python 中 is 和 == 的区别
在 python 中,is 检查两个对象是否是同一个对象,而 == 检查他们是否相等。
Python 中的对象包含三要素:id、type、value。
其中 id 用来唯一标识一个对象,type 标识对象的类型,value 是对象的值。
- is 判断的是 a 对象是否就是 b 对象,是通过 id 来判断的。
- == 判断的是 a 对象的值是否和 b 对象的值相等,是通过 value 来判断的。
类似__xx,以双下划线开头的实例变量名,就变成了一个私有变量(private),只有内部可以访问,外部不能访问;双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量
类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如__author__、__name__就是特殊变量,hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名
有些时候,你会看到以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”
特殊变量
__doc__: 定义文档字符串__dict__: 类的属性列表__class____slots__: 对类的实例可以动态的绑定属性和方法__init__: 创建实例的时候,可以调用__init__方法做一些初始化的工作。与普通的实例方法类似,如果子类不重写__init__,实例化子类时,会自动调用父类的__init__;如果子类重写了__init__,实例化子类时,则只会调用子类的__init__,此时如果想使用父类的__init__,可以使用super函数__new__: __init__是实例创建之后调用的第一个方法,而__new__更像构造函数,它在__init__之前被调用。另外,__new__方法是一个静态方法,第一参数是cls,__new__方法必须返回创建出来的实例。__del__: 类似析构函数。【析构函数(destructor) 与构造函数相反,当对象结束其生命周期,如对象所在的函数已调用完毕时,系统自动执行析构函数】__enter__: 这个方法是用于支持with语句的上下文管理器。__exit__: 这个方法是用于支持with语句的上下文管理器。__iter__: 如果一个类想被用于for … in循环,类似list或tuple那样,就必须实现一个__iter__()方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的next()方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环。__call__: 实例可以像函数一样调用__str__: 返回用户看到的字符串__repr__: 返回开发者看到的字符串(用于调试)1 | # test.py |
__getitem__: 支持下标(或切片)操作的函数__setitem__: 支持下标(或切片)操作的函数__delitem__: 支持下标(或切片)操作的函数1 | class Fib(object): |
__getattr__: 支持点操作(即 “对象.属性” 访问方式)。当访问不存在的属性时,才会使用__getattr__方法__getattribute__: 支持点操作(即 “对象.属性” 访问方式)。当每次调用属性时,python会无条件进入__getattribute__中,不论属性存在与否,这就是与__getattr__的区别__setattr__: 支持点操作(即 “对象.属性” 访问方式)__delattr__: 支持点操作(即 “对象.属性” 访问方式)转自:http://blog.jobbole.com/92290/
在校期间大家都写过不少程序,比如写个hello world服务类,然后本地调用下,如下所示。这些程序的特点是服务消费方和服务提供方是本地调用关系。
而一旦踏入公司尤其是大型互联网公司就会发现,公司的系统都由成千上万大大小小的服务组成,各服务部署在不同的机器上,由不同的团队负责。这时就会遇到两个问题:1)要搭建一个新服务,免不了需要依赖他人的服务,而现在他人的服务都在远端,怎么调用?2)其它团队要使用我们的服务,我们的服务该怎么发布以便他人调用?下文我们将对这两个问题展开探讨。
1 | public interface HelloWorldService { |
1 | public class HelloWorldServiceImpl implements HelloWorldService { |
1 | public class Test { |
由于各服务部署在不同机器,服务间的调用免不了网络通信过程,服务消费方每调用一个服务都要写一坨网络通信相关的代码,不仅复杂而且极易出错。
如果有一种方式能让我们像调用本地服务一样调用远程服务,而让调用者对网络通信这些细节透明,那么将大大提高生产力,比如服务消费方在执行helloWorldService.sayHello(“test”)时,实质上调用的是远端的服务。这种方式其实就是RPC(Remote Procedure Call Protocol),在各大互联网公司中被广泛使用,如阿里巴巴的hsf、dubbo(开源)、Facebook的thrift(开源)、Google grpc(开源)、Twitter的finagle等。
要让网络通信细节对使用者透明,我们自然需要对通信细节进行封装,我们先看下一个RPC调用的流程:
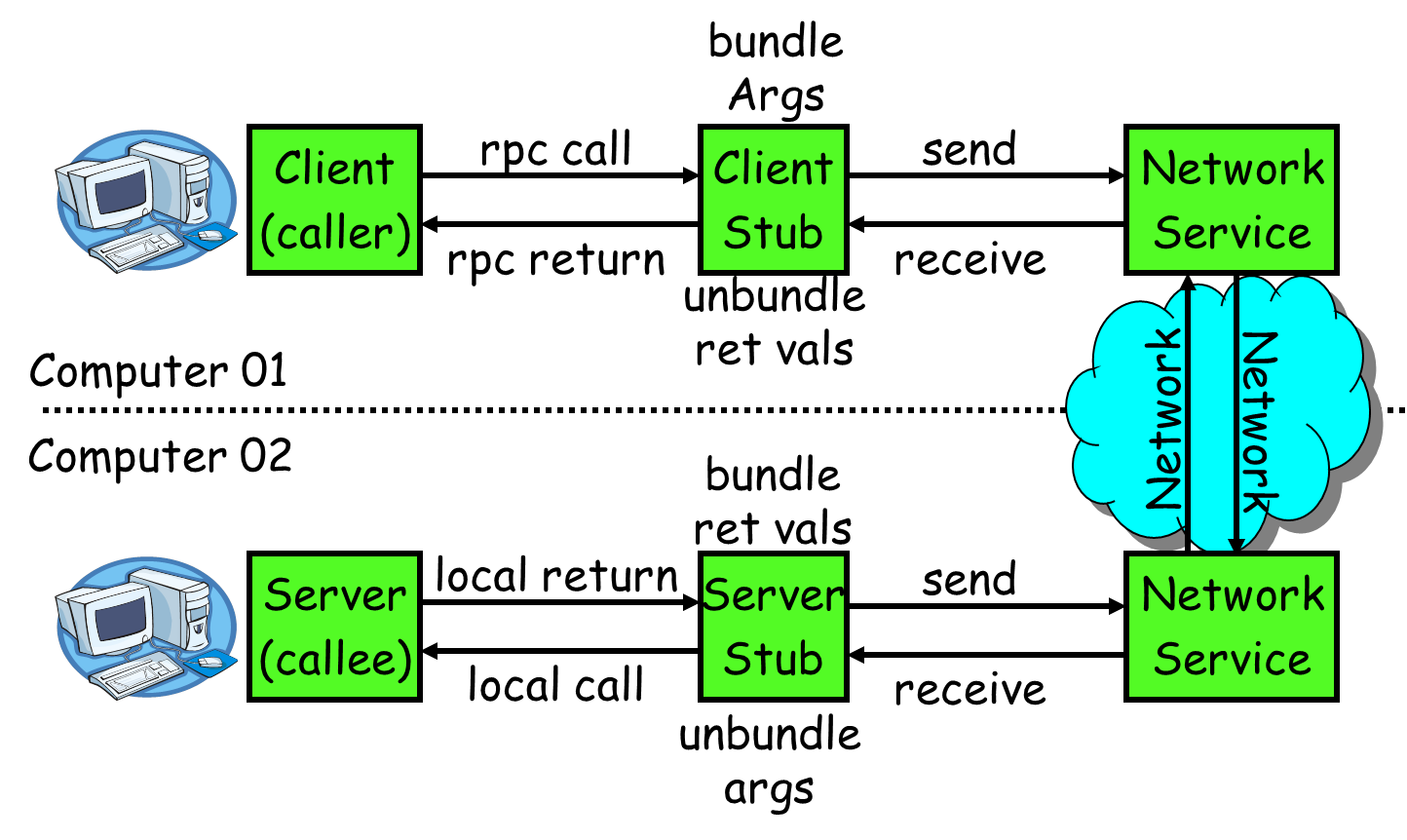
RPC的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
怎么封装通信细节才能让用户像以本地调用方式调用远程服务呢?对java来说就是使用代理!
java代理有两种方式:
下面简单介绍下动态代理怎么实现我们的需求。我们需要实现RPCProxyClient代理类,代理类的invoke方法中封装了与远端服务通信的细节,消费方首先从RPCProxyClient获得服务提供方的接口,当执行helloWorldService.sayHello(“test”)方法时就会调用invoke方法。
1 | public class RPCProxyClient implements java.lang.reflect.InvocationHandler{ |
1 | public class Test { |
上节讲了invoke里需要封装通信细节,而通信的第一步就是要确定客户端和服务端相互通信的消息结构。客户端的请求消息结构一般需要包括以下内容:
1)接口名称
在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了;
2)方法名
一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;
3)参数类型&参数值
参数类型有很多,比如有bool、int、long、double、string、map、list,甚至如struct(class);
以及相应的参数值;
4)超时时间
5)requestID,标识唯一请求id,在下面一节会详细描述requestID的用处。
同理服务端返回的消息结构一般包括以下内容。
1)返回值
2)状态code
3)requestID
一旦确定了消息的数据结构后,下一步就是要考虑序列化与反序列化了。
什么是序列化?序列化就是将数据结构或对象转换成二进制串的过程,也就是编码的过程。
什么是反序列化?将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
为什么需要序列化?转换为二进制串后才好进行网络传输嘛!为什么需要反序列化?将二进制转换为对象才好进行后续处理!
现如今序列化的方案越来越多,每种序列化方案都有优点和缺点,它们在设计之初有自己独特的应用场景,那到底选择哪种呢?从RPC的角度上看,主要看三点:
目前国内各大互联网公司广泛使用hessian、protobuf、thrift、avro等成熟的序列化解决方案来搭建RPC框架,这些都是久经考验的解决方案。
消息数据结构被序列化为二进制串后,下一步就要进行网络通信了。目前有两种IO通信模型:
如何实现RPC的IO通信框架?
如果使用netty的话,一般会用channel.writeAndFlush()方法来发送消息二进制串,这个方法调用后对于整个远程调用(从发出请求到接收到结果)来说是一个异步的,即对于当前线程来说,将请求发送出来后,线程就可以往后执行了,至于服务端的结果,是服务端处理完成后,再以消息的形式发送给客户端的。于是这里出现以下两个问题:
怎么让当前线程“暂停”,等结果回来后,再向后执行?
如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是随机的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
如下图所示,线程A和线程B同时向client socket发送请求requestA和requestB,socket先后将requestB和requestA发送至server,而server可能将responseA先返回,尽管requestA请求到达时间更晚。我们需要一种机制保证responseA丢给ThreadA,responseB丢给ThreadB。

怎么解决呢?
client线程每次通过socket调用一次远程接口前,生成一个唯一的ID,即requestID(requestID必需保证在一个Socket连接里面是唯一的),一般常常使用AtomicLong从0开始累计数字生成唯一ID;
将处理结果的回调对象callback,存放到全局ConcurrentHashMap里面put(requestID, callback);
当线程调用channel.writeAndFlush()发送消息后,紧接着执行callback的get()方法试图获取远程返回的结果。在get()内部,则使用synchronized获取回调对象callback的锁,再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
服务端接收到请求并处理后,将response结果(此结果中包含了前面的requestID)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到requestID,再从前面的ConcurrentHashMap里面get(requestID),从而找到callback对象,再用synchronized获取callback上的锁,将方法调用结果设置到callback对象里,再调用callback.notifyAll()唤醒前面处于等待状态的线程。
1 | public Object get() { |
1 | private void setDone(Response res) { |
如何让别人使用我们的服务呢?有同学说很简单嘛,告诉使用者服务的IP以及端口就可以了啊。确实是这样,这里问题的关键在于是自动告知还是人肉告知。
人肉告知的方式:如果你发现你的服务一台机器不够,要再添加一台,这个时候就要告诉调用者我现在有两个ip了,你们要轮询调用来实现负载均衡;调用者咬咬牙改了,结果某天一台机器挂了,调用者发现服务有一半不可用,他又只能手动修改代码来删除挂掉那台机器的ip。现实生产环境当然不会使用人肉方式。
有没有一种方法能实现自动告知,即机器的增添、剔除对调用方透明,调用者不再需要写死服务提供方地址?当然可以,现如今zookeeper被广泛用于实现服务自动注册与发现功能!
简单来讲,zookeeper可以充当一个服务注册表(Service Registry),让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(ip+端口)去访问具体的服务提供者。如下图所示:
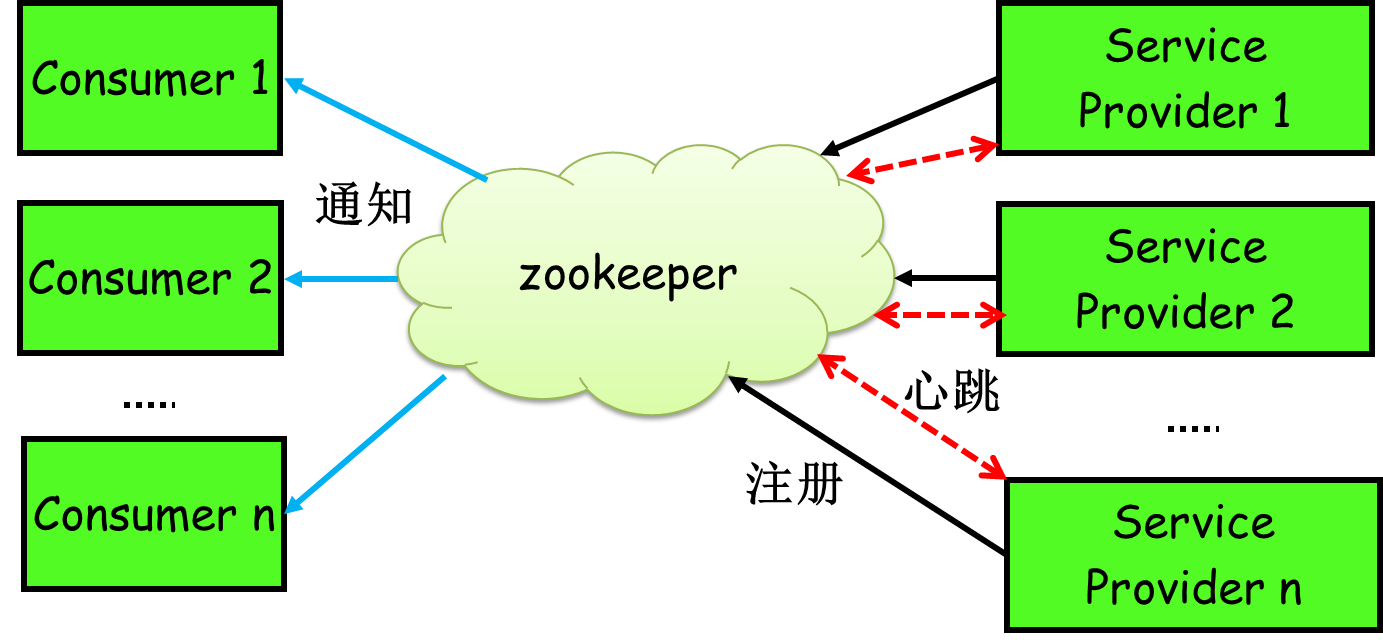
具体来说,zookeeper就是个分布式文件系统,每当一个服务提供者部署后都要将自己的服务注册到zookeeper的某一路径上: /{service}/{version}/{ip:port}, 比如我们的HelloWorldService部署到两台机器,那么zookeeper上就会创建两条目录:分别为/HelloWorldService/1.0.0/100.19.20.01:16888 /HelloWorldService/1.0.0/100.19.20.02:16888。
zookeeper提供了“心跳检测”功能,它会定时向各个服务提供者发送一个请求(实际上建立的是一个 socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除,比如100.19.20.02这台机器如果宕机了,那么zookeeper上的路径就会只剩/HelloWorldService/1.0.0/100.19.20.01:16888。
服务消费者会去监听相应路径(/HelloWorldService/1.0.0),一旦路径上的数据有任务变化(增加或减少),zookeeper都会通知服务消费方服务提供者地址列表已经发生改变,从而进行更新。
更为重要的是zookeeper 与生俱来的容错容灾能力(比如leader选举),可以确保服务注册表的高可用性。
RPC几乎是每一个从学校进入互联网公司的同学都要首先学习的框架,之前面试过一个在大型互联网公司工作过两年的同学,对RPC还是停留在使用层面,这是不应该的。本文也仅是对RPC的一个比较粗糙的描述,希望对大家有所帮助,错误之处也请指出修正。
https://github.com/alibaba/dubbo
http://thrift.apache.org/?cm_mc_uid=87762817217214314008006&cm_mc_sid_50200000=1444181090
网站流量是指网站的访问量,用来描述访问网站的用户数量以及用户所浏览的网页数量等指标,常用的统计指标包括网站的独立用户数量、总用户数量(含重复访问者)、网页浏览数量、每个用户的页面浏览数量、用户在网站的平均停留时间等。
网站访问量的常用衡量标准:独立访客(UV) 和 综合浏览量(PV),一般以日为单位来衡量和计算。
独立访客(UV):指一定时间范围内相同访客多次访问网站,只计算为1个独立访客。
综合浏览量(PV):指一定时间范围内页面浏览量或点击量,用户每次刷新即被计算一次。
计算带宽大小需要关注两个指标:峰值流量和页面的平均大小。
举个例子:
假设网站的平均日PV:10w 的访问量,页面平均大小0.4 M 。
网站带宽 = 10w / (24 60 * 60) 0.4M * 8 =3.7 Mbps
具体的计算公式是:网站带宽= PV / 统计时间(换算到S)平均页面大小(单位KB) 8
在实际的网站运行过程中,我们的网站必须要在峰值流量时保持正常的访问,假设,峰值流量是平均流量的5倍,按照这个计算,实际需要的带宽大约在 3.7 Mbps * 5=18.5 Mbps 。
PS:
- 字节的单位是Byte,而带宽的单位是bit,1Byte=8bit,所以转换为带宽的时候,要乘以 8。
- 在实际运行中,由于缓存、CDN、白天夜里访问量不同等原因,这个是绝对情况下的算法。
具体的计算公式是:并发连接数 = PV / 统计时间 * 页面衍生连接次数 * http响应时间 * 因数 / web服务器数量;
解释:
页面衍生连接次数: 一个页面请求,会有好几次http连接,如外部的css, js,图片等,这个根据实际情况而定。
http响应时间: 平均一个http请求的响应时间,可以使用1秒或更少。
因数: 峰值流量和平均流量的倍数,一般使用5 ,最好根据实际情况计算后得出。
例子:
10PV的并发连接数: (100000PV / 86400秒 * 50个派生连接数 * 1秒内响应 * 5倍峰值) / 1台Web服务器 = 289 并发连接数
所以,如果我们能够测试出单机的并发连接数,和 日pv 数,那么我们同样也能估算出需要web的服务器数量。
还有一套通过单机 QPS计算 pv 和 需要的web服务器数量的方法,目前一些公司采用这种计算方法,但是其实计算的原理都是差不多的。
QPS = req/sec = 请求数/秒
【QPS计算PV和机器的方式】
QPS统计方式 [一般使用 http_load 进行统计]
QPS = 总请求数 / ( 进程总数 * 请求时间 )
QPS: 单个进程每秒请求服务器的成功次数
单台服务器每天PV计算
公式1:每天总PV = QPS * 3600 * 6
公式2:每天总PV = QPS * 3600 * 8
服务器计算
服务器数量 = ( 每天总PV / 单台服务器每天总PV )
【峰值QPS和机器计算公式】
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
例子:每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 *0.2 ) = 139 (QPS)
例子:如果一台机器的QPS是58,需要几台机器来支持?
139 / 58 = 3
使用limit_req_zone和limit_req指令配合使用来达到限制。一旦并发连接超过指定数量,就会返回503错误。
http{
...
#定义一个名为allips的limit_req_zone用来存储session,大小是10M内存,
#以$binary_remote_addr 为key,限制平均每秒的请求为20个,
#1M能存储16000个状态,rete的值必须为整数,
#如果限制两秒钟一个请求,可以设置成30r/m
limit_req_zone $binary_remote_addr zone=allips:10m rate=20r/s;
...
server{
...
location {
...
#限制每ip每秒不超过20个请求,漏桶数burst为5
#brust的意思就是,如果第1秒、2,3,4秒请求为19个,
#第5秒的请求为25个是被允许的。
#但是如果你第1秒就25个请求,第2秒超过20的请求返回503错误。
#nodelay,如果不设置该选项,严格使用平均速率限制请求数,
#第1秒25个请求时,5个请求放到第2秒执行,
#设置nodelay,25个请求将在第1秒执行。
limit_req zone=allips burst=5 nodelay;
...
}
...
}
...
}
```
语法规则: `location [=||*|^~] /uri/ { … }``
顺序 no优先级:
(location =) > (location 完整路径) > (location ^~ 路径) > (location ,* 正则顺序) > (location 部分起始路径) > (/)
例子,有如下匹配规则:
1 | location = / { |
所以实际使用中,个人觉得至少有三个匹配规则定义,如下:
直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理,官网如是说。
这里是直接转发给后端应用服务器了,也可以是一个静态首页
第一个必选规则
1 | location = / { |
第二个必选规则是处理静态文件请求,这是nginx作为http服务器的强项
有两种配置模式,目录匹配或后缀匹配,任选其一或搭配使用
1 | location ^~ /static/ { |
第三个规则就是通用规则,用来转发动态请求到后端应用服务器
非静态文件请求就默认是动态请求,自己根据实际把握
毕竟目前的一些框架的流行,带.php,.jsp后缀的情况很少了
1 | location / { |
防盗链
1 | location ~* \.(gif|jpg|png|swf|flv)$ { |
根据文件类型设置过期时间
1 | location ~* \.(js|css|jpg|jpeg|gif|png|swf)$ { |
禁止访问某个目录
1 | location ^~ /path { |
rewrite功能就是,使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。rewrite只能放在server{},location{},if{}中,并且只能对域名后边的除去传递的参数外的字符串起作用,例如 http://seanlook.com/a/we/index.php?id=1&u=str 只对/a/we/index.php重写。语法rewrite regex replacement [flag];
如果相对域名或参数字符串起作用,可以使用全局变量匹配,也可以使用proxy_pass反向代理。
表明看rewrite和location功能有点像,都能实现跳转,主要区别在于rewrite是在同一域名内更改获取资源的路径,而location是对一类路径做控制访问或反向代理,可以proxy_pass到其他机器。很多情况下rewrite也会写在location里,它们的执行顺序是:
执行server块的rewrite指令
flag标志位
因为301和302不能简单的只返回状态码,还必须有重定向的URL,这就是return指令无法返回301,302的原因了。这里 last 和 break 区别有点难以理解:
1 | http { |
对形如/images/ef/uh7b3/test.png的请求,重写到/data?file=test.png,于是匹配到location /data,先看/data/images/test.png文件存不存在,如果存在则正常响应,如果不存在则重写tryfiles到新的image404 location,直接返回404状态码。
1 | rewrite ^/images/(.*)_(\d+)x(\d+)\.(png|jpg|gif)$ /resizer/$1.$4?width=$2&height=$3? last; |
对形如/images/bla_500x400.jpg的文件请求,重写到/resizer/bla.jpg?width=500&height=400地址,并会继续尝试匹配location。