实现 ApplicationListener。
- Spring BeanFactory 与 FactoryBean 的区别
- BeanFactory
- BeanFactory,以 Factory 结尾,表示它是一个工厂类(接口),用于管理 Bean 的一个工厂。在 Spring 中,BeanFactory 是 IOC 容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。
- Spring 为我们提供了许多易用的 BeanFactory 实现,XmlBeanFactory 就是常用的一个,该实现将以 XML 方式描述组成应用的对象及对象间的依赖关系。XmlBeanFactory 类将持有此 XML 配置元数据,并用它来构建一个完全可配置的系统或应用。
- FactoryBean
- 以 Bean 结尾,表示它是一个 Bean,不同于普通 Bean 的是:它是实现了
FactoryBean<T>接口的 Bean,根据该 Bean 的 ID 从 BeanFactory 中获取的实际上是 FactoryBean 的getObject()返回的对象,而不是 FactoryBean 本身,如果要获取F actoryBean 对象,请在 id 前面加一个 & 符号来获取。 - 例如自己实现一个 FactoryBean,功能:用来代理一个对象,对该对象的所有方法做一个拦截,在调用前后都输出一行 LOG,模仿 ProxyFactoryBean 的功能。
- 以 Bean 结尾,表示它是一个 Bean,不同于普通 Bean 的是:它是实现了
- BeanFactory 是个 Factory,也就是 IOC 容器或对象工厂,FactoryBean 是个 Bean。在 Spring 中,所有的 Bean 都是由 BeanFactory(也就是 IOC 容器)来进行管理的。但对 FactoryBean 而言,这个 Bean 不是简单的 Bean,而是一个能生产或者修饰对象生成的工厂 Bean,它的实现与设计模式中的工厂模式和修饰器模式类似。
- BeanFactory
- 如何指定 bean 的初始化顺序?
- 构造方法依赖
- 是最简单也是最常见的使用姿势,但是在使用时,需要注意循环依赖等问题。
- bean 的注入方式之中,有一个就是通过构造方法来注入,借助这种方式,我们可以解决有优先级要求的 bean 之间的初始化顺序。
- 虽然这种方式比较直观简单,但是有几个限制
- 需要有注入关系,如 CDemo2 通过构造方法注入到 CDemo1 中,如果需要指定两个没有注入关系的 bean 之间优先级,则不太合适(比如我希望某个 bean 在所有其他的 Bean 初始化之前执行)
- 循环依赖问题,如过上面的 CDemo2 的构造方法有一个 CDemo1 参数,那么循环依赖产生,应用无法启动
- 另外一个需要注意的点是,在构造方法中,不应有复杂耗时的逻辑,会拖慢应用的启动时间
- @DependOn 注解
- 这是一个专用于解决 bean 的依赖问题,当一个 bean 需要在另一个 bean 初始化之后再初始化时,可以使用这个注解
- 在使用这个注解的时候,有一点需要特别注意,它能控制 bean 的实例化顺序,但是 bean 的初始化操作(如构造 bean 实例之后,调用 @PostConstruct 注解的初始化方法)顺序则不能保证
- 完整的 bean 创建,分成了两块顺序
- 实例化(调用构造方法)
- 初始化(注入依赖属性,调用 @PostConstruct 方法)
- 完整的 bean 创建,分成了两块顺序
- BeanPostProcessor 扩展
- 非典型的使用方式,如非必要,请不要用这种方式来控制 bean 的加载顺序
- 构造方法依赖
- Spring 如何统计 bean 的数量?
- 通过实现 BeanFactoryPostProcessor 接口,调用 ConfigurableListableBeanFactory 的
getBeanDefinitionCount()方法。
- 通过实现 BeanFactoryPostProcessor 接口,调用 ConfigurableListableBeanFactory 的
SpringBoot
- maven
- spring-boot-starter-parent
- 通过这个作为 parent,可以继承其中定义的配置、各项依赖以及版本号
- 在本项目中添加依赖时,可以省略版本号
- spring-boot-starter-parent
MyBatis
- 介绍
- MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
- 语法
#{}和${}#{}:使用的是预编译,对应 JBDC 中的 PreparedStatement${}:不会修改或者转义字符换,直接输出变量值- 会引发 SQL 注入问题
- SqlSession
- SqlSession 是 Mybatis 最重要的构建之一,可以简单的认为 Mybatis 一系列的配置目的是生成类似 JDBC 生成的 Connection 对象的 SqlSession 对象,这样才能与数据库开启“沟通”,通过 SqlSession 可以实现增删改查(当然现在更加推荐是使用 Mapper 接口形式)。
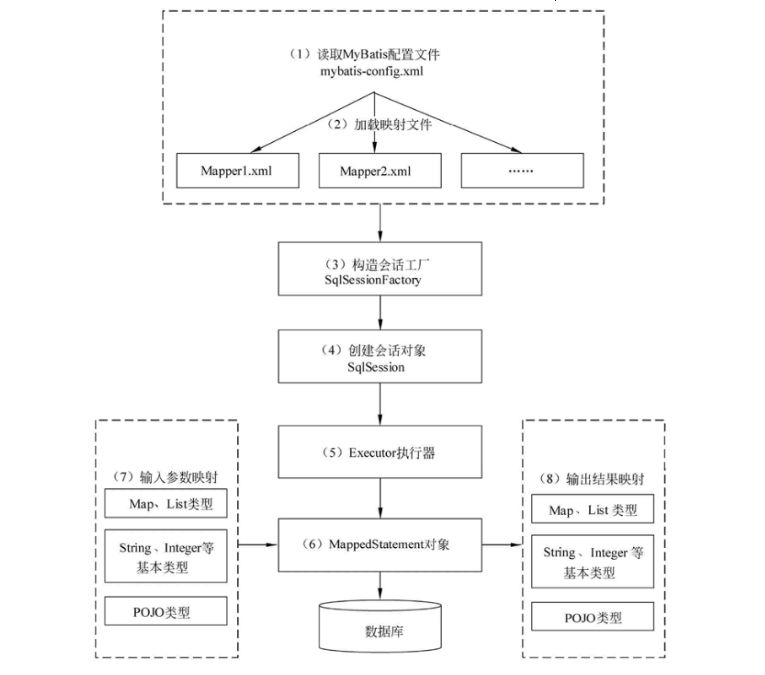
- 工作原理
- 读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
- 加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
- 构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
- 创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
- Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
- MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
- 输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
- 输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
- 一级缓存与二级缓存
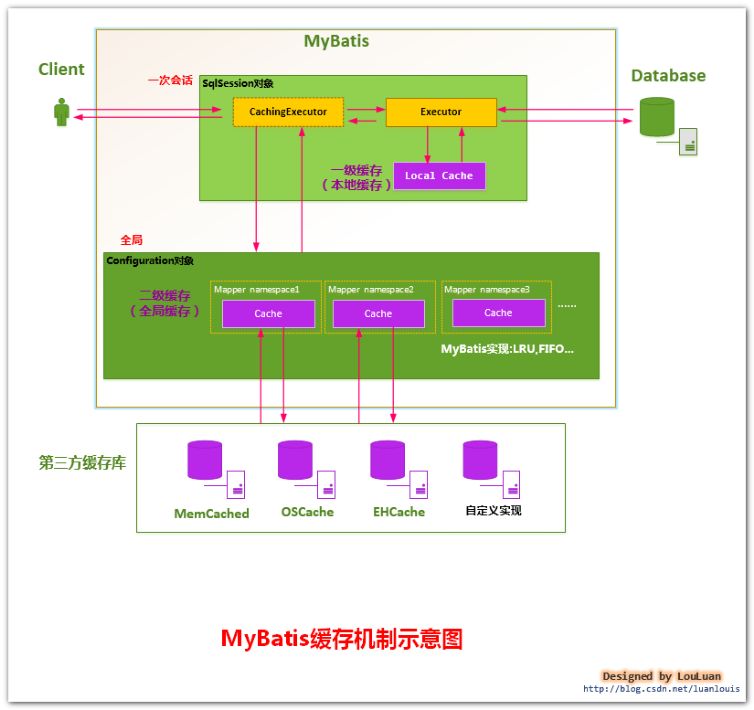
- 一级缓存
- 该级缓存默认开启,不能关闭;
- 该级缓存为 SqlSession 级别的缓存,也称为本地缓存;
- 以下 4 种情况将会导致该级缓存失效:
- 在不同 SqlSession 中查询数据;
- 相同 SqlSession 中查询数据,但查询条件不同
- 相同 SqlSession 中查询数据,但两次查询之间执行了增删改操作
- 同 SqlSession 中查询数据,但第二次查询前,程序调用 SqlSession 对象
clearCache()方法手动清除了一级缓存
- 原理
- 第一次发出一个查询 sql,sql 查询结果写入 sqlsession 的一级缓存中,缓存使用的数据结构是一个 map。
- key:MapperID+offset+limit+Sql+所有的入参
- value:用户信息
- 第一次发出一个查询 sql,sql 查询结果写入 sqlsession 的一级缓存中,缓存使用的数据结构是一个 map。
- 二级缓存
- 该级缓存默认不开启,但如果使用二级缓存需要在每个 XML 映射文件中添加
<cache></cache>以配置该级缓存(相应实体类要序列化)。二级缓存可以通过在全局配置文件配置 setting 标签来关闭该级缓存。- 如果这样配置的话,很多其他的配置就会被默认进行,如:
- 映射文件所有的 select 语句会被缓存
- 映射文件的所有的 insert、update 和 delete 语句会刷新缓存
- 缓存会使用默认的 Least Recently Used(LRU,最近最少使用原则)的算法来回收缓存空间
- 根据时间表,比如 No Flush Interval,(CNFI,没有刷新间隔),缓存不会以任何时间顺序来刷新
- 缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用
- 缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以很安全的被调用者修改,不干扰其他调用者或县城所作的潜在修改
- 如果这样配置的话,很多其他的配置就会被默认进行,如:
- 该级缓存为 namespace 级别的缓存
- 工作机制:通过 SqlSession 查询数据,这些数据将会放到当前会话的一级缓存中;如果当前会话关闭,则一级缓存中的数据会被保存到二级缓存中,此后新的 SqlSession 将从二级缓存中查找数据;
- select 标签的 useCache 属性用于设置是否使用二级缓存;insert、update、delete 或 select 标签均有 flushCache 属性,其中增删改默认true,即 sql 执行以后,会同时清空一级和二级缓存,查询默认 false。
- 为了提高扩展性,MyBatis 定义了 Cache 缓存接口,可以通过实现该缓存接口自定义二级缓存
- 该级缓存默认不开启,但如果使用二级缓存需要在每个 XML 映射文件中添加
- Mybatis 的分页原理
- Mybatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页,可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
- 分页插件的原理就是使用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内,拦截待执行的 SQL,然后根据设置的 dialect(方言),和设置的分页参数,重写 SQL,生成带有分页语句的 SQL,执行重写后的 SQL,从而实现分页。
- 相关问题
- Mybatis 为什么出现?为什么不是直接使用 jdbc?
- JDBC 操作数据库的步骤
- 注册驱动;
- 获取数据库连接;
- 拼接sql语句,设置sql参数;
- 执行sql语句;
- sql返回结果;
- 执行语句和数据库连接;
- 直接用 JDBC 每次都要做大量的相同的操作,并且还要对执行 sql 语句过程中所出现的各种异常和资源释放进行处理,而真正涉及到业务功能的代码其实很少,这明显影响了效率。
- 再有就是当你接收数据库返回的结果集的时候,需要赋值给程序中的实体,使用 JDBC 需要你手动写代码去遍历每一条记录赋值给对应的实体 list 集合中,使用 JDBC 意味着需要更多的代码来提取结果并将它们映射到对象实例中,
- MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
- JDBC 操作数据库的步骤
- 通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
- Dao 接口,就是人们常说的 Mapper 接口,接口的全限名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中 MappedStatement 的 id 值,接口方法内的参数,就是传递给 sql 的参数。Mapper 接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个 MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到 namespace 为 com.mybatis3.mappers.StudentDao 下面 id = findStudentById 的 MappedStatement。在 Mybatis 中,每一个
<select>、<insert>、<update>、<delete>标签,都会被解析为一个 MappedStatement 对象。 - Dao 接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
- Dao 接口的工作原理是 JDK 动态代理,Mybatis 运行时会使用 JDK 动态代理为 Dao 接口生成代理 proxy 对象,代理对象 proxy 会拦截接口方法,转而执行 MappedStatement 所代表的 sql,然后将 sql 执行结果返回。
- Dao 接口,就是人们常说的 Mapper 接口,接口的全限名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中 MappedStatement 的 id 值,接口方法内的参数,就是传递给 sql 的参数。Mapper 接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个 MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到 namespace 为 com.mybatis3.mappers.StudentDao 下面 id = findStudentById 的 MappedStatement。在 Mybatis 中,每一个
- 简述 MyBatis 的插件运行原理,以及如何编写一个插件?
- Mybatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口的插件,Mybatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的
invoke()方法,当然,只会拦截那些你指定需要拦截的方法。实现 Mybatis 的 Interceptor 接口并复写intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,还需要在配置文件中配置你编写的插件。- StatementHandler
- StatementHandler 是数据库会话器,专门用来处理数据库会话的。StatementHandler 内运用了适配器模式和策略模式的思想
- ResultSetHandler
- ResultHandler 是一个结果处理器,StatementHandler 完成了查询之后,最终就是通过 ResultHandler 来实现结果集映射,ResultSetHandler 接口中只定义了3个方法用来处理结果。
- ResultHandler 也默认提供了一个实现类:DefaultResultSetHandler。一般我们平常用的最多的就是通过 handleResultSets 来实现结果集转换。
- ParameterHandler
- ParameterHandler 是一个参数处理器,主要是用来对预编译语句进行参数设置的,只有一个默认实现类 DefaultParameterHandler。
- ParameterHandler 中只定义了两个方法,一个获取参数,一个设置参数。
- Executor
- Executor 就是真正用来执行 Sql 语句的对象,我们调用 SqlSession 中的方法,最终实际上都是通过 Executor 来完成的。
- StatementHandler
- Mybatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口的插件,Mybatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的
- Mybatis 为什么出现?为什么不是直接使用 jdbc?
ShardingSphere-JDBC
- Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Netty
- 介绍
- Netty 是一个 基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。
- 它极大地简化并优化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。
- 支持多种协议,如 FTP、SMTP、HTTP 以及各种二进制和基于文本的传统协议。
- 很多开源项目比如我们常用的 Dubbo、RocketMQ、ElasticSearch、gRPC 等等都用到了 Netty。
- 本质:JBoss 做的一个 Jar 包
- 目的:快速开发高性能、高可靠性的网络服务器和客户端程序
- 优点
- 统一的 API,支持多种传输类型,阻塞和非阻塞的。
- 简单而强大的线程模型。
- 自带编解码器解决 TCP 粘包/拆包问题。
- 自带各种协议栈。
- 真正的无连接数据包套接字支持。
- 比直接使用 Java 核心 API 有更高的吞吐量、更低的延迟、更低的资源消耗和更少的内存复制。
- 安全性不错,有完整的 SSL/TLS 以及 StartTLS 支持。
- 社区活跃
- 成熟稳定,经历了大型项目的使用和考验,而且很多开源项目都使用到了 Netty, 比如我们经常接触的 Dubbo、RocketMQ 等等。
- 应用场景
- 作为 RPC 框架的网络通信工具
- 我们在分布式系统中,不同服务节点之间经常需要相互调用,这个时候就需要 RPC 框架了。不同服务节点之间的通信是如何做的呢?可以使用 Netty 来做。比如我调用另外一个节点的方法的话,至少是要让对方知道我调用的是哪个类中的哪个方法以及相关参数吧!
- 实现一个自己的 HTTP 服务器
- 通过 Netty 我们可以自己实现一个简单的 HTTP 服务器,这个大家应该不陌生。说到 HTTP 服务器的话,作为 Java 后端开发,我们一般使用 Tomcat 比较多。一个最基本的 HTTP 服务器可要以处理常见的 HTTP Method 的请求,比如 POST 请求、GET 请求等等。
- 实现一个即时通讯系统
- 使用 Netty 我们可以实现一个可以聊天类似微信的即时通讯系统。
- 实现消息推送系统
- 市面上有很多消息推送系统都是基于 Netty 来做的。
- 作为 RPC 框架的网络通信工具
- 架构
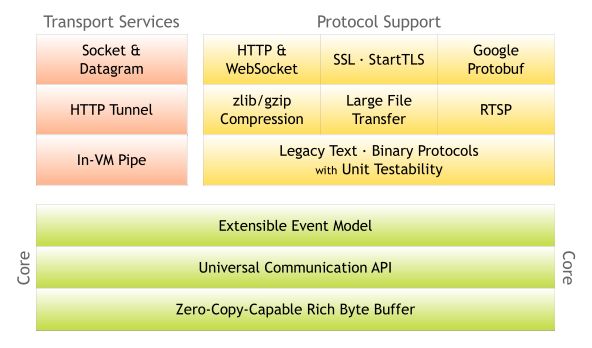
- 绿色的部分 Core 核心模块,包括零拷贝、API 库、可扩展的事件模型。
- 橙色部分 Protocol Support 协议支持,包括 Http 协议、webSocket、SSL(安全套接字协议)、谷歌 Protobuf 协议、zlib/gzip 压缩与解压缩、Large File Transfer 大文件传输等等。
- 红色的部分 Transport Services 传输服务,包括 Socket、Datagram、Http Tunnel 等等。
- 构成部分
- Channel
- NIO 基本结构,代表一个用于连接到实体如硬件设备、文件、网络套接字或程序组件,能否执行一个或多个不同的 I/O 操作的开放连接。
- 比较常用的 Channel 接口实现类是 NioServerSocketChannel(服务端)和 NioSocketChannel(客户端),这两个 Channel 可以和 BIO 编程模型中的 ServerSocket 以及 Socket 两个概念对应上。Netty 的 Channel 接口所提供的 API,大大地降低了直接使用 Socket 类的复杂性。
- Future
- 提供了另一种通知应用操作已经完成的方式,这个对象作为一个一步操作结果的占位符,他将在将来的某个时候完成并提交结果。
- Netty 提供自己的实现,ChannelFuture,用于执行异步操作时使用。每个 Netty 的 outbound I/O 操作都会返回一个 ChannelFuture,这样就不会阻塞,这便是 Netty 所谓的“自底向上的异步和事件驱动”。相关实现的步骤如下:
- 异步连接到远程对等节点,调用立即返回并提供 ChannelFuture;
- 操作完成后通知注册一个 ChannelFutureListener;
- 当
operationComplete()调用时检查操作的状态; - 如果成功就创建一个 ByteBuf 来保存数据;
- 异步发送数据到远程,再次返回 ChannelFuture;
- 如果有一个错误则抛出 Throwable,描述错误原因。
- 相关类
- ChannelFuture
- Netty 是异步非阻塞的,所有的 I/O 操作都为异步的。
- 因此,我们不能立刻得到操作是否执行成功,但是,你可以通过 ChannelFuture 接口的
addListener()方法注册一个 ChannelFutureListener,当操作执行成功或者失败时,监听就会自动触发返回结果。
- ChannelFuture
- Event 和 Handle
- Netty 使用不同的事件来通知我们更改的状态或操作的状态,这使我们能够根据发声的事件触发适当的行为。
- 这些行为可能包括:日志、数据转换、流控制、应用程序逻辑,由于 Netty 是一个网络框架,事件很清晰的跟入栈或出出站数据流相关,因为一些事件可能触发的传入的数据或状态的变化包括:活动或非活动连接、数据的读取、用户事件、错误,出站事件是由于在未来操作将触发的一个动作,这些包括:打开或关闭一个连接到远程、写或冲刷数据到 socket。
- 每个事件都可以分配给用户实现处理程序类的方法,这些范例可直接转换为应用程序构建块。
- Netty 的 ChannelHandler 是各种处理程序的基本抽象,每个处理器实例就是一个回调,用于执行各种事件的响应。
- 相关类
- ChannelHandler
- ChannelHandler 是消息的具体处理器。他负责处理读写操作、客户端连接等事情。
- ChannelPipeline
- ChannelPipeline 为 ChannelHandler 的链,提供了一个容器并定义了用于沿着链传播入站和出站事件流的 API 。当 Channel 被创建时,它会被自动地分配到它专属的 ChannelPipeline。
- 我们可以在 ChannelPipeline 上通过
addLast()方法添加一个或者多个 ChannelHandler ,因为一个数据或者事件可能会被多个 Handler 处理。当一个 ChannelHandler 处理完之后就将数据交给下一个 ChannelHandler 。
- EventLoop
- EventLoop 定义了 Netty 的核心抽象,用于处理连接的生命周期中所发生的事件。
- EventLoop 的主要作用实际就是负责监听网络事件并调用事件处理器进行相关 I/O 操作的处理。
- Channel 为 Netty 网络操作(读写等操作)抽象类,EventLoop 负责处理注册到其上的 Channel 处理 I/O 操作,两者配合参与 I/O 操作。
- EventLoopGroup
- EventLoopGroup 包含多个 EventLoop(每一个 EventLoop 通常内部包含一个线程),上面我们已经说了 EventLoop 的主要作用实际就是负责监听网络事件并调用事件处理器进行相关 I/O 操作的处理。
- 并且 EventLoop 处理的 I/O 事件都将在它专有的 Thread 上被处理,即 Thread 和 EventLoop 属于 1 : 1 的关系,从而保证线程安全。
- ChannelHandler
- 其他
- Bootstrap 和 ServerBootstrap
- Bootstrap 是客户端的启动引导类/辅助类
- ServerBootstrap 客户端的启动引导类/辅助类
- Bootstrap 和 ServerBootstrap
- Channel
- Netty 的线程模型
- 对于网络请求一般可以分为两个处理阶段,一是接收请求任务,二是处理网络请求。根据不同阶段处理方式分为以下几种线程模型:
- 串行化处理模型
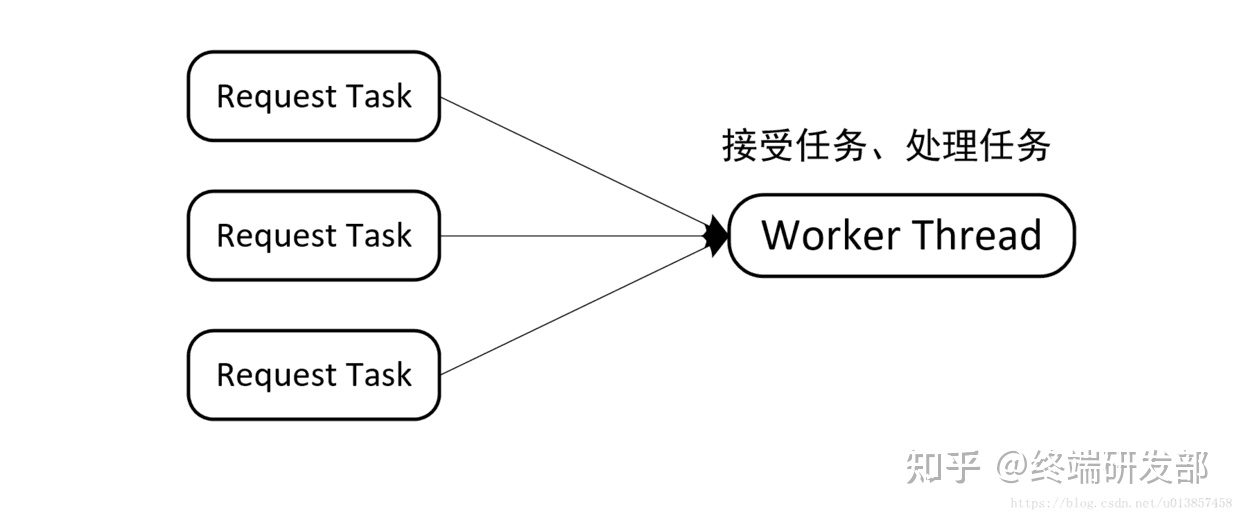
- 这个模型中用一个线程来处理网络请求连接和任务处理,当 worker 接受到一个任务之后,就立刻进行处理,也就是说任务接受和任务处理是在同一个 worker 线程中进行的,没有进行区分。这样做存在一个很大的问题是,必须要等待某个 task 处理完成之后,才能接受处理下一个 task。
- 因此可以把接收任务和处理任务两个阶段分开处理,一个线程接收任务,放入任务队列,另外的线程异步处理任务队列中的任务。
- 并行化处理模型
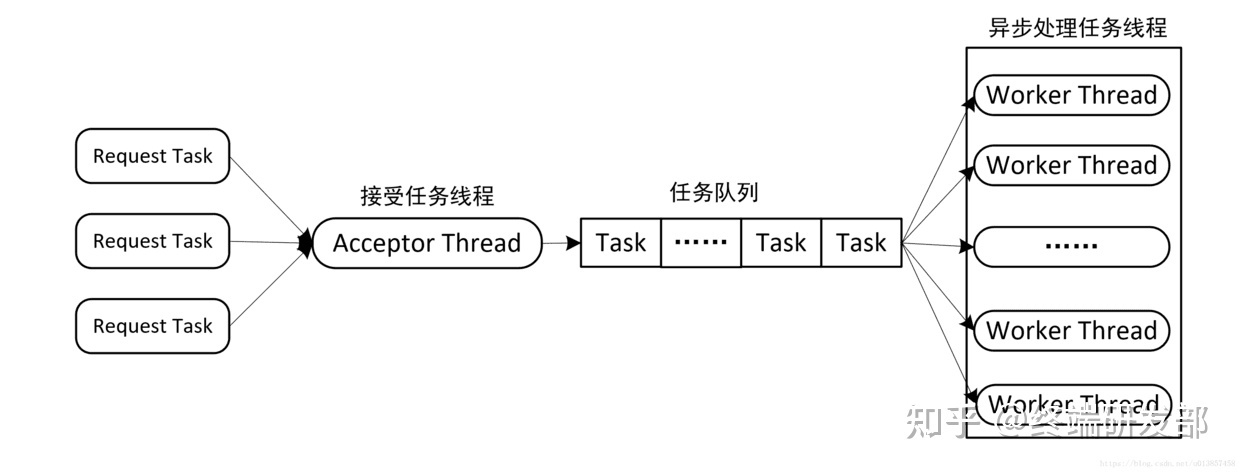
- 由于任务处理一般比较缓慢,会导致任务队列中任务积压长时间得不到处理,这时可以使用线程池来处理。可以通过为每个线程维护一个任务队列来改进这种模型。
- 串行化处理模型
- Netty 具体线程模型
- Reactor 模式基于事件驱动,采用多路复用将事件分发给相应的 Handler 处理,非常适合处理海量 IO 的场景。
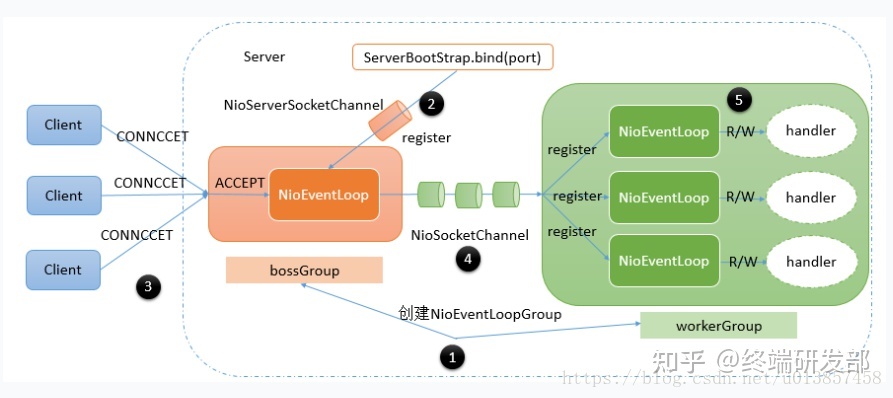
- 每个 NioEventLoop 都绑定了一个 Selector,所以在 Netty 的线程模型中,是由多个 Selecotr 在监听 I/O 就绪事件。而 Channel 注册到 Selector。
- 一个 Channel 绑定一个 NioEventLoop,相当于一个连接绑定一个线程,这个连接所有的 ChannelHandler 都是在一个线程中执行的,避免了多线程干扰。更重要的是 ChannelPipline 链表必须严格按照顺序执行的。单线程的设计能够保证 ChannelHandler 的顺序执行。
- 一个 NioEventLoop 的 selector 可以被多个 Channel 注册,也就是说多个 Channel 共享一个 EventLoop。EventLoop 的 Selecctor 对这些 Channel 进行检查。
- 相关问题
- 如何理解 NioEventLoop 和 NioEventLoopGroup
- NioEventLoop 实际上就是工作线程,可以直接理解为一个线程。NioEventLoopGroup 是一个线程池,线程池中的线程就是 NioEventLoop。
- 实际上 bossGroup 中有多个 NioEventLoop 线程,每个 NioEventLoop 绑定一个端口,也就是说,如果程序只需要监听 1 个端口的话,bossGroup 里面只需要有一个 NioEventLoop 线程就行了。
- 如何理解 NioEventLoop 和 NioEventLoopGroup
- 对于网络请求一般可以分为两个处理阶段,一是接收请求任务,二是处理网络请求。根据不同阶段处理方式分为以下几种线程模型:
- Netty 工作原理
- server 端工作原理
- client 端工作原理
- server 端工作原理
- Netty 的零拷贝
- 零复制(英语:Zero-copy;也译零拷贝)技术是指计算机执行操作时,CPU 不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。
- 在 OS 层面上的 Zero-copy 通常指避免在用户态(User-space)与内核态(Kernel-space)之间来回拷贝数据。而在 Netty 层面,零拷贝主要体现在对于数据操作的优化。
- Netty 中的零拷贝体现在以下几个方面:
- 使用 Netty 提供的 CompositeByteBuf 类, 可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝。
- ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝。
- 通过 FileRegion 包装的 FileChannel.tranferTo 实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题。
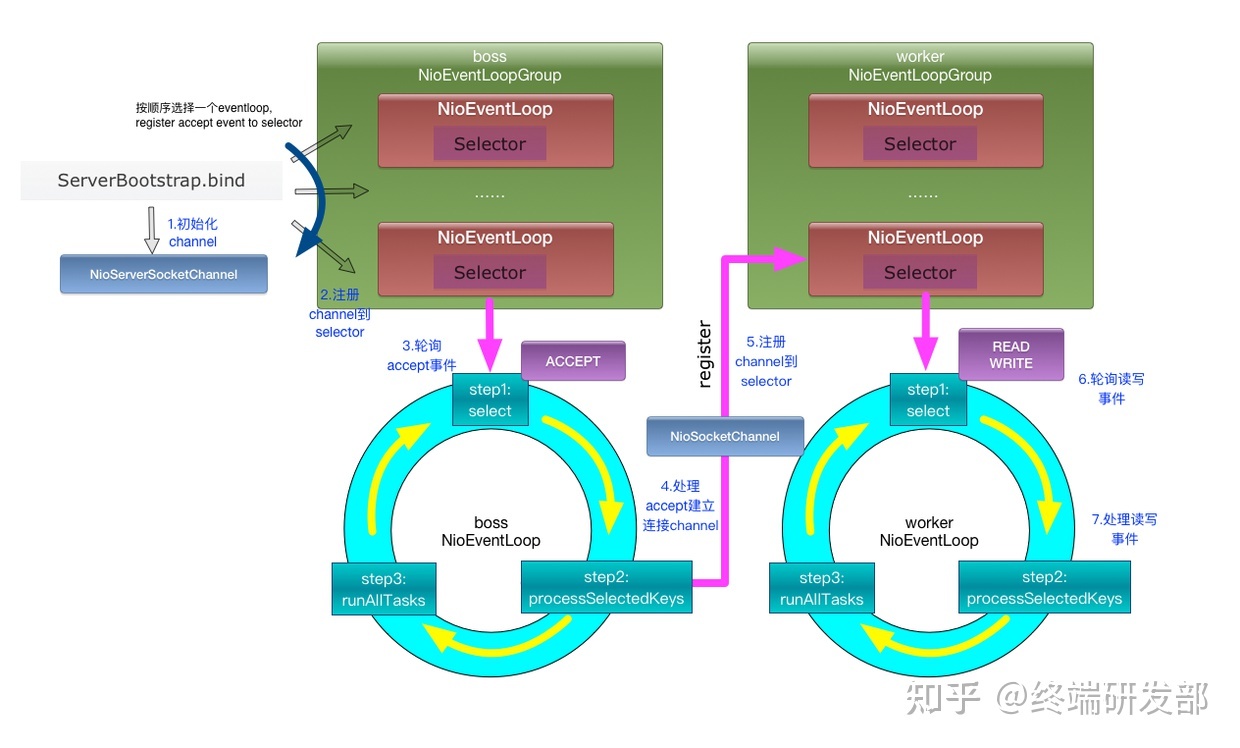
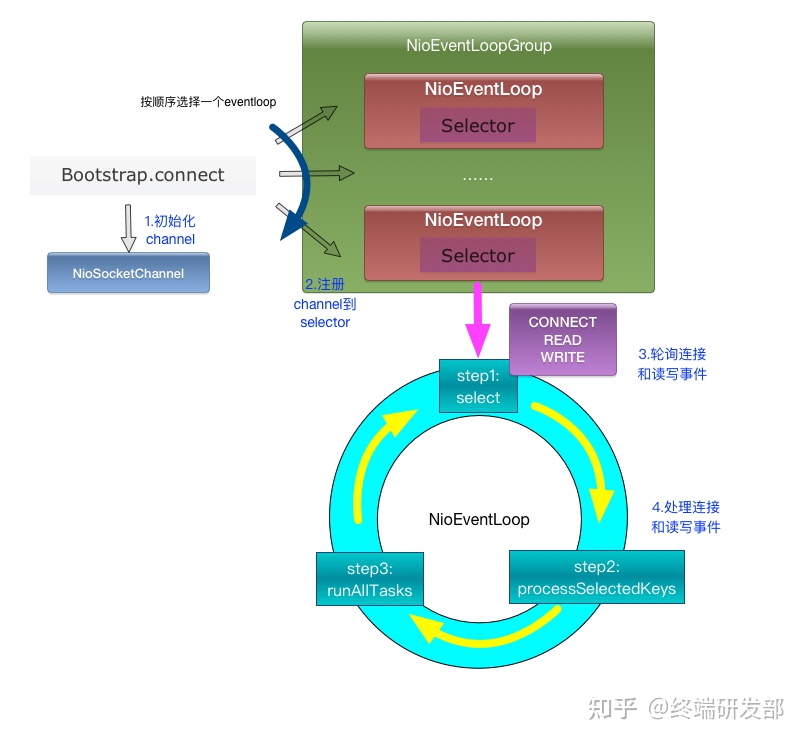
统计学系方法-第5章-决策树
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间伤的条件概率分布。其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则简历决策树模型。预测时,对新的数据,利用决策树模型进行分类。决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。
决策树模型与学习
决策树模型
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子节点;这时,每一个子节点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
决策树与 if-then 规则
可以将决策树看成一个 if-then 规则的集合。将决策树转换成 if-then 规则的过程是这样的:由决策树的根结点到叶结点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。决策树的路径或其对应的 if-then 规则集合具有一个重要的性质:互斥并且完备。这就是说,每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。这里所谓的覆盖是指实例的特征与路径上的特征一致或实例满足规则的条件。
决策树与条件概率分布
决策树还表示给定特征条件下类的条件概率分布。这一条件概率分布定义在特征空间的一个划分(partition)上。将特征空间划分为互不相交的单元(cell)或区域(region),并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的一条路径对应于划分中的一个单元。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。假设 X 为表示特征的随机变量,Y 为表示类的随机变量,那么这个条件概率分布可以表示为 P(Y|X)。X 取值于给定划分下单元的集合,Y 取值于类的集合。各叶结点(单元)上的条件概率往往偏向某一个类,即属于某一类的概率较大。决策树分类时将该结点的实例强行分到条件概率的那一类去。
决策树学习
决策树学习本质上是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有多个,也可能一个也没有。我们需要的是一个与训练数据矛盾较小的决策树,同时具有较好的泛化能力。从另一个角度看,决策树学习是由训练数据集估计条件概率模型。基于特征空间划分的类的条件概率模型有无穷多个。我们选择的条件概率模型应该不仅对训练数据有很好的拟合,而且对位置数据有很好的预测。
决策树学习用损失函数表示这一目标。决策树学习的损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。
以上方法生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。我们需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。
如果特征数量很多,也可以在决策树学习开始的时候,对特征进行选择,只留下对训练数据有足够分类能力的特征。
决策树学习算法包含特征选择、决策树的生成与决策树的剪枝过程。由于决策树表示一个条件概率分布,所以深浅不同的决策树对应着不同复杂度的概率模型。决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,相对地,决策树的剪枝则考虑全局最优。
特征选择
特征选择问题
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。通常特征选择的准则是信息增益或信息增益比。
信息增益
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设 X 是一个取有限个值的离散随机变量,其概率分布为 P(X=xi)=pi,i=1,2,…,n,则随机变量 X 的熵的定义为 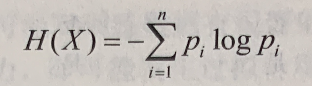
设有随机变量(X, Y),其联合概率分布为 P(X=xi, Y=yj)=pij, i=1,2,…,n; j=1,2,…,m,条件熵 H(Y|X) 表示在已知随机变量 X 的条件下随机变量 Y 的不确定性。随机变量 X 给定的条件下随机变量 Y 的条件熵(conditional entropy)H(Y|X),定义为 X 给定条件下 Y 的条件概率分布的熵对 X 的数学期望 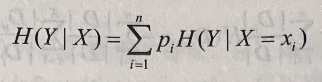 ,这里,pi=P(X=xi), i=1,2,…,n
,这里,pi=P(X=xi), i=1,2,…,n
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。此时如果有 0 概率,令 0log0=0。
信息增益(information gain)表示得知特征 X 的信息而使得类 Y 的信息不确定性减少的程度。
信息增益: 特征 A 对训练数据集 D 的信息增益 g(D, A),定义为集合 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差。即 g(D, A) = H(D) - H(D|A)
一般地,熵 H(Y) 与条件熵 H(Y|X) 之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
信息增益大的特征具有更强分类能力。
根据信息增益准则的特征选择方法是:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。


信息增益比
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。使用信息增益比(information gain ratio)可以对这一问题进行校正。

决策树的生成
ID3 算法
ID3 算法的核心是在决策树各个节点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点(root node)开始,对结点计算所有可能的特征信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子节点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。ID3 相当于用极大似然法进行概率模型的选择。


ID3 算法只有树的生成,所以该算法生成的树容易产生过拟合。
C4.5 的生成算法
C4.5 算法与 ID3 算法相似,C4.5 算法对 ID3 算法进行了改进。C4.5 在生成的过程中,用信息增益比来选择特征。
决策树的剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
在决策树学习中将已生成的树进行简化的过程称为剪枝(pruning)。具体地,剪枝从已生成的树上裁掉一些子树或叶结点,并将其根结点或父节点作为新的叶结点,从而简化分类树模型。


剪枝,就是当 α 确定时,选择损失函数最小的模型,即损失函数最小的子树。当 α 值确定时,子树越大,往往与训练数据的拟合越好,但是模型的复杂度就越高;相反,子树越小,模型的复杂度就越低,但是往往与训练数据的拟合不好。损失函数正好表示了对两者的平衡。
可以看出,决策树生成只考虑了通过提高信息增益(或信息增益比)对训练数据进行更好的拟合。而决策树剪枝通过优化损失函数还考虑减小模型复杂度。决策树生成学习局部的模型,而决策树剪枝学习整体的模型。



CART 算法
分类与回归树(classification and regression tree, CART)模型由 Breiman 等人在 1984年提出,是应用广泛的决策树学习方法。CART 同样由特征选择、树的生成及剪枝组成,即可以用于分类也可以用于回归。以下将用于分类与回归的树统称为决策树。
CART 是在给定输入随机变量 X 条件下输出随机变量 Y 的条件概率分布的学习方法。CART 假设决策树是二叉树,内部结点特征的取值为“是”与“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
CART 算法由以下两步组成:
- 决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
- 决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
CART 生成
决策树的生成就是递归地构建二叉决策树的过程。对回归树用平方误差最小化准则,对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。
回归树的生成

分类树的生成

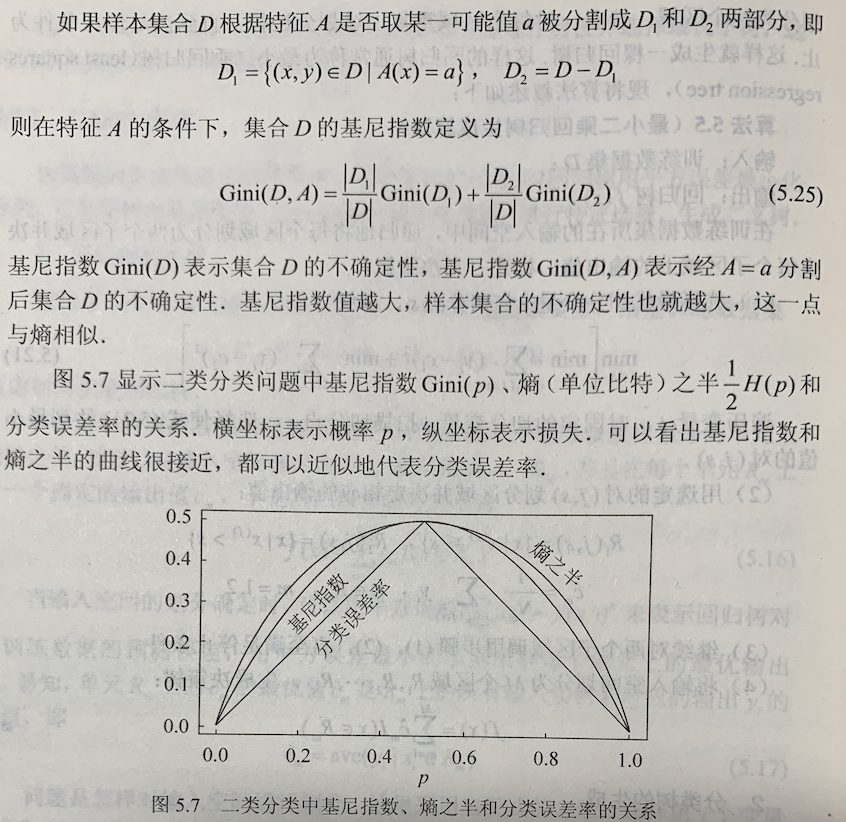


CART 剪枝
CART 剪枝算法从“完全生长”的决策树的底端剪去一些子树,使决策树变小(模型变简单),从而能够对未知数据有更准确的预测。CART 剪枝算法由两步组成:首先从生成算法产生的决策树 T0底端开始不断剪枝,直到 T0 的根结点,形成一个子树序列 {T0, T1,…Tn};然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。

附西瓜书第4章-决策树部分内容
决策树的剪枝(pruning)的基本策略有“预剪枝”(prepruning)和“后剪枝”(postpruning)。预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为子节点。
后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
Python-numpy-newaxis
转自:https://blog.csdn.net/xtingjie/article/details/72510834
numpy中包含的newaxis可以给原数组增加一个维度
np.newaxis放的位置不同,产生的新数组也不同
一维数组
1 |
|
由以上代码可以看出,当把newaxis放在前面的时候
以前的shape是5,现在变成了1×5,也就是前面的维数发生了变化,后面的维数发生了变化
而把newaxis放后面的时候,输出的新数组的shape就是5×1,也就是后面增加了一个维数
所以,newaxis放在第几个位置,就会在shape里面看到相应的位置增加了一个维数
如下:
1 | x = np.random.randint(1, 8, size=(2, 3, 4)) |
一般问题
经常会遇到这样的问题,需要从数组中取出一部分的数据,也就是取出“一片”或者“一条”
比如需要从二维数组里面抽取一列
取出来之后维度却变成了一维
假如我们需要将其还原为二维,就需要上面的方法了
Python-numpy-索引与切片
参考:https://www.numpy.org.cn/user_guide/numpy_basics/indexing.html
索引
单个元素索引
1 | >>> x = np.arange(10) |
指定的每个索引都会选择与所选维度的其余部分相对应的数组。在上面的例子中,选择0表示长度为5的剩余维度未指定,并且返回的是具有该维度和大小的数组。必须注意的是,返回的数组不是原始数据的副本,而是指向与原始数组相同的内存值。在这种情况下,返回第一个位置(0)处的一维数组。因此,在返回的数组上使用单个索引会导致返回一个元素。那是:
1 | >>> x[0][2] |
因此,请注意,x[0, 2] = x[0][2], 但是第二种情况效率更低,因为一个新的临时数组在第一个索引后创建了,这个临时数组随后才被2这个数字索引。
其他索引选项
可以对数组进行切片和步进,以提取具有相同数量维数的数组,但其大小与原始数据不同。切片和跨步的工作方式与对列表和元组完全相同,除此之外它们还可以应用于多个维度。
1 | >>> x = np.arange(10) |
请注意,数组切片不会复制内部数组数据,但也会产生原始数据的新视图。
索引数组
数组索引指的是使用方括号([])来索引数组值。有很多选项来索引,这使numpy索引很强大,但功能上的强大也带来一些复杂性和潜在的混乱。
索引数组必须是整数类型。数组中的每个值指示数组中要使用哪个值来代替索引。
1 | >>> x = np.arange(10,1,-1) |
索引值超出范围是错误的:
1 | >>> x[np.array([3, 3, 20, 8])] |
一般来说,使用索引数组时返回的是与索引数组具有相同形状的数组,但是索引数组的类型和值。作为一个例子,我们可以使用多维索引数组来代替:
1 | >>> x[np.array([[1,1],[2,3]])] |
索引多维数组
对多维数组进行索引时,情况会变得更加复杂,特别是对于多维索引数组。这些往往是更常用的用途,但它们是允许的,并且它们对于一些问题是有用的。我们将从最简单的多维情况开始:
1 | >>> y = np.arange(35).reshape(5,7) |
在这种情况下,如果索引数组具有匹配的形状,并且索引数组的每个维都有一个索引数组,则结果数组具有与索引数组相同的形状,并且这些值对应于每个索引集的索引在索引数组中的位置。在此示例中,两个索引数组的第一个索引值为0,因此结果数组的第一个值为y[0, 0]。下一个值是y[2, 1],最后一个是y[4, 2]。
广播机制允许索引数组与其他索引的标量组合。结果是标量值用于索引数组的所有对应值:
1 | >>> y[np.array([0,2,4]), 1] |
跳到复杂性的下一个级别,可以只用索引数组部分索引数组。理解在这种情况下会发生什么需要一些思考。例如,如果我们只使用一个索引数组与y:
1 | >>> y[np.array([0,2,4])] |
什么结果是一个新的数组的结构,其中索引数组的每个值从被索引的数组中选择一行,并且结果数组具有结果形状(行的大小,数字索引元素)。
这可能有用的一个示例是用于颜色查找表,我们想要将图像的值映射到RGB三元组中进行显示。查找表可能有一个形状(nlookup,3)。使用带有dtype = np.uint8(或任何整数类型,只要值与查找表的边界)形状(ny,nx)的图像索引这样一个数组将导致一个形状数组(ny,nx, 3)RGB值的三倍与每个像素位置相关联。
通常,resulant数组的形状将是索引数组形状(或所有索引数组广播的形状)与索引数组中任何未使用的维(未索引的维)的形状的串联。
布尔值或掩码索引数组
用作索引的布尔数组的处理方式完全不同于索引数组。布尔数组的形状必须与被索引数组的初始维相同。在最直接的情况下,布尔数组具有相同的形状:
1 | >>> b = y>20 |
与整数索引数组不同,在布尔情况下,结果是一维数组,其中包含索引数组中所有对应于布尔数组中所有真实元素的元素。索引数组中的元素始终以行优先(C样式)顺序进行迭代和返回。结果也与y[np.nonzero(b)]相同。与索引数组一样,返回的是数据的副本,而不是像切片一样获得的视图。
如果y比b的维数更高,则结果将是多维的。例如:
1 | >>> b[:,5] # use a 1-D boolean whose first dim agrees with the first dim of y |
这里第4行和第5行是从索引数组中选择出来的,并组合起来构成一个二维数组。
一般来说,当布尔数组的维数小于被索引的数组时,这相当于y[b, ...]
组合索引和切片
索引数组可以与切片组合。例如:
1 | >>> y[np.array([0,2,4]),1:3] |
实际上,切片被转换为索引数组np.array([[1,2]])(形状(1,2)),该数组与索引数组一起广播以产生形状的结果数组(3,2) 。
同样,切片可以与广播布尔指数结合使用:
1 | >>> y[b[:,5],1:3] |
结构化索引工具
为了便于将数组形状与表达式和赋值相匹配,可以在数组索引中使用np.newaxis对象来添加大小为1的新维度。例如:
1 | >>> y.shape |
请注意,数组中没有新元素,只是增加了维度。这可以很方便地以一种其他方式需要明确重塑操作的方式组合两个数组。例如:
1 | >>> x = np.arange(5) |
省略号语法可以用于指示完整地选择任何剩余的未指定的维度。例如:
1 | >>> z = np.arange(81).reshape(3,3,3,3) |
这相当于:
1 | >>> z[1,:,:,2] |
给被索引的数组赋值
如前所述,可以使用单个索引,切片以及索引和掩码数组来选择数组的子集。分配给索引数组的值必须是形状一致的(形状与索引产生的形状相同或相同)。例如,允许为切片分配一个常量:
1 | >>> x = np.arange(10) |
或者正确大小的数组:
1 | >>> x[2:7] = np.arange(5) |
请注意,如果将较高类型分配给较低类型(在int类型中添加浮点数(floats))或甚至导致异常(将复数分配给int/float类型),分配可能会导致更改:
1 | >>> x[1] = 1.2 |
与一些引用(如数组和掩码索引)不同,赋值通常是对数组中的原始数据进行赋值的(事实上,没有其他意义了!)。但请注意,有些行为可能不会如人们所期望的那样行事。这个特殊的例子通常令人惊讶:
1 | >>> x = np.arange(0, 50, 10) |
人们预计第一个地点会增加3。实际上,它只会增加1。原因是因为从原始数据(作为临时数据)中提取了一个新的数组,其中包含1,1,1,1,1,1的值,则将值1添加到临时数据中,然后将临时数据分配回原始数组。因此,x[1]+1处的数组值被分配给x[1]三次,而不是递增3次。
处理程序中可变数量的索引
索引语法非常强大,但在处理可变数量的索引时受到限制。例如,如果你想编写一个可以处理各种维数参数的函数,而不必为每个可能维数编写特殊的代码,那又怎么办?如果向元组提供元组,则该元组将被解释为索引列表。例如(使用数组z的前一个定义):
1 | >>> z = np.arange(81).reshape(3,3,3,3) |
所以可以使用代码来构造任意数量的索引的元组,然后在索引中使用这些元组。
切片可以通过在Python中使用slice()函数在程序中指定。例如:
1 | >>> indices = (1,1,1,slice(0,2)) # same as [1,1,1,0:2] |
同样,省略号可以通过使用省略号对象的代码指定:
````
indices = (1, Ellipsis, 1) # same as [1,…,1]
z[indices]
array([[28, 31, 34],
[37, 40, 43],
[46, 49, 52]])
1 | 由于这个原因,可以直接使用np.where()函数的输出作为索引,因为它总是返回索引数组的元组。 |
z[[1,1,1,1]] # produces a large array
array([[[[27, 28, 29],
[30, 31, 32], …
z[(1,1,1,1)] # returns a single value
40
```
统计学系方法-第4章-朴素贝叶斯法
朴素贝叶斯(naive Bayes)法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率的最大输出 y。
朴素贝叶斯法的学习与分类
基本方法
朴素贝叶斯法对条件概率分布作了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯法也由此得名。具体地,条件独立性假设是 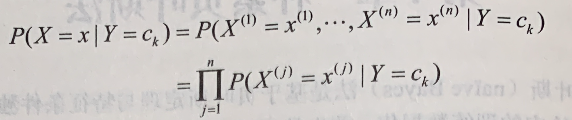
朴素贝叶斯法实际上学习到生成数据的机制,所以属于生成模型。条件独立假设等于是说用于分类的特征在类确定的条件下都是条件独立的。这一假设使朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
后验概率计算根据贝叶斯定理进行: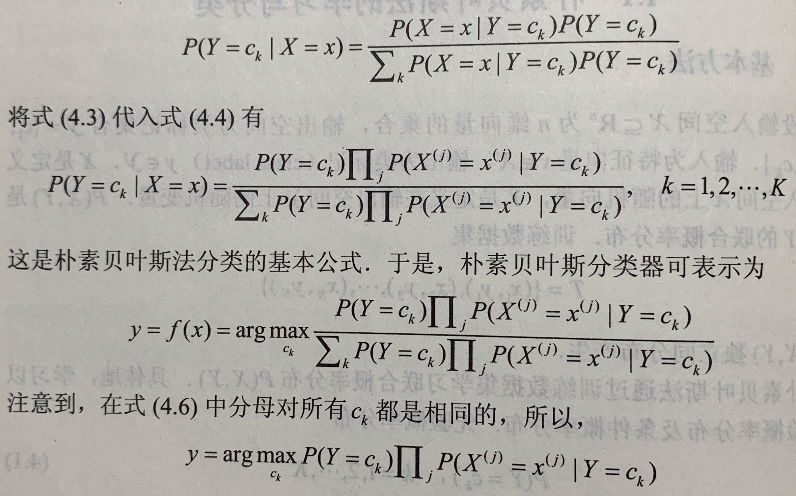
朴素贝叶斯法的参数估计
极大似然估计

学习与分类算法
朴素贝叶斯算法(naive Bayes algorithm)
贝叶斯估计
用极大似然估计可能会出现所要估计的概率为 0 的情况。这时会影响到后验概率的计算结果,使分类产生偏差。解决这一问题的方法是采用贝叶斯估计。具体地,条件概率的贝叶斯估计是 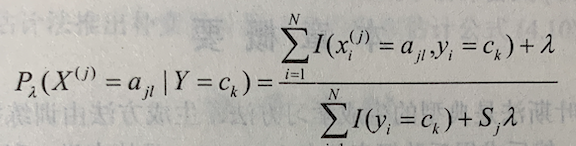 式中 λ>=0。等价于在随机变量各个取值的频数上赋予一个正数 λ>0。当 λ=0 时就是极大似然估计。常取 λ=1,这时称为拉普拉斯平滑(Laplace smoothing)。显然,对任何 l=1,2,…,K。有
式中 λ>=0。等价于在随机变量各个取值的频数上赋予一个正数 λ>0。当 λ=0 时就是极大似然估计。常取 λ=1,这时称为拉普拉斯平滑(Laplace smoothing)。显然,对任何 l=1,2,…,K。有 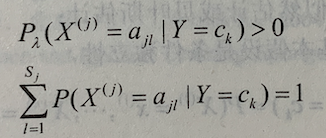 。同样,先验概率的贝叶斯估计是
。同样,先验概率的贝叶斯估计是 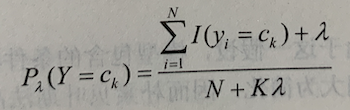
A基本概念
中心极限定理:说明的是在一定条件下,大量独立随机变量的平均数是以正态分布为极限的。而大数定律只是揭示了大量随机变量的平均结果,但没有涉及到随机变量的分布的问题。
大数定律
- 伯努利大数定律:证明了在多次相同的条件的重复试验中,频率有越接近一稳定值的趋势。也告诉了我们当实验次数很大时,可以用事件发生的频率来代替事件的概率。
- 辛钦大数定律:用算术平均值来近似实际真值是合理的,而在数理统计中,用算术平均值来估计数学期望就是根据此定律,这一定律使算术平均值的法则有了理论依据。
- 切比雪夫大数定律:随着样本容量n的增加,样本平均数将接近于总体平均数。 从而为统计推断中依据样本平均数估计总体平均数提供了理论依据。 同分布,相较于伯努利大数定律和辛钦大数定律更具一般性。
百分位数(percentile):如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列。如,处于p%位置的值称第p百分位数。