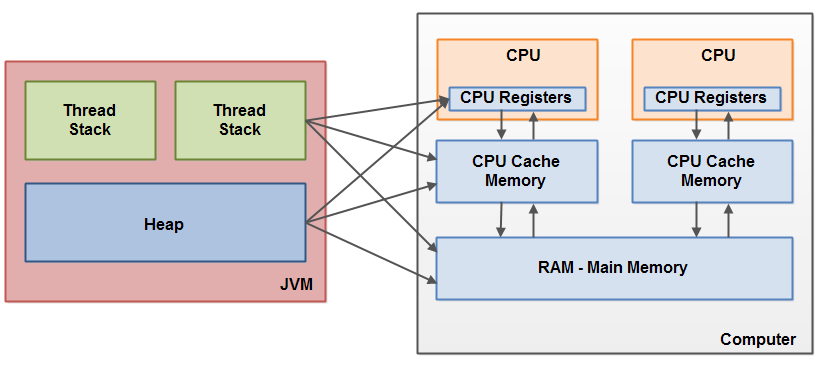
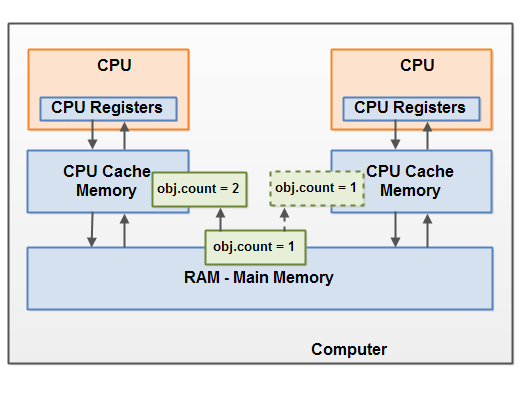
相比Java中的锁(Locks in Java)里Lock实现,读写锁更复杂一些。假设你的程序中涉及到对一些共享资源的读和写操作,且写操作没有读操作那么频繁。在没有写操作的时候,两个线程同时读一个资源没有任何问题,所以应该允许多个线程能在同时读取共享资源。但是如果有一个线程想去写这些共享资源,就不应该再有其它线程对该资源进行读或写(译者注:也就是说:读-读能共存,读-写不能共存,写-写不能共存)。这就需要一个读/写锁来解决这个问题。
public synchronized void unlockRead(){ Thread callingThread = Thread.currentThread(); if(!isReader(callingThread)){ throw new IllegalMonitorStateException( "Calling Thread does not" + " hold a read lock on this ReadWriteLock"); } int accessCount = getReadAccessCount(callingThread);
public synchronized void unlockWrite() throws InterruptedException{ if(!isWriter(Thread.currentThread()){ throw new IllegalMonitorStateException( "Calling Thread does not" + " hold the write lock on this ReadWriteLock"); } writeAccesses--; if(writeAccesses == 0){ writingThread = null; } notifyAll(); }
//Fair Lock implementation with nested monitor lockout problem public class FairLock { private boolean isLocked = false; private Thread lockingThread = null; private List waitingThreads = new ArrayList();
public void lock() throws InterruptedException{ QueueObject queueObject = new QueueObject();
//Fair Lock implementation with slipped conditions problem public class FairLock { private boolean isLocked = false; private Thread lockingThread = null; private List waitingThreads = new ArrayList();
public void lock() throws InterruptedException{ QueueObject queueObject = new QueueObject();
//lock implementation with nested monitor lockout problem public class Lock{ protected MonitorObject monitorObject = new MonitorObject(); protected boolean isLocked = false;
//Fair Lock implementation with nested monitor lockout problem public class FairLock { private boolean isLocked = false; private Thread lockingThread = null; private List waitingThreads = new ArrayList();
public void lock() throws InterruptedException{ QueueObject queueObject = new QueueObject();
Lock lock = new Lock(); public void doSynchronized() throws InterruptedException{ this.lock.lock(); //critical section, do a lot of work which takes a long time this.lock.unlock(); } }
public synchronized void unlock(){ if(this.lockingThread != Thread.currentThread()){ throw new IllegalMonitorStateException("Calling thread has not locked this lock"); } isLocked = false; lockingThread = null;
Transaction 1, request 1, locks record 1 for update Transaction 2, request 1, locks record 2 for update Transaction 1, request 2, tries to lock record 2 for update. Transaction 2, request 2, tries to lock record 1 for update.