语句样式:MySQL 中,可用如下方法: SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M。
适应场景:适用于数据量多的情况(元组数上万)。最好 ORDER BY 后的列对象是主键或唯一索引,使得 ORDER BY 操作能利用索引被消除但结果集是稳定的(稳定的含义,参见方法 1)。
原因:索引扫描,速度会很快。但 MySQL 的排序操作,只有 ASC 没有 DESC(DESC是假的,未来会做真正的 DESC,期待)。
方法4:基于索引使用 prepare(第一个问号表示 pageNum,第二个?表示每页元组数)
语句样式:MySQL 中,可用如下方法:
1 2
复制代码代码如下: PREPARE stmt_name FROM SELECT * FROM 表名称 WHERE id_pk > (?* ?) ORDER BY id_pk ASC LIMIT M。
适应场景:大数据量。
原因:索引扫描,速度会很快。prepare 语句又比一般的查询语句快一点。
方法5:利用 MySQL 支持 ORDER 操作可以利用索引快速定位部分元组,避免全表扫描
比如:读第 1000 到 1019 行元组(pk 是主键/唯一键)。
1 2
复制代码代码如下: SELECT * FROM your_table WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20。
方法6:利用”子查询/连接+索引”快速定位元组的位置,然后再读取元组。道理同方法 5
如(id 是主键/唯一键,蓝色字体时变量):
1 2 3 4 5 6 7
利用子查询示例: 复制代码代码如下: SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize ORDER BY id desc LIMIT $pagesize
利用连接示例: 复制代码代码如下: SELECT * FROM your_table AS t1 JOIN(SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize AS t2 WHERE t1.id <= t2.id ORDER BY t1.id desc LIMIT $pagesize;
方法7:存储过程类(最好融合上述方法 5/6)
语句样式:不再给出
适应场景:大数据量。作者推荐的方法
原因:把操作封装在服务器,相对更快一些。
方法8:反面方法
网上有人写使用 SQL_CALC_FOUND_ROWS。没有道理,勿模仿 。
基本上,可以推广到所有数据库,道理是一样的。但方法 5 未必能推广到其他数据库,推广的前提是,其他数据库支持 ORDER BY 操作可以利用索引直接完成排序。
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
通过在 pom.xml 中定义 jar 包版本和依赖,能够方便的管理 jar 文件。pom作为项目对象模型。通过xml表示maven项目,使用pom.xml来实现。主要描述了项目:包括配置文件;开发者需要遵循的规则,缺陷管理系统,组织和licenses,项目的url,项目的依赖性,以及其他所有的项目相关因素。
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
They are essentially equivalent to each other (in fact this is how some databases implement DISTINCT under the hood).
If one of them is faster, it’s going to be DISTINCT. This is because, although the two are the same, a query optimizer would have to catch the fact that your GROUP BY is not taking advantage of any group members, just their keys. DISTINCT makes this explicit, so you can get away with a slightly dumber optimizer.
When in doubt, test!
If you have an index on profession, these two are synonyms.
If you don’t, then use DISTINCT.
GROUP BY in MySQL sorts results. You can even do:
1
SELECT u.profession FROM users u GROUP BY u.profession DESC
and get your professions sorted in DESC order.
DISTINCT creates a temporary table and uses it for storing duplicates. GROUP BY does the same, but sortes the distinct results afterwards.
So
1
SELECT DISTINCT u.profession FROM users u
is faster, if you don’t have an index on profession.
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
假设用户需要对 N 个唯独进行聚合查询操作,普通的 group by 语句需要 N 个查询和 N 次 group by 操作。
而 rollup 的有点是一次可以去的 N 次 group by 的结果,这样可以提高查询效率,同时大大减少网络的传输流量。
(注,此表的表结构和数据与格式化聚合表 formatting 一致)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
CREATE TABLE rollup( orderid int NOT NULL, orderdate date NOT NULL, empid int NOT NULL, custid varchar(10) NOT NULL, qty int NOT NULL, PRIMARY KEY(orderid,orderdate));
INSERT INTO rollup SELECT 1,'2010-01-02',3,'A',10; INSERT INTO rollup SELECT 2,'2010-04-02',2,'B',20; INSERT INTO rollup SELECT 3,'2010-05-02',1,'A',30; INSERT INTO rollup SELECT 4,'2010-07-02',3,'D',40; INSERT INTO rollup SELECT 5,'2011-01-02',4,'A',20; INSERT INTO rollup SELECT 6,'2011-01-02',3,'B',30; INSERT INTO rollup SELECT 7,'2011-01-02',1,'C',40; INSERT INTO rollup SELECT 8,'2009-01-02',2,'A',10; INSERT INTO rollup SELECT 9,'2009-01-02',3,'B',20;
首先做一个简单的一维聚合
1 2 3 4
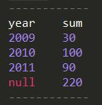
SELECT YEAR(orderdate) year, SUM(qty) sum FROM rollup GROUP BY YEAR(orderdate) WITH ROLLUP;
结果为
和普通的 group by 差别不大,只是多了一个 (null,220),表示对所有的 year 再做一次聚合,即订单数量总和。
对单个唯独进行 rollup 操作只是可以在最后得到聚合的数据,对比 group by 语句并没有非常大的优势。
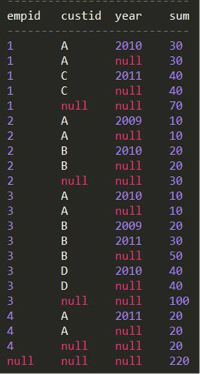
对多个维度进行 rollup 才能体现出 rollup 的优势:
(对 3 列进行层次的维度操作)
1 2 3 4
SELECT empid, custid, YEAR(orderdate) year, SUM(qty) sum FROM rollup GROUP BY empid,custid,YEAR(orderdate) WITH ROLLUP;
SELECT empid, custid, YEAR(orderdate) YEAR, SUM(qty) sum FROM rollup GROUP BY empid, custid, YEAR(orderdate) UNION SELECT empid, custid, NULL, SUM(qty) sum FROM rollup GROUP BY empid, custid UNION SELECT empid, NULL, NULL, SUM(qty) sum FROM rollup GROUP BY empid UNION SELECT NULL, NULL, NULL, SUM(qty) sum FROM rollup
虽然两者得到相同的结果,但是执行计划却不同
rollup 只需要一次表扫描操作就能得到全部结果,因此查询效率在此得到了极大的提升。
P.S.在使用 rollup 需要注意以下几方面
ORDER BY 不能在 rollup 中使用,两者为互斥关键字,如果使用,会抛出以下错误:Error Code:1221. Incorrect usage of CUBE/ROLLUP and ORDER BY
可以使用 LIMIT,但是因为不能使用 order by,所以阅读性下降,故大多数情况下无实际意义。
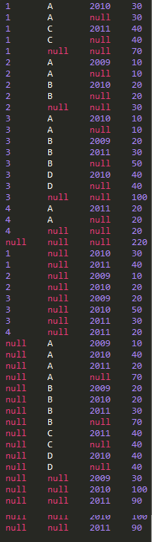
SELECT empid, custid, YEAR(orderdate) year, SUM(qty) sum from rollup GROUP BY empid, custid, YEAR(orderdate) WITH ROLLUP UNION SELECT empid, custid, YEAR(orderdate) year, SUM(qty) sum from rollup GROUP BY empid, YEAR(orderdate), custid WITH ROLLUP UNION SELECT empid, custid, YEAR(orderdate) year, SUM(qty) sum from rollup GROUP BY custid, YEAR(orderdate),empid WITH ROLLUP UNION SELECT empid, custid, YEAR(orderdate) year, SUM(qty) sum from rollup GROUP BY custid, empid, YEAR(orderdate) WITH ROLLUP UNION SELECT empid,custid,YEAR(orderdate) year, SUM(qty) sum from rollup GROUP BY YEAR(orderdate), empid, custid WITH ROLLUP UNION SELECT empid,custid,YEAR(orderdate) year, SUM(qty) sum from rollup GROUP BY YEAR(orderdate), custid, empid WITH ROLLUP;
产生的最终结果为:
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
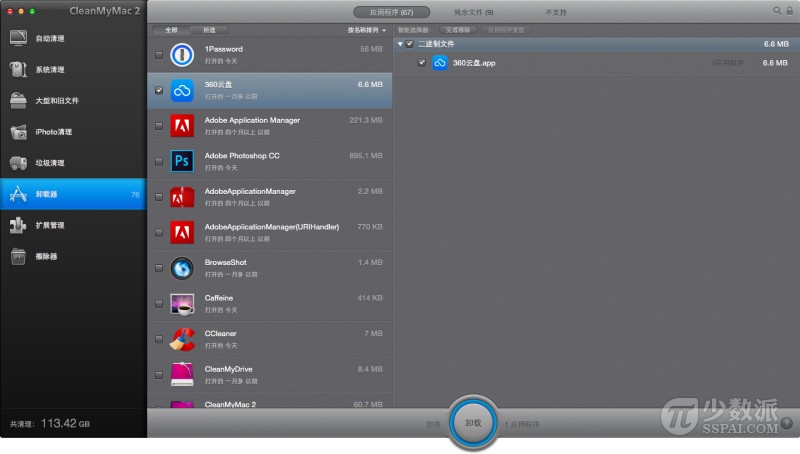
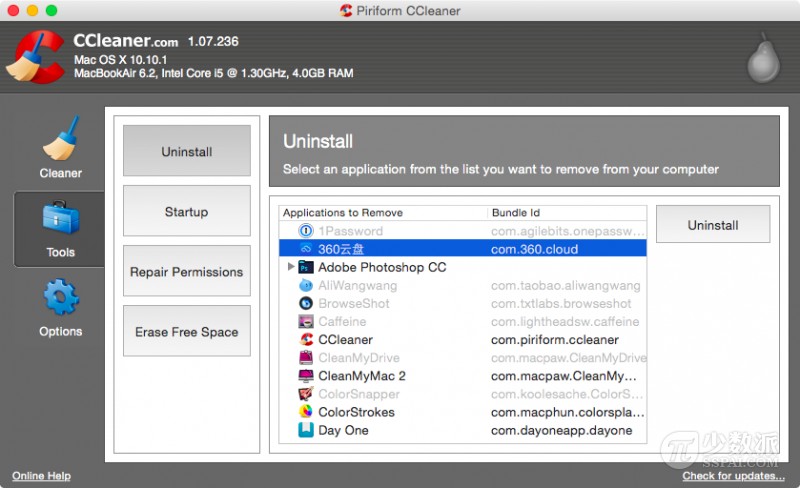
从 Mac 电脑上卸载已经安装的应用程序可能是你知道的操作系统里面最简单的一种了。而如果你是一名新买了 Mac 电脑的用户,那么你可能比较困惑:怎么没有控制面板中的相应板块来卸载它们呢?但是其实你想不到,在 Mac 电脑上卸载应用程序这一点简直简单得要命。本文就来讨论讨论如何卸载 Mac 电脑已经装好的应用程序。
最经典的方法
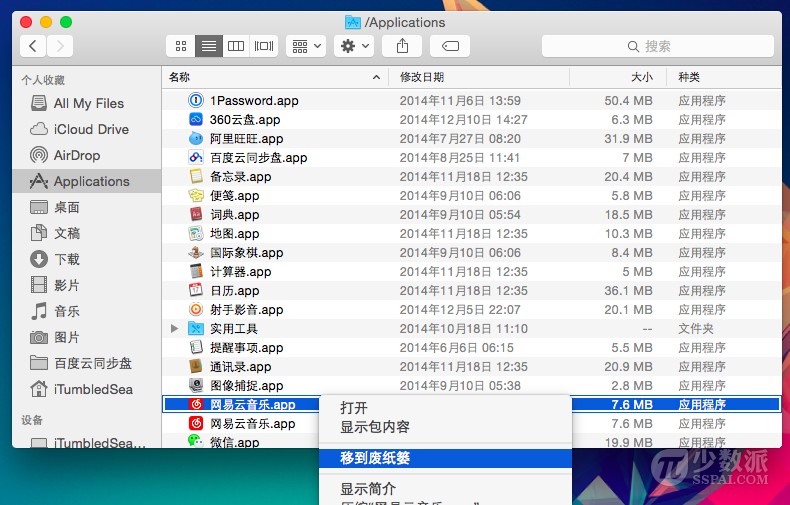
这是 OS X 最经典的方法。你只需找到需要卸载的应用程序,然后拖动应用程序图标到垃圾桶;或右键单击并选择「移到废纸篓」选项;或直接按下 command-delete 快捷键组合。然后在废纸篓图标上单机鼠标右键,选择「清倒废纸篓」选项。
/Applications/Paragon NTFS for Mac OS X /Manual.pdf /Applications/Paragon NTFS for Mac OS X/Register NTFS for Mac OS X.app /Library/Application Support/Paragon NTFS for Mac OS X/NTFS for Mac OS X.app /Library/PreferencePanes/NTFSforMacOSX.prefPane /System/Library/Filesystems/ufsd_NTFS.fs /System/Library/LaunchAgents/com.paragon.NTFS.trial.plist /etc/mach_init_per_user.d/trial_expired_NTFS.plist /sbin/fsck_ufsd_NTFS /sbin/mount_ufsd_NTFS /sbin/newfs_ufsd_NTFS /usr/lib/libUFSDNTFS.dylib /usr/sbin/fsctl_ufsd /Library/Logs/ufsd.log /tmp/ufsd.log /usr/share/.intelligence /Library/Receipts/$PRODUCT.pkg/Archive.bom
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">