转自:https://www.cnblogs.com/huanongying/p/7021555.html
一 本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB
事务的基本要素(ACID)
原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如 A 向 B 转账,不可能 A 扣了钱,B 却没收到。
隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B 不能向这张卡转账。
持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
事务的并发问题
脏读:事务 A 读取了事务B更新的数据,然后 B 回滚操作,那么 A 读取到的数据是脏数据
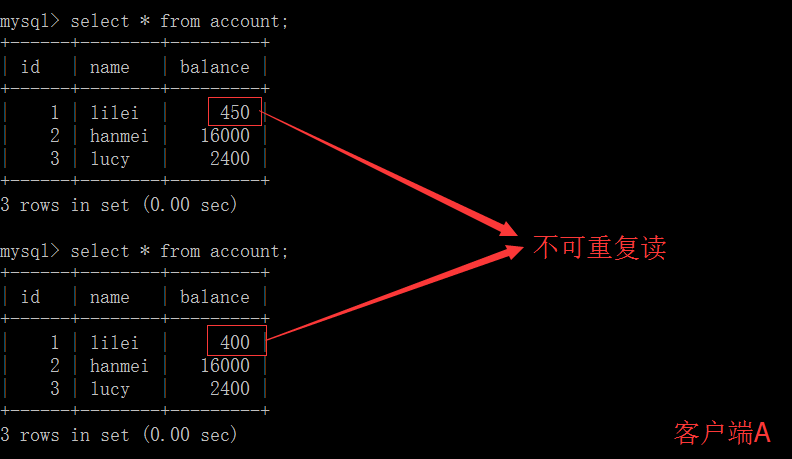
不可重复读:事务 A 多次读取同一数据,事务 B 在事务 A 多次读取的过程中,对数据作了更新并提交,导致事务 A 多次读取同一数据时,结果不一致。
幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为 ABCDE 等级,但是系统管理员 B 就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
MySQL 事务隔离级别
事务隔离级别
脏读
不可重复读
幻读
读未提交(read-uncommitted)
是
是
是
不可重复读(read-committed)
否
是
是
可重复读(repeatable-read)
否
否
是
串行化(serializable)
否
否
否
mysql 默认的事务隔离级别为 repeatable-read
用例子说明各个隔离级别的情况 读未提交
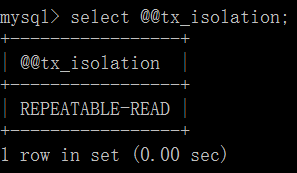
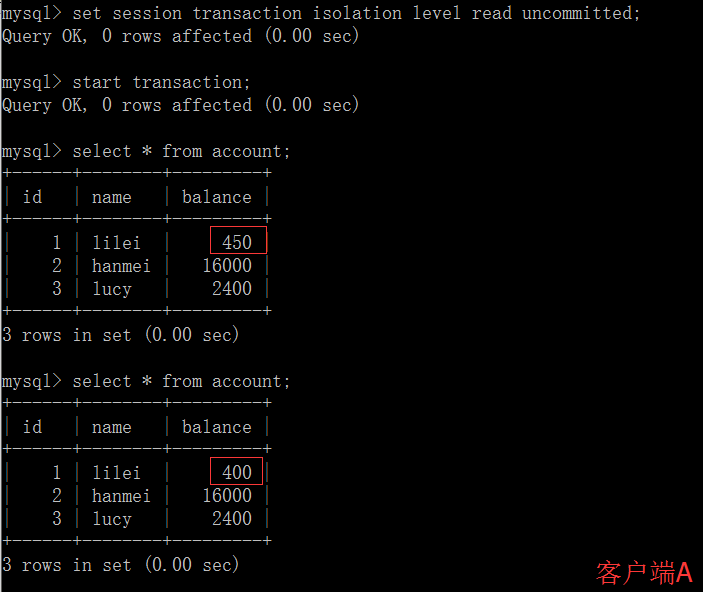
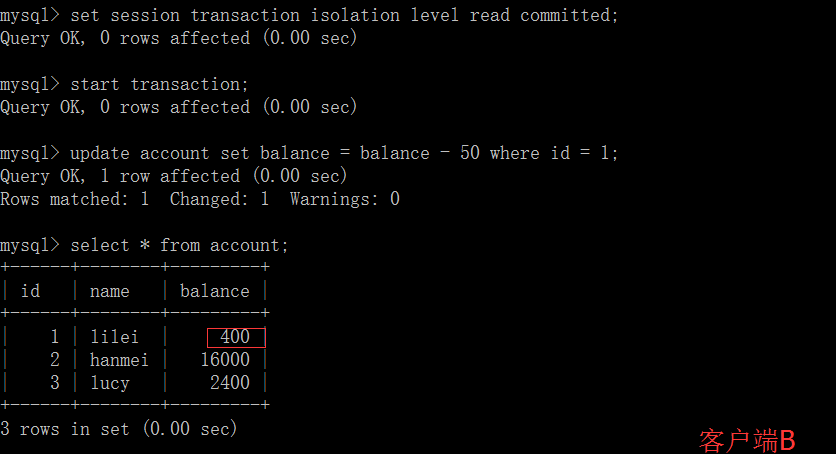
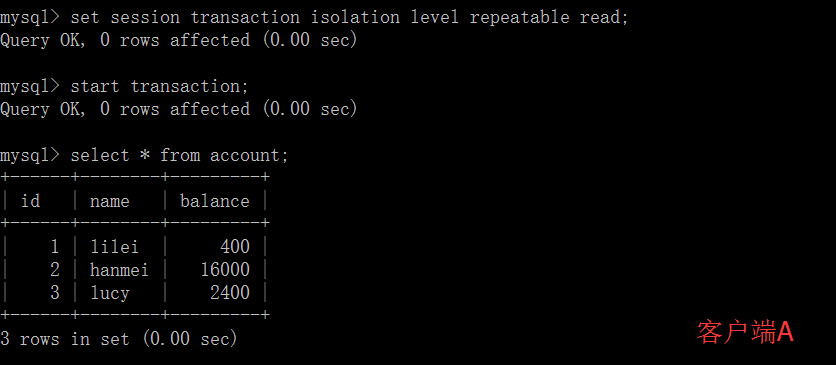
打开一个客户端 A,并设置当前事务模式为 read uncommitted(未提交读),查询表 account 的初始值:
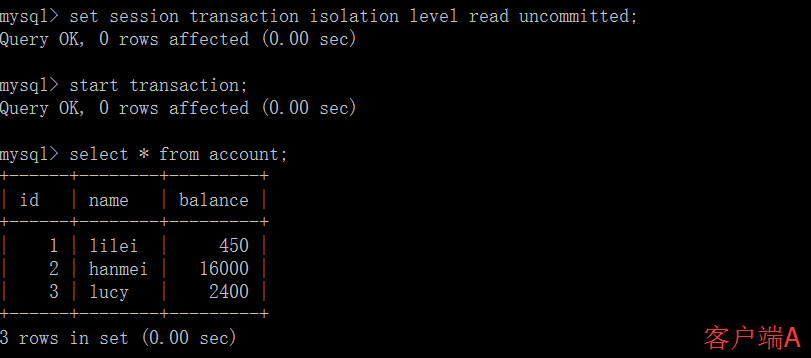
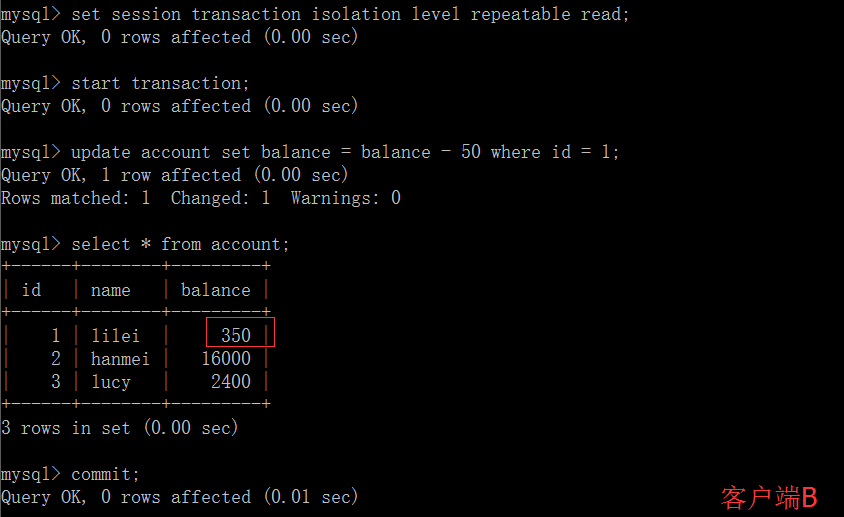
在客户端 A 的事务提交之前,打开另一个客户端 B,更新表 account:
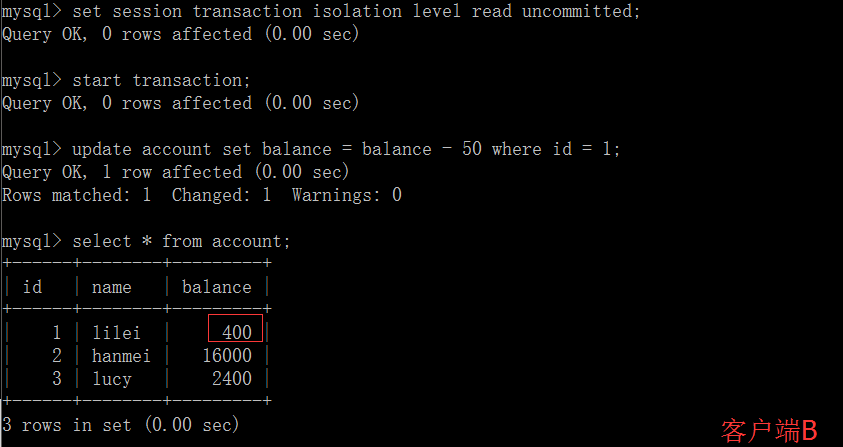
这时,虽然客户端 B 的事务还没提交,但是客户端 A 就可以查询到 B 已经更新的数据:
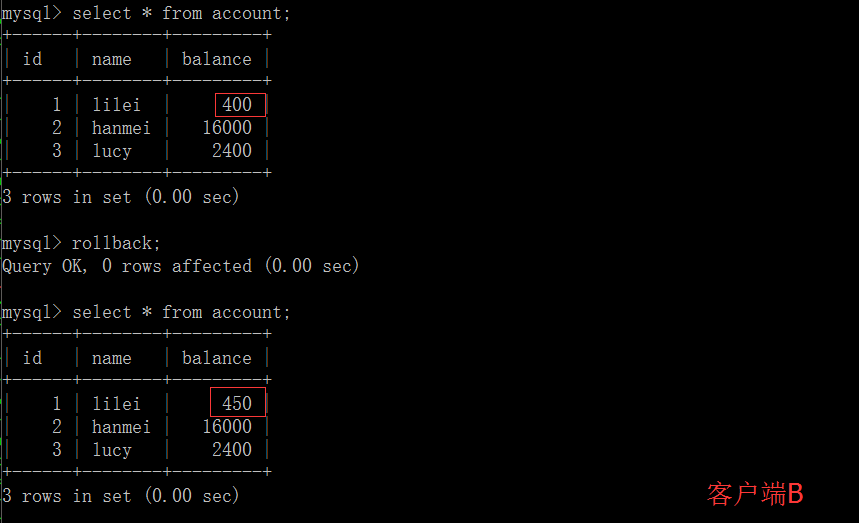
一旦客户端 B 的事务因为某种原因回滚,所有的操作都将会被撤销,那客户端 A 查询到的数据其实就是脏数据:
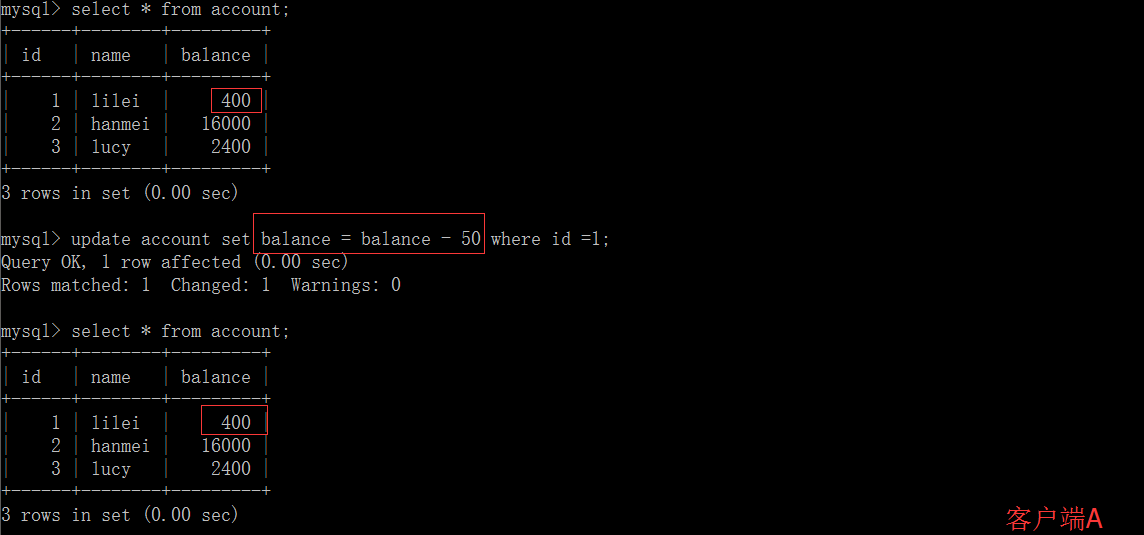
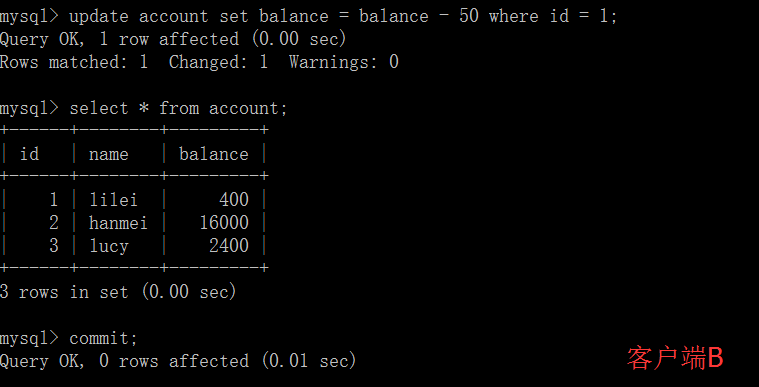
在客户端 A 执行更新语句 update account set balance = balance - 50 where id =1,lilei 的 balance 没有变成 350,居然是 400,是不是很奇怪,数据不一致啊,如果你这么想就太天真 了,在应用程序中,我们会用 400-50=350,并不知道其他会话回滚了,要想解决这个问题可以采用读已提交的隔离级别
读已提交
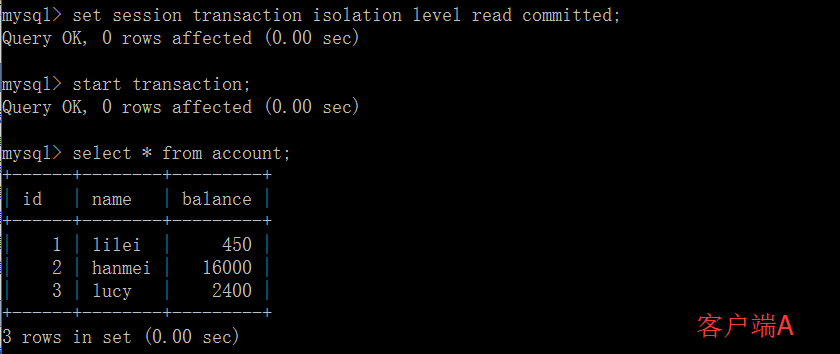
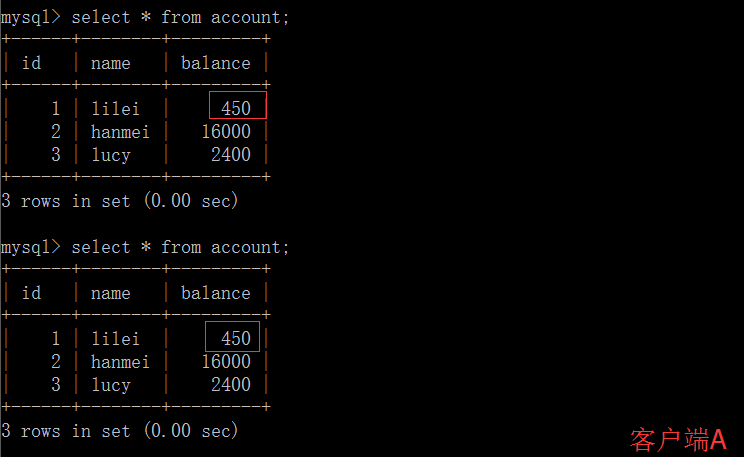
打开一个客户端A,并设置当前事务模式为 read committed(未提交读),查询表 account 的所有记录:
在客户端 A 的事务提交之前,打开另一个客户端 B,更新表 account:
这时,客户端B的事务还没提交,客户端 A 不能查询到B已经更新的数据,解决了脏读问题:
客户端 B 的事务提交
客户端 A 执行与上一步相同的查询,结果与上一步不一致,即产生了不可重复读的问题
可重复读
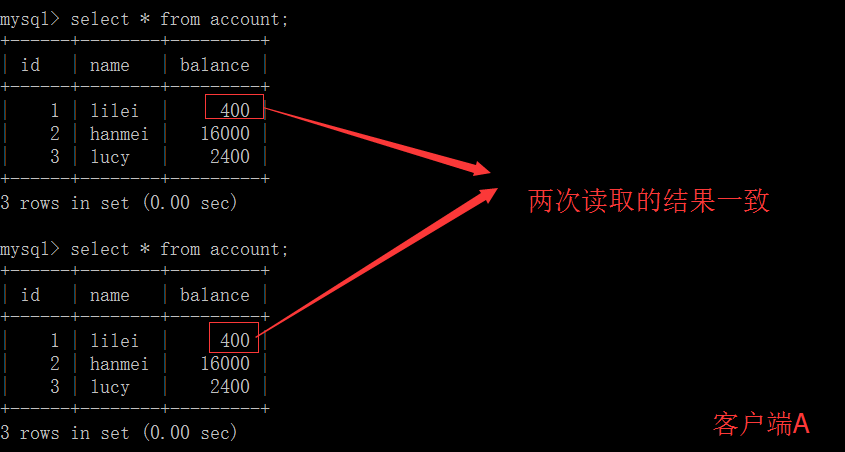
打开一个客户端 A,并设置当前事务模式为 repeatable read,查询表 account 的所有记录
在客户端 A 的事务提交之前,打开另一个客户端 B,更新表 account 并提交
在客户端 A 查询表 account 的所有记录,与步骤(1)查询结果一致,没有出现不可重复读的问题
在客户端 A,接着执行 update balance = balance - 50 where id = 1,balance 没有变成 400-50=350,lilei 的 balance 值用的是步骤(2)中的 350 来算的,所以是 300,数据的一致性倒是没有被破坏。可重复读的隔离级别下使用了 MVCC 机制,select 操作不会更新版本号,是快照读(历史版本);insert、update 和 delete 会更新版本号,是当前读(当前版本)。
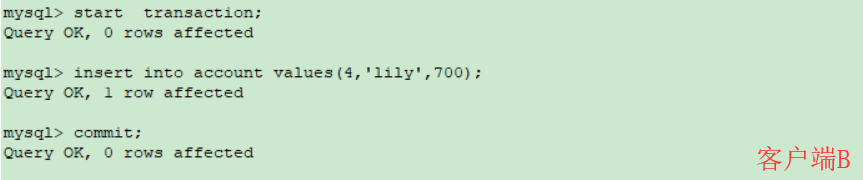
重新打开客户端 B,插入一条新数据后提交
在客户端 A 查询表 account 的所有记录,没有查出新增数据,所以没有出现幻读
串行化
打开一个客户端A,并设置当前事务模式为 serializable,查询表 account 的初始值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 10000 | | 2 | hanmei | 10000 | | 3 | lucy | 10000 | | 4 | lily | 10000 | +------+--------+---------+ 4 rows in set (0.00 sec)
打开一个客户端 B,并设置当前事务模式为 serializable,插入一条记录报错,表被锁了插入失败,mysql 中事务隔离级别为 serializable 时会锁表,因此不会出现幻读的情况,这种隔离级别并发性极低,开发中很少会用到。
1 2 3 4 5 6 7 8 mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
补充:
事务隔离级别为读提交时,写数据只会锁住相应的行
事务隔离级别为可重复读时,如果检索条件有索引(包括主键索引)的时候,默认加锁方式是 next-key 锁;如果检索条件没有索引,更新数据时会锁住整张表。一个间隙被事务加了锁,其他事务是不能在这个间隙插入记录的,这样可以防止幻读。
事务隔离级别为串行化时,读写数据都会锁住整张表
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
MYSQL MVCC 实现机制参考链接:https://blog.csdn.net/whoamiyang/article/details/51901888
关于 next-key 锁可以参考链接:https://blog.csdn.net/bigtree_3721/article/details/73731377
转自:https://www.cnblogs.com/rjzheng/p/9955395.html
二 引言 大家在面试中一定碰到过
说说事务的隔离级别吧?
老实说,事务隔离级别这个问题,无论是校招还是社招,面试官都爱问!然而目前网上很多文章,说句实在话啊,我看了后我都怀疑作者弄懂没!因为他们对可重复读(Repeatable Read)和串行化(serializable)的解析实在是看的我一头雾水!
再加上很多书都说可重复读解决了幻读问题,比如《mysql技术内幕–innodb存储引擎》等,不一一列举了,因此网上关于事务隔离级别的文章大多是有问题的,所以再开一文说明!
本文所讲大部分内容,皆有官网作为佐证,因此对本文内容你可以看完后,你完全可以当概念记在脑海里,除非官网的开发手册是错的,否则应当无误!
可重复读(Repeatable Read)是否真的解决幻读的问题!
正文 开始我先提一下,根据事务的隔离级别不同,会有三种情况发生。即脏读、不可重复读、幻读。这里我先不提这三种情况的定义,后面在讲隔离级别的时候会补上。
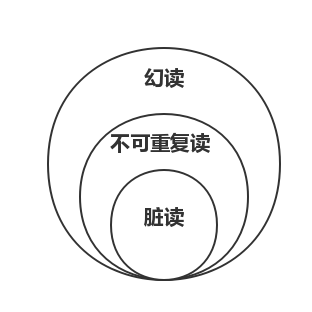
这里,大家记住一点,根据脏读、不可重复读、幻读定义来看(自己总结,官网没有),有如下包含关系:
那么,这张图怎么理解呢?
即,如果发生了脏读,那么不可重复读和幻读是一定发生的。因为拿脏读的现象,用不可重复读,幻读的定义也能解释的通。但是反过来,拿不可重复读的现象,用脏读的定义就不一定解释的通了!
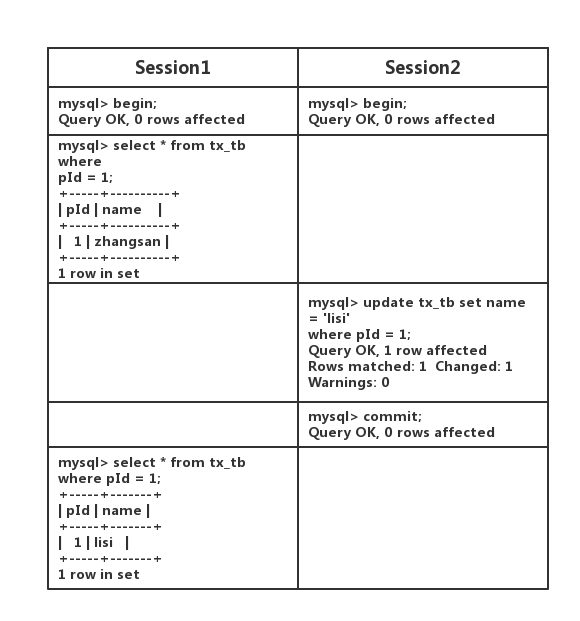
假设有表 tx_tb 如下,pId 为主键
读未提交(READ_UNCOMMITTED) 其实这个从隔离名字就可以看出来,一个事务可以读到另一个事务未提交的数据!为了便于说明,我简单的画图说明!
如图所示,一个事务检索的数据被另一个未提交的事务给修改了。
官网对脏读定义的地址为https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_dirty_read
其内容为
**dirty read
An operation that retrieves unreliable data, data that was updated by another transaction but not yet committed.
**
翻译过来就是
检索操作出来的数据是不可靠的,是可以被另一个未提交的事务修改的!
你会发现,我们的演示结果和官网对脏读的定义一致。根据我们最开始的推理,如果存在脏读,那么不可重复读和幻读一定是存在的。
读已提交(READ_COMMITTED) 这个也能看的出来,一个事务能读到另一个事务已提交的数据!为了便于说明,我简单的画图说明!
如图所示,一个事务检索的数据只能被另一个已提交的事务修改。
官网对不可重复读定义的地址为https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_non_repeatable_read
其内容为
**non-repeatable read
The situation when a query retrieves data, and a later query within the same transaction retrieves what should be the same data, but the queries return different results (changed by another transaction committing in the meantime).
**
翻译过来就是
一个查询语句检索数据,随后又有一个查询语句在同一个事务中检索数据,两个数据应该是一样的,但是实际情况返回了不同的结果。!
ps:作者注,这里的不同结果,指的是在行不变的情况下(专业点说,主键索引没变),主键索引指向的磁盘上的数据内容变了。如果主键索引变了,比如新增一条数据或者删除一条数据,就不是不可重复读。
显然,我们这个现象符合不可重复读的定义。下面,大家做一个思考:
这个不可重复读的定义,放到脏读的现象里是不是也可以说的通。显然脏读的现象,也就是读未提交(READ_UNCOMMITTED)的那个例子,是不是也符合在同一个事务中返回了不同结果!
但是反过来就不一定通了,一个事务 A 中查询两次的结果在被另一个事务 B 改变的情况下,如果事务 B 未提交就改变了事务 A 的结果,就属于脏读,也属于不可重复读。如果该事务B提交了才改变事务A的结果,就不属于脏读,但属于不可重复读。
可重复读(REPEATABLE_READ) 这里,我改变一下顺序,先上幻读的定义
官网对幻读定义的地址为https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_phantom
phantom
A row that appears in the result set of a query, but not in the result set of an earlier query. For example, if a query is run twice within a transaction, and in the meantime, another transaction commits after inserting a new row or updating a row so that it matches the WHERE clause of the query.
翻译过来就是
在一次查询的结果集里出现了某一行数据,但是该数据并未出现在更早的查询结果集里。例如,在一次事务里进行了两次查询,同时另一个事务插入某一行或更新某一行数据后(该数据符合查询语句里 where 后的条件),并提交了!
好了,接下来上图,大家自己评定该现象是否符合幻读的定义
显然,该现象是符合幻读的定义的。同一事务的两次相同查询出现不同行。下面,大家做一个思考:
这个幻读的定义,放到不可重复读的现象里是不是也可以说的通。大家自行思考!
反过来就不一定通了。事务第二次查询出了一个数据,但是该数据并未出现在第一次查询的结果集里。如果该数据是修改数据,那么该现象既属于不可重复读,也属于幻读。如果该数据是新增或删除的数据,那该现象就不属于不可重复读,但属于幻读。
接下来说一下,为什么很多文章都产生误传,说是可重复读可以解决幻读问题!原因出自官网的一句话(地址是:https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-record-locks )
原文内容如下
By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 14.7.4, “Phantom Rows”).
按照原本这句话的意思,应该是
InnoDB 默认用了 REPEATABLE READ。在这种情况下,使用 next-key locks 解决幻读问题!
结果估计,某个国内翻译人员翻着翻着变成了
InnoDB 默认用了 REPEATABLE READ。在这种情况下,可以解决幻读问题!
然后大家继续你抄我,我抄你,结果你懂的!
显然,漏了”使用了 next-key locks!”这个条件后,意思完全改变,我们在该隔离级别下执行语句
1 select * from tx_tb where pId >= 1;
是快照读,是不加任何锁的,根本不能解决幻读问题,除非你用
1 select * from tx_tb where pId >= 1 lock in share mode;
这样,你就用上了next-key locks,解决了幻读问题!
串行读(SERIALIZABLE_READ) 在该隔离级别下,所有的 select 语句后都自动加上 lock in share mode。因此,在该隔离级别下,无论你如何进行查询,都会使用 next-key locks。所有的 select 操作均为当前读!
OK,注意看上表红色部分!就是因为使用了 next-key locks,innodb 将 PiD=1 这条索引记录,和 $(1,++∞)$ 这个间隙锁住了。其他事务要在这个间隙上插数据,就会阻塞,从而防止幻读发生!
有的人会说,你这第二次查询的结果,也变了啊,明显和第一次查询结果不一样啊?对此,我只能说,请看清楚啊。这是被自己的事务改的,不是被其他事物修改的。这不算是幻读,也不是不可重复读。
总结 上面罗里吧嗦一大堆,最后来一个表格做总结吧,你面试答这个表就行。上面的一切是为了这张表做准备!
隔离级别
脏读
不可重复读
幻读
读未提交
是
是
是
不可重复读
否
是
是
可重复读
否
否
是
串行化
否
否
否