ssh:交互式地登陆一个shell以便执行多个功能,如运行命令。该方法是用加密技术来保护会话。因此用户名、口令以及远程系统的所有通信都是加密的。
telnet:交互式地登陆一个shell以便执行多个功能,如运行命令。该方法没有使用加密技术。所以用户名、口令以及与远程系统的所有通信都是以普通文本的方式发送。
sftp:登陆以便在两个不同系统之间传送文件。该方法使用了加密技术。
ftp:登陆以便在两个不同系统之间传送文件。该方法没有使用了加密技术。
命令-sh、bash、ksh等的区别
大多数系统中都有三种主要的shell:Bourne shell(也叫做sh),C shell(csh)和Korn shell(ksh)。
Bourne shell
Bourne shell是Unix的第一个shell。它一直是在Unix系统上使用得最为广泛的shell,提供了一种用于脚本编程的语言以及调用其它程序的基本用户功能。Bourne shell的问题在于,相对于更为现代的shell,它的用户交互能力比较差。
C shell
C shell是另外一个在Unix系统上普遍可用的流行的shell。这个shell来自于加利佛尼亚大学伯克利分校,其创建的目的是改进Bourne shell的一些缺点并使其类似于C语言。
Korn shell
Korn shell是由David Korn创建的,它克服了Bourne shell的用户交互问题,并解决了C shell的脚本编程怪僻这一缺点。Korn shell添加了一些Bourne shell和C shell都没有的功能,综合了各种shell的长处。Korn shell惟一的缺点是它需要许可证。
bash
bash(Bourne Again Shell-Bourne shell修补后的版本)
Unix背景
UNIX操作系统(尤尼斯),是一个强大的多用户、多任务操作系统,支持多种处理器架构,按照操作系统的分类,属于分时操作系统,最早由KenThompson、Dennis Ritchie和Douglas McIlroy于1969年在AT&T的贝尔实验室开发。目前它的商标权由国际开放标准组织所拥有,只有符合单一UNIX规范的UNIX系统才能使用UNIX这个名称,否则只能称为类UNIX(UNIX-like)。
1965年时,贝尔实验室(Bell Labs)加入一项由通用电气(General Electric)和麻省理工学院(MIT)合作的计划;该计划要建立一套多使用者、多任务、多层次(multi-user、multi-processor、multi-level)的MULTICS操作系统。直到1969年,因MULTICS计划的工作进度太慢,该计划被停了下来。当时,Ken Thompson(后被称为UNIX之父)已经有一个称为”星际旅行”的程序在GE-635的机器上跑,但是反应非常慢,正巧被他发现了一部被闲置的PDP-7(Digital的主机),Ken Thompson和Dernis Ritchie就将”星际旅行”的程序移植到PDP-7上。而这部PDP-7(如图1-1所示)就此在整个计算机历史上留下了芳名。
MULTICS其实是”Multiplexed Information and Computing Service”的缩写,在1970年时,那部PDP-7却只能支持两个使用者,当时,Brian Kernighan就开玩笑地称他们的系统其实是:”UNiplexed Information and Computing Service”,缩写为”UNICS”,后来,大家取其谐音,就称其为”UNIX”了。1970年可称为”UNIX元年”。
Spring-标签-《context:component-scan》扫描使用上的容易忽略的use-default-filters
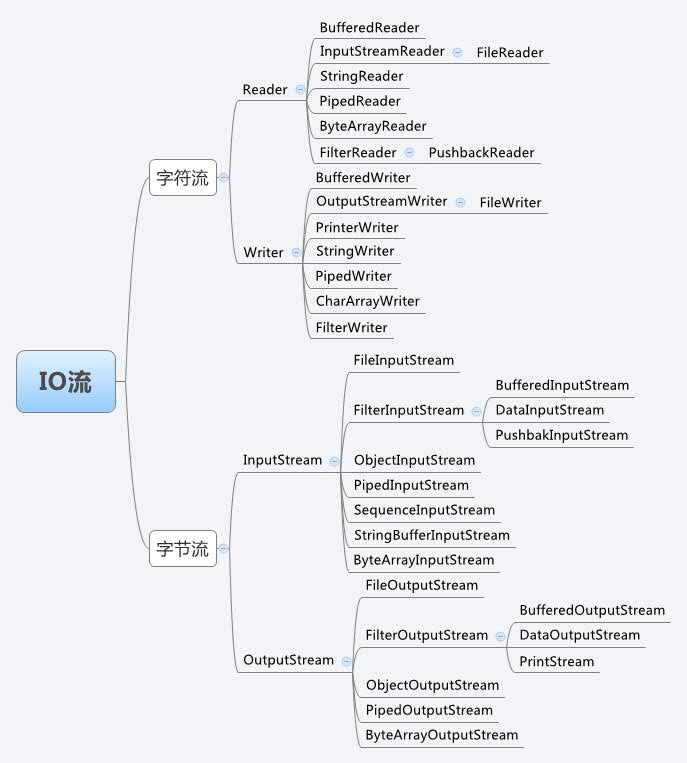
Java-API-IO流
JavaScript-加载事件
一般情况先一个页面响应加载的顺序是:域名解析-加载html-加载js和css-加载图片等其他信息。
JavaScript
document.ready和onload的区别
页面加载完成有两种事件
- ready,表示文档结构已经加载完成(不包含图片等非文字媒体文件)
- onload,指示页面包含图片等文件在内的所有元素都加载完成。
window.onload方法
执行时机:
在网页中所有元素(包括元素的所有关联文件)完全加载到浏览器后才执行,即JavaScript 此时可以访问网页中的所有元素。
多次使用:
JavaScript的onload事件一次只能保存对一个函数的引用,他会自动用最后面的函数覆盖前面的函数。
1 | function one(){ |
jQuery
用jQuery的人很多人都是这么开始写脚本的:
1 | $(function(){ |
其实这个就是jQuery ready()的简写,他等价于:
1 | $(document).ready(function(){ |
或者下面这个方法,jQuery的默认参数是:“document”;
1 | $().ready(function(){ |
这个就是jQuery ready()的方法就是Dom Ready,他的作用或者意义就是:在DOM加载完成后就可以可以对DOM进行操作。
$(document).ready()方法
执行时机:
在DOM完全就绪时就可以被调用。(这并不意味着这些元素关联的文件都已经下载完毕)
举个例子:$(document).ready()方法明知要DOM就绪就可以操作了,不需要等待所有图片下载完毕。
多次使用:
1 | function one(){ |
Java-注释-注释中的标签
常用Java注释标签(Java comment tags)
@author 作者
适用范围:文件、类、方法
(多个作者使用多个@author标签标识,java doc中显示按输入时间顺序罗列。)
例:
1 | * @author Leo. Yao |
@param 输入参数的名称 说明
适用范围:方法
例:
1 | * @param str the String用来存放输出信息。 |
@return 输出参数说明
适用范围:方法
例:
1 | * @return <code>true</code>执行成功; |
@since JDK版本
用于标识编译该文件所需要的JDK环境。
适用范围:文件、类
例:
1 | * @since JDK1.6 |
@version 版本号
用于标识注释对象的版本号
适用范围:文件、类、方法
例:
1 | * @version 1.0 |
@see 链接目标
表示参考。会在java 文档中生成一个超链接,链接到参考的类容。使用中的感觉是@see不需要包路径,对我这种懒人比较喜欢,相对{@link }这种既要加大括号,有需要包路径,我还是选择偷懒,当然你要是不介意使用import导入要link的类,那就可以达到@see的效果,所以总体来说,还是选择@see,当然两个在特殊场合下还是用法不一样的
用法:
1 | @see #field |
@throws 异常
标识出方法可能抛出的异常
适用范围:方法
例:
1 | * @throws IOException If an input or output exception occurred |
@deprecated 解释
标识对象过期
适用范围:文件、类、方法
@link 链接地址
链接到一个目标,用法类似@see。但常放在注释的解释中形如{@link …}
例:
1 | /** |
Java注释的使用顺序
1 | * @author (classes and interfaces only, required) |
简单常见的HTML嵌入
<P>
用于分段
<code>
标签用于表示计算机源代码或者其他机器可以阅读的文本内容。<code> 标签就是为软件代码的编写者设计的。包含在该标签内的文本将用等宽、类似电传打字机样式的字体(Courier)显示出来只应该在表示计算机程序源代码或者其他机器可以阅读的文本内容上使用 <code> 标签。虽然<code> 标签通常只是把文本变成等宽字体,但它暗示着这段文本是源程序代码。将来的浏览器有可能会加入其他显示效果。例如,程序员的浏览器可能会寻找 <code> 片段,并执行某些额外的文本格式化处理,如循环和条件判断语句的特殊缩进等。
数据库-基本概念-三层模式两级映像
我们首先,谈谈模式的概念,模式为某种事物的标准形式或使人可以照着做的标准样式。这个词用在数据库中,它是由英文的 Schema 翻译过来的。在数据库管理系统中,其模式是指数据模式(data schema),是数据抽象的结果表示,如用关系模型抽象学生的基本信息表示为:学生(学号、姓名、性别、出生年月、入校年月、专业编号),此表示即为一种数据模式。
在数据库管理系统中,将数据按三层结构来抽象,这实质上是与数据库的设计步骤密不可分的。
数据库的设计
- 首先应分析现实要求,即做需求分析,需求分析的任务就是通过调查、访谈、讨论,分析用户的业务流程,从而得出用户的需求,并用数据流程图、数据字典将用户需求描述出来;
- 其次,在需求分析的基础上,进行数据库概念设计,这种设计与具体的数据库管理系统无关,其任务是抽象出各用户所要求的数据视图(对应于外模式概念),最后综合为全局的数据视图(对应于模式概念),用概念数据模型来抽象,可用ER模型或对象模型。
- 第三步,将用ER模型或对象模型表示的数据视图,转换为关系模式,并对所得关系模式进行优化处理,这就是所谓的数据库逻辑设计(这一步仍然对应于外模式和模式);
- 第四步,在逻辑设计的基础上,将所得的数据模式组织存储到物理介质上,这就是数据库的物理设计(这一步对应于内模式);
- 最后,就是数据库的安全设计,即允许什么样的用户访问数据库,以及合法用户访问数据库中数据的权限等问题。
美国家标准协会(American National Standard Institute,ANSI)的数据库管理系统研究小组于 1978 年提出了标准化的建议,将数据库结构分为 3 级:面向用户或应用程序员的用户级、面向建立和维护数据库人员的概念级、面向系统程序员的物理级。用户级对应外模式,概念级对应模式,物理级对应内模式,使不同级别的用户对数据库形成不同的视图。所谓视图,就是指观察、认识和理解数据的范围、角度和方法,是数据库在用户“眼中”的反映,很显然,不同层次(级别)用户所“看到”的数据库是不相同的。
三层模式
模式
模式又称概念模式或逻辑模式,对应于概念级。它是由数据库设计者综合所有用户的数据,按照统一的观点构造的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图(全局视图,数据库的表,字段的类型等等)。它是由数据库管理系统提供的数据模式描述语言(Data Description Language,DDL)来描述、定义的,体现、反映了数据库系统的整体观。
外模式
外模式又称子模式,对应于用户级。它是某个或某几个用户所看到的数据库的数据视图,是与某一应用有关的数据的逻辑表示。外模式是从模式导出的一个子集,包含模式中允许特定用户使用的那部分数据。用户可以通过外模式描述语言来描述、定义对应于用户的数据记录(外模式),也可以利用数据操纵语言(Data Manipulation Language,DML)对这些数据记录进行处理。外模式反映了数据库的用户观(视图、查出数据的表)。
内模式
内模式又称存储模式,对应于物理级,它是数据库中全体数据的内部表示或底层描述,它描述了数据在存储介质上的存储方式及物理结构(顺序存储、按照B树结构存储还是按hash方法存储),对应着实际存储在外存储介质上的数据库。内模式由内模式描述语言来描述、定义,它是数据库的存储观。
在一个数据库系统中,只有唯一的数据库,因而作为定义、描述数据库存储结构的内模式和定义、描述数据库逻辑结构的模式,也是惟一的,但建立在数据库系统之上的应用则是非常广泛、多样的,所以对应的外模式不是惟一的,也不可能是惟一的。
数据库的三级模式是数据库在三个级别(层次)上的抽象,使用户能够逻辑地、抽象地处理数据而不必关心数据在计算机中的物理表示和存储。实际上 ,对于一个数据库系统而言一有物理级数据库是客观存在的,它是进行数据库操作的基础,概念级数据库中不过是物理数据库的一种逻辑的、抽象的描述(即模式),用户级数据库则是用户与数据库的接口,它是概念级数据库的一个子集(外模式)。
用户应用程序根据外模式进行数据操作,通过外模式一模式映射,定义和建立某个外模式与模式间的对应关系,将外模式与模式联系起来,当模式发生改变时,只要改变其映射,就可以使外模式保持不变,对应的应用程序也可保持不变;另一方面,通过模式一内模式映射,定义建立数据的逻辑结构(模式)与存储结构(内模式)间的对应关系,当数据的存储结构发生变化时,只需改变模式一内模式映射,就能保持模式不变,因此应用程序也可以保持不变。
数据库-基本概念-数据抽象的级别
数据抽象的过程
模型是对现实世界的抽象。在数据库技术中,我们用数据模型的概念描述数据库的结构和语义,对现实世界的数据进行抽象。
从现实的信息到数据库存储的数据以及用户使用的数据是一个逐步抽象的过程。
根据抽象的级别定义了四种模型:概念模型,逻辑数据模型,外部数据模型,和内部数据模型。
- 概念模型:表达用户需求观点的数据全局逻辑结构
- 逻辑模型:表达计算机实现观点的DB全局逻辑结构的模型
- 外部模型:表达用户使用观点的DB局部逻辑结构的模型
- 内部模型:表达DB物理结构的模型
数据抽象的过程,也就是数据库设计的过程,具体步骤:
- 根据用户需求,设计数据库的概念模型
- 根据转换规则,把概念模型转换成数据库的逻辑模型
- 根据用户的也不特点,设计不同的外部模型,给程序员使用
- 数据库实现时,要根据逻辑模型设计其内部模型。
概念模型
概念模型的抽象级别最高,特点:
- 表达了数据的整体逻辑结构,它是系统用户对整个应用项目涉及的数据的全面描述
- 概念模型是从用户需求的观点出发,对数据建模
- 概念模型对立与软件和硬件。
- 概念模型是数据库设计人员与用户之间进行交流的工具。
ER模型:ER模型只能说明实体间语义的联系,还不能进一步说明详细的数据结构。在数据库设计时,遇到实际问题总是先设计一个ER模型,然后把ER模型转换成计算机能够实现的数据模型。
逻辑模型
特点:
- 表达了DB的整体逻辑结构,但它是设计人员对整个应用项目数据库的全面描述
- 逻辑模型从数据库实现的观点出发,对数据建模。
- 逻辑模型独立于硬件,但是依赖于软件(DBMS)
- 逻辑模型是数据库设计人员与应用程序员之间进行交流的工具。
逻辑模型主要有:层次,网状,关系等三种
层次模型
用树形结构表示实体类型及实体间联系的数据模型称为层次模型
树中的节点是记录类型,上一层记录与下一层记录之间的联系是1:N的关系
特点:
- 记录之间的联系通过指针实现,查询效率较高。
缺点:
- 只能表示1:N联系
- 由于层次顺序的严格和复杂,引起数据的查询和更新操作很复杂,因此应用程序的编写也比较复杂
网状模型
用有向图结构表示实体类型及实体间联系的数据模型称为网状模型。
特点:记录之间的联系通过指针实现,M:N联系也容易实现,查询效率较高。
与文件系统的数据管理方式相比,层次模型和网状模型是一个飞跃,但致命你给的缺点是数据结构复杂和编程复杂。
关系模型
关系模型的主要特征是用二维表格表达实体集。
关系模型和层次,网状模型的最大差别是用关键码而不是用指针导航数据,其表格简单,用户易懂,用户只需用简单的查询语句就可以对数据库进行操作,不涉及存储结构,访问技术等细节,关系模型是数学化的模型哦。
外部模型
在应用系统中,常常是根据业务的特点化划分成若干个业务单位,每一个业务单位都有特定的约束和需求.在实际使用时,可以为不同的业务单位设计不同的外部模型.
外部模型的特点:
- 外部模型是逻辑模型的一个逻辑子集.
- 外部模型独立于硬件,依赖于软件.
- 外部模型反映了用户使用数据库的特定.
内部模型
内部模型又称为物理模型,是数据库最低层的抽象,它描述了在磁盘或磁带上的存储方式,存取设备和存取方法.