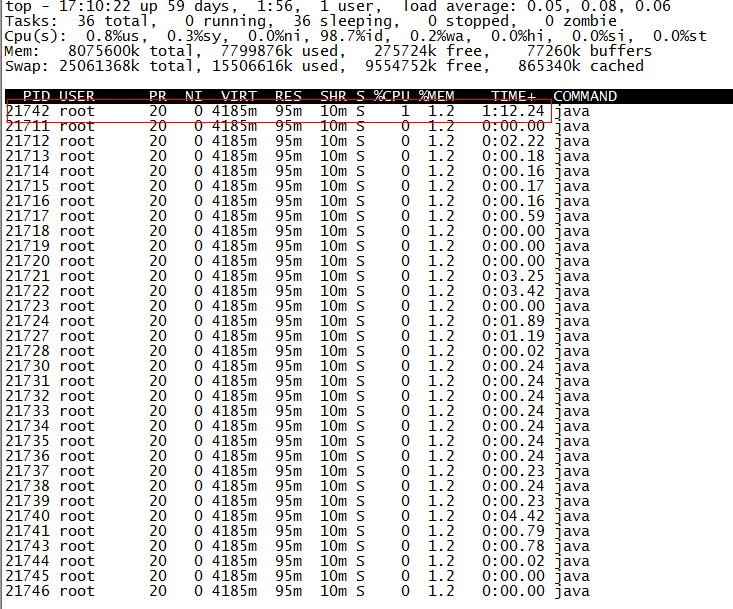
root@ubuntu:/# jmap -heap 21711 Attaching to process ID 21711, please wait... Debugger attached successfully. Server compiler detected. JVM version is 20.10-b01
using thread-local object allocation. Parallel GC with 4 thread(s)
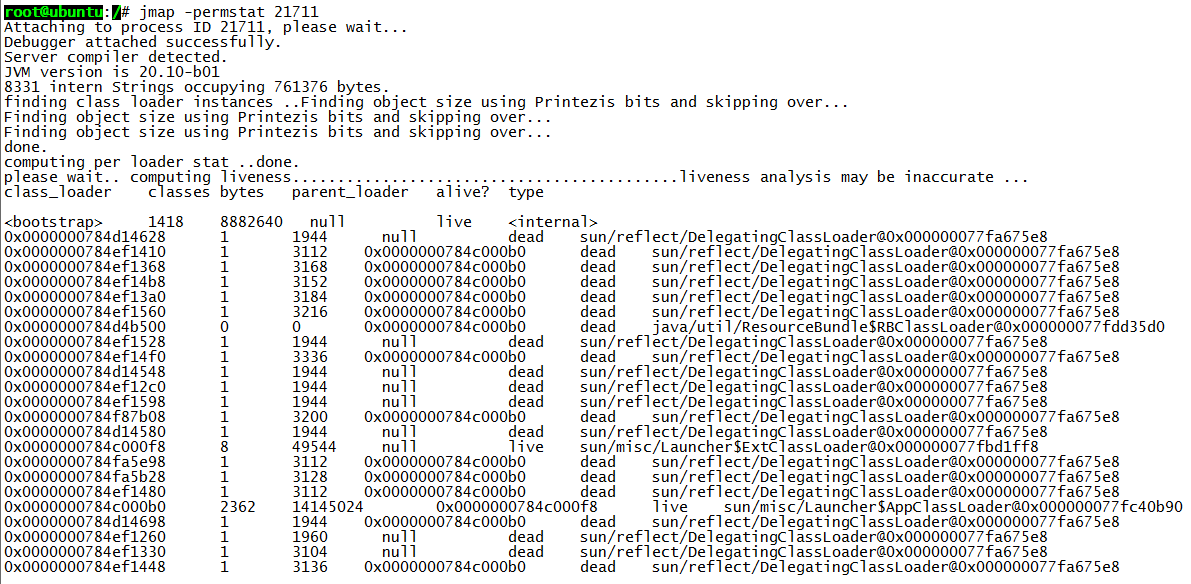
root@ubuntu:/# jmap -dump:format=b,file=/tmp/dump.dat 21711 Dumping heap to /tmp/dump.dat ... Heap dump file created
dump 出来的文件可以用 MAT、VisualVM 等工具查看,这里用 jhat 查看:
1 2 3 4 5 6 7 8 9 10
root@ubuntu:/# jhat -port 9998 /tmp/dump.dat Reading from /tmp/dump.dat... Dump file created Tue Jan 28 17:46:14 CST 2014 Snapshot read, resolving... Resolving 132207 objects... Chasing references, expect 26 dots.......................... Eliminating duplicate references.......................... Snapshot resolved. Started HTTP server on port 9998 Server is ready.
Option Name and Value Description Default --------------------- ----------- ------- heap=dump|sites|all heap profiling all cpu=samples|times|old CPU usage off monitor=y|n monitor contention n format=a|b text(txt) or binary output a file=<file> write data to file java.hprof[.txt] net=<host>:<port> send data over a socket off depth=<size> stack trace depth 4 interval=<ms> sample interval in ms 10 cutoff=<value> output cutoff point 0.0001 lineno=y|n line number in traces? y thread=y|n thread in traces? n doe=y|n dump on exit? y msa=y|n Solaris micro state accounting n force=y|n force output to <file> y verbose=y|n print messages about dumps y
// Java program to illustrate Callable // to return a random number import java.util.Random; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; class CallableExample implements Callable { public Object call() throws Exception { // Create random number generator Random generator = new Random(); Integer randomNumber = generator.nextInt(5); // To simulate a heavy computation, // we delay the thread for some random time Thread.sleep(randomNumber * 1000); return randomNumber; } }
/** * 使用Executors.newFixedThreadPool创建线程池 * @throws InterruptedException * @throws ExecutionException */ private static void test1() throws InterruptedException, ExecutionException { System.out.println("----程序开始运行----"); Date date1 = new Date(); int taskSize=5; ExecutorService pool = Executors.newFixedThreadPool(taskSize); List<Future> list = new ArrayList<Future>(); for (int i = 0; i < taskSize; i++) { Callable c = new TestCallable(i); // 执行任务并获取Future对象 Future f = pool.submit(c); list.add(f); } // 关闭线程池 pool.shutdown(); // 获取所有并发任务的运行结果 for (Future f : list) { // 从Future对象上获取任务的返回值,并输出到控制台 System.out.println(">>>" + f.get().toString()); //OPTION + return 抛异常 } Date date2 = new Date(); System.out.println("----程序结束运行----,程序运行时间【" + (date2.getTime() - date1.getTime()) + "毫秒】"); }
/** * 线程直接使用new Thread来创建 * @throws ExecutionException * @throws InterruptedException */ private static void test2() throws ExecutionException, InterruptedException { System.out.println("----程序开始运行----"); Date date1 = new Date(); int taskSize=5; FutureTask[] randomNumberTasks = new FutureTask[5]; List<Future> list = new ArrayList<Future>(); for (int i = 0; i < randomNumberTasks.length; i++) { Callable c = new TestCallable(i); // 执行任务并获取Future对象 randomNumberTasks[i]= new FutureTask(c);
Thread t = new Thread(randomNumberTasks[i]); t.start(); }
// 获取所有并发任务的运行结果 for (Future f : randomNumberTasks) { // 从Future对象上获取任务的返回值,并输 System.out.println(">>>" + f.get().toString()); //OPTION + return 抛异常 } Date date2 = new Date(); System.out.println("----程序结束运行----,程序运行时间【" + (date2.getTime() - date1.getTime()) + "毫秒】");
}
/** * call方法的实现,主要用于执行线程的具体实现,并返回结果 * @return * @throws Exception */ @Override public Object call() throws Exception { System.out.println(">>>" + taskNum + "任务启动"); Date dateTmp1 = new Date(); Thread.sleep(1000); Date dateTmp2 = new Date(); long time = dateTmp2.getTime() - dateTmp1.getTime(); System.out.println(">>>" + taskNum + "任务终止"); return taskNum + "任务返回运行结果,当前任务时间【" + time + "毫秒】"; } }
// Java program to illustrate Callable and FutureTask // for random number generation import java.util.Random; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; class CallableExample implements Callable { public Object call() throws Exception { Random generator = new Random(); Integer randomNumber = generator.nextInt(5); Thread.sleep(randomNumber * 1000); return randomNumber; } } public class CallableFutureTest { public static void main(String[] args) throws Exception { // FutureTask is a concrete class that // implements both Runnable and Future FutureTask[] randomNumberTasks = new FutureTask[5]; for (int i = 0; i < 5; i++) { Callable callable = new CallableExample(); // Create the FutureTask with Callable randomNumberTasks[i] = new FutureTask(callable); // As it implements Runnable, create Thread // with FutureTask Thread t = new Thread(randomNumberTasks[i]); t.start(); } for (int i = 0; i < 5; i++) { // As it implements Future, we can call get() System.out.println(randomNumberTasks[i].get()); // This method blocks till the result is obtained // The get method can throw checked exceptions // like when it is interrupted. This is the reason // for adding the throws clause to main } } }
// Java program to illustrate Runnable // for random number generation import java.util.Random; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; class RunnableExample implements Runnable { // Shared object to store result private Object result = null; public void run() { Random generator = new Random(); Integer randomNumber = generator.nextInt(5); // As run cannot throw any Exception try { Thread.sleep(randomNumber * 1000); } catch (InterruptedException e) { e.printStackTrace(); } // Store the return value in result when done result = randomNumber; // Wake up threads blocked on the get() method synchronized(this) { notifyAll(); } } public synchronized Object get() throws InterruptedException { while (result == null) wait(); return result; } } // Code is almost same as the previous example with a // few changes made to use Runnable instead of Callable public class RunnableTest { public static void main(String[] args) throws Exception { RunnableExample[] randomNumberTasks = new RunnableExample[5]; for (int i = 0; i < 5; i++) { randomNumberTasks[i] = new RunnableExample(); Thread t = new Thread(randomNumberTasks[i]); t.start(); } for (int i = 0; i < 5; i++) System.out.println(randomNumberTasks[i].get()); } }
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
for (int i = 0; i < a1.length; i++) { if (a1[i] != a2[i]) { return false; } }
return true; }
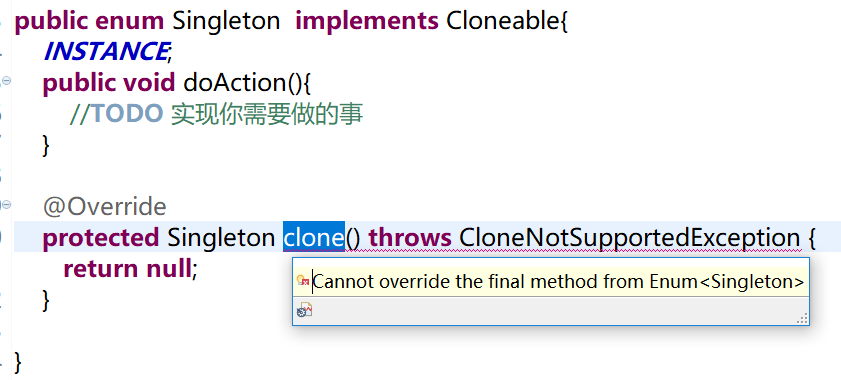
普通类在 arrayContentsEq() 中所有的 if 和 for 都通不过,最后直接返回 true;而枚举类则会因为 a1.length != a2.length(注:a2.length的之为2)条件成立而返回 false。于是普通类接着执行 return getReflectionFactory().copyConstructor(constructor); 而枚举类则直接抛出异常 throw new NoSuchMethodException(getName() + ".<init>" + argumentTypesToString(parameterTypes)); 具体错误信息如下:
Exception in thread “main” java.lang.NoSuchMethodException: designPatterns.singleton.useenum.Singleton.() at java.lang.Class.getConstructor0(Class.java:3082) at java.lang.Class.getDeclaredConstructor(Class.java:2178) at designPatterns.singleton.useenum.DestroySingleton.main(DestroySingleton.java:18)
public class CreateClassBySerialized { @SuppressWarnings("unchecked") public static <T extends Serializable> T createClassBySerialized(T t) throws IOException, ClassNotFoundException{ ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bos); oos.writeObject(t); ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bis); T object = (T) ois.readObject(); if (ois != null) ois.close(); if (bis != null) bis.close(); if (oos != null) oos.close(); if (bos != null) bos.close(); return object; } }
public class DestroySingleton { public static void main(String[] args) throws Exception { //通过序列化,反序列化获取 Singleton serialize = CreateClassBySerialized.createClassBySerialized(Singleton.getInstance()); System.out.println("serialize的hashCode:"+serialize.hashCode()); } }
switch (tc) { case TC_NULL: return readNull(); case TC_REFERENCE: return readHandle(unshared); case TC_CLASS: return readClass(unshared); case TC_CLASSDESC: case TC_PROXYCLASSDESC: return readClassDesc(unshared); case TC_STRING: case TC_LONGSTRING: return checkResolve(readString(unshared)); case TC_ARRAY: return checkResolve(readArray(unshared)); case TC_ENUM: return checkResolve(readEnum(unshared)); case TC_OBJECT: return checkResolve(readOrdinaryObject(unshared)); case TC_EXCEPTION: IOException ex = readFatalException(); throw new WriteAbortedException("writing aborted", ex); case TC_BLOCKDATA: case TC_BLOCKDATALONG: if (oldMode) { bin.setBlockDataMode(true); bin.peek(); // force header read throw new OptionalDataException(bin.currentBlockRemaining()); } else { throw new StreamCorruptedException("unexpected block data"); } case TC_ENDBLOCKDATA: if (oldMode) { throw new OptionalDataException(true); } else { throw new StreamCorruptedException("unexpected end of block data"); } default: throw new StreamCorruptedException(String.format("invalid type code: %02X", tc)); }
public static <T extends Enum<T>> T valueOf(Class<T> enumType,String name) { T result = enumType.enumConstantDirectory().get(name); if (result != null) return result; if (name == null) throw new NullPointerException("Name is null"); throw new IllegalArgumentException( "No enum constant " + enumType.getCanonicalName() + "." + name); }
Map<String, T> enumConstantDirectory() { if (enumConstantDirectory == null) { T[] universe = getEnumConstantsShared(); if (universe == null) throw new IllegalArgumentException( getName() + " is not an enum type"); Map<String, T> m = new HashMap<>(2 * universe.length); for (T constant : universe) m.put(((Enum<?>)constant).name(), constant); enumConstantDirectory = m; } return enumConstantDirectory; }
//getEnumConstantsShared()就是获取到的一个个枚举对象 T[] getEnumConstantsShared() { if (enumConstants == null) { if (!isEnum()) return null; try { final Method values = getMethod("values"); java.security.AccessController.doPrivileged( new java.security.PrivilegedAction<Void>() { public Void run() { values.setAccessible(true); return null; } }); @SuppressWarnings("unchecked") T[] temporaryConstants = (T[])values.invoke(null); enumConstants = temporaryConstants; } // These can happen when users concoct enum-like classes // that don't comply with the enum spec. catch (InvocationTargetException | NoSuchMethodException | IllegalAccessException ex) { return null; } } return enumConstants; }
public class DestroySingleton { public static void main(String[] args) throws Exception { //通过getInstance()获取 Singleton singleton = Singleton.getInstance(); System.out.println("singleton的hashCode:"+singleton.hashCode()); //通过克隆获取 Singleton clob = (Singleton) Singleton.getInstance().clone(); System.out.println("clob的hashCode:"+clob.hashCode()); //通过序列化,反序列化获取 ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bos); oos.writeObject(Singleton.getInstance()); ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bis); Singleton serialize = (Singleton) ois.readObject(); if (ois != null) ois.close(); if (bis != null) bis.close(); if (oos != null) oos.close(); if (bos != null) bos.close(); System.out.println("serialize的hashCode:"+serialize.hashCode()); //通过反射获取 Constructor<Singleton> constructor = Singleton.class.getDeclaredConstructor(); constructor.setAccessible(true); Singleton reflex = constructor.newInstance(); System.out.println("reflex的hashCode:"+reflex.hashCode()); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12
singleton的hashCode:366712642 clob的hashCode:366712642 serialize的hashCode:366712642 Exception in thread "main" java.lang.reflect.InvocationTargetException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at designPatterns.singleton.doublecheck.DestroySingleton.main(DestroySingleton.java:33) Caused by: java.lang.RuntimeException: 已然被实例化一次,不能在实例化 at designPatterns.singleton.doublecheck.Singleton.<init>(Singleton.java:16) ... 5 more
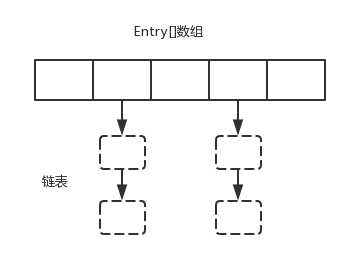
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构 int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } }
构造函数
其他都是在此基础上的扩展,主要就是设置初始容量和负载因子,这 2 个参数前面介绍过了哈。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
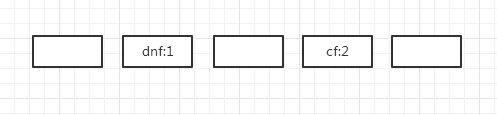
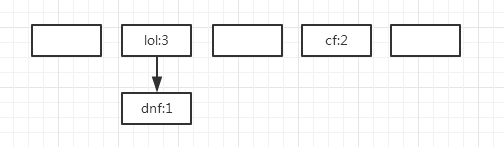
void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue(); }
从 table[0] 初获取 key 为 null 的值
1 2 3 4 5 6 7 8 9 10
private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
key 不为 null 时
1 2 3 4 5 6 7 8 9 10 11 12 13 14
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; }
int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }