exit是用来结束一个程序的执行的,而return只是用来从一个函数中返回。
return 表示从被调函数返回到主调函数继续执行,返回时可附带一个返回值,由return后面的参数指定,当然如果是在主函数main,自然也就结束当前进程了,如果不是,那就是退回上一层调用。
return通常是必要的,因为函数调用的时候计算结果通常是通过返回值带出的。
exit(0)表示正常退出执行程序,如果加其它的数值:1,2,….可以表示由于不同的错误原因而退出。
exit是用来结束一个程序的执行的,而return只是用来从一个函数中返回。
return 表示从被调函数返回到主调函数继续执行,返回时可附带一个返回值,由return后面的参数指定,当然如果是在主函数main,自然也就结束当前进程了,如果不是,那就是退回上一层调用。
return通常是必要的,因为函数调用的时候计算结果通常是通过返回值带出的。
exit(0)表示正常退出执行程序,如果加其它的数值:1,2,….可以表示由于不同的错误原因而退出。
IFNULL(expr1,expr2)如果 expr1 不是 NULL,IFNULL() 返回 expr1,否则它返回 expr2。IFNULL() 返回一个数字或字符串值,取决于它被使用的上下文环境。
IF(expr1,expr2,expr3)如果 expr1 是 TRUE(expr1<>0且expr1<>NULL),那么 IF() 返回 expr2,否则它返回 expr3。IF() 返回一个数字或字符串值,取决于它被使用的上下文。
expr1作为整数值被计算,它意味着如果你正在测试浮点或字符串值,你应该使用一个比较操作来做。
1 | mysql> select IF(0.1,1,0); |
在上面的第一种情况中,IF(0.1)返回 0,因为 0.1 被变换到整数值, 导致测试 IF(0)。这可能不是你期望的。在第二种情况中,比较测试原来的浮点值看它是否是非零,比较的结果被用作一个整数。
CASE value WHEN [compare-value] THEN result [WHEN [compare-value] THEN result ...] [ELSE result] END返回 result,其中 value=compare-value。如果没有匹配的 result 值,那么结果在 ELSE 后的 result 被返回。如果没有 ELSE 部分,那么 NULL 被返回。
1 | mysql> SELECT CASE 1 WHEN 1 THEN "one" WHEN 2 THEN "two" ELSE "more" END; |
CASE WHEN [condition] THEN result [WHEN [condition] THEN result ...] [ELSE result] END如果第一个条件为真,返回 result。如果没有匹配的 result 值,那么结果在 ELSE 后的 result 被返回。如果没有 ELSE 部分,那么 NULL 被返回。
1 | mysql> SELECT CASE WHEN 1>0 THEN "true" ELSE "false" END; |
| :UNIX管道:将一个命令的标准输出作为另一个命令的标准输入。> 是重定向,不仅可以是标准输出strout,还可以是标准错误输出strerr管道与重定向的区别:
ls $(pwd) 和 pwd | ls 效果相同
$()中的命令将在子shell中执行-也就是说,系统将产生一个新的shell实例,计算命令的值,关闭自shell并将结果返回到最初shell中。
如果设置了特殊的环境条件,这些条件可能不会转移到子shell中(例如手动设置的path),那么子shell可能不会继承这些条件。在这种情况下,命令将无效。
除了使用$()结构以外,还可以使用反引号。例如:ls `pwd`
实现与上述完全相同的功能。另一种方法就是使用花括号,例如:ls ${pwd}
两者的不同之处在于花括号中的命令在当前shell中执行,而不需要产生子shell(花括号并不是在所有的Unix版本中都有效)
PS1变量:命令行前的提示信息。例如:[username@time /pwd]$
PATH:决定了shell将到哪些目录中寻找命令或程序
HOME:当前用户主目录
MAIL:是指当前用户的邮件存放目录。
SHELL:是指当前用户用的是哪种Shell。
HISTSIZE:是指保存历史命令记录的条数
LOGNAME:是指当前用户的登录名。
HOSTNAME:是指主机的名称,许多应用程序如果要用到主机名的话,通常是从这个环境变量中来取得的。
LANG/LANGUGE:是和语言相关的环境变量,使用多种语言的用户可以修改此环境变量。
PS1:是基本提示符,对于root用户是#,对于普通用户是$。
PS2:是附属提示符,默认是“>”。PS2一般使用于命令行里较长命令的换行提示信息
PS4:是跟踪开启后的打印方式,默认是“+”
set命令的输出显示在当前shell中定义的所有环境变量的值:来自/etc/profile文件的值、来自个人~/.profile配置文件中的值、用户和其他用户手动定义的所有变量以及程序运行中定义的所有变量。
chown 修改文件和文件夹的用户和用户组属性
要修改文件hh.c的所有者.修改为sakia的这个用户所有
1 | chown sakia hh.c |
这样就把hh.c的用户访问权限应用到sakia作为所有者
将目录 /tmp/sco 这个目录的所有者和组改为sakia和组net
1 | chown -R sakia:net /tmp/sco |
chmod 修改文件和文件夹读写执行属性
把hh.c文件修改为可写可读可执行
1 | chmod 777 hh.c |
要修改某目录下所有的文件属性为可写可读可执行
1 | chmod 777 *.* |
把文件夹名称与后缀名用*来代替就可以了。
同理若是要修改所有htm文件的属性
1 | chmod 777 *.htm |
把目录 /tmp/sco修改为可写可读可执行
1 | chmod 777 /tmp/sco |
要修改某目录下所有的文件夹属性为可写可读可执行
1 | chmod 777 * |
把文件夹名称用*来代替就可以了
要修改/tmp/sco下所有的文件和文件夹及其子文件夹属性为可写可读可执行
1 | chmod -R 777 /tmp/sco |
777就是拥有全权限。根据需要可以自由组合用户和组的权限
Unix中有集中不同类型的文件系统:面向磁盘的、面向网络的、专用的或虚拟的。
在不退出的情况下登陆到另一个用户,有两个命令可以做到这一点:su和sudo。
su(switch user):根用户su其它用户不需要口令;使用su时,继续使用自己的环境变量和配置文件,如果想使用新账户的用户环境,可以在su和帐户名之间加一个破折号(-);之输入su而没有输入用户名,表示登陆到根账户。
sudo(superuser do):是的超级用户或根管理员能够执行由其他用户运行的命令。
转自:http://blog.sina.com.cn/s/blog_6fd335bb0100v1lm.html
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
可能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash 索引仅仅能满足”=”,”IN”和”<=>”查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说,MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree ,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个 Leaf Node 上面出了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息,这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
在 Innodb 存储引擎中,存在两种不同形式的索引,一种是 Cluster 形式的主键索引(Primary Key),另外一种则是和其他存储引擎(如 MyISAM 存储引擎)存放形式基本相同的普通 B-Tree 索引,这种索引在 Innodb 存储引擎中被称为 Secondary Index。下面我们通过图示来针对这两种索引的形式做一个比较。
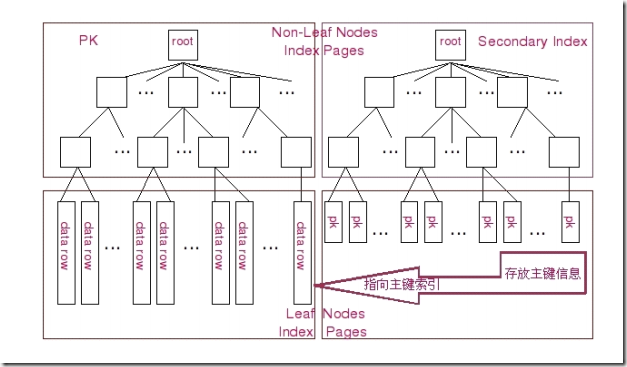
图示中左边为 Clustered 形式存放的 Primary Key ,右侧则为普通的 B-Tree 索引。两种 Root Node 和 Branch Nodes 方面都还是完全一样的。而 Leaf Nodes 就出现差异了。在 Prim中, Leaf Nodes 存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据据以主键值有序的排列。而 Secondary Index 则和其他普通的 B-Tree 索引没有太大的差异,Leaf Nodes 出了存放索引键 的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过 Secondary Index 来访问数据的话, Innodb 首先通过 Secondary Index 的相关信息,通过相应的索引键检索到 Leaf Node 之后,需要再通过 Leaf Node 中存放的主键值再通过主键索引来获取相应的数据行。MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的 Secondary Index 的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在 Leaf Nodes 上面出了存放索引键信息之外,再存放能直接定位到 MyISAM 数据文件中相应的数据行的信息(如 Row Number),但并不会存放主键的键值信息。
using() 用于两张表的 join 查询,要求 using() 指定的列在两个表中均存在,并使用之用于 join 的条件。
示例:
1 | select a.*, b.* from a left join b using(colA); |
等同于:
1 | select a.*, b.* from a left join b on a.colA = b.colA; |
Unix系统上主要有三种类型的用户:根用户(或超级用户)账户、系统账户以及普通用户账户。
root
对特定组建进行操作所需的那类账户。例如,在/etc/passwd文件中可能找到的系统帐户名有adm、alias、apache、backup、bin、bind、daemon、ftp、guest、gdm、gopher、halt、identd、irc、kmem、listen、mail、mysql、named、noaccess、nobody、nobody4、ntp、root、rpc、rpcuser和sys。
/etc/passwd为系统识别已授权的账户。一行保存一个账户的信息。
每个条目的说明:
Login ID(用户名):Encryted Password or x(加密的口令或x):UID(用户ID号):Default GID(默认UID(组UID)):GCOS/Comment(注释):Home Directory(主目录):Login Shell(登陆的shell)
/etc/shadow保存相应账户加密后的口令。大多数Unix系统都有这个文件。一条保存一个账户的密码信息。
每个条目的说明:
beginningunix(用户名):加密后的口令:最近一次修改(自1970年1月1号到修改日的天数):用户能够再次修改口令之间所必需经过的最少天数:口令需要修改之前保持有效的最大天数:口令到期前警告用户的天数:随各种Unix实现的不同而不同,但是通常表示口令不能用之前账户可以连续不活动的天数,或者是从口令期满到账户不能用之间的天数:自1970年1月1日以来的天数,直到账户期满时为止:保留字段以备将来使用
/etc/group存放组账户的信息。一条保存一个组信息。
每个条目的说明:
beginningunix(组名):使用该组的口令或x:GID(组ID):属于组的账户
列表,账户之间用冒号分隔。