关于在spring 容器初始化 bean 和销毁前所做的操作定义方式有三种:
- 通过@PostConstruct 和 @PreDestroy 方法实现初始化和销毁bean之前进行的操作
- 通过 在xml中定义init-method 和 destory-method方法
1 | @Controller |
表单提交方法有三种,主要说下第三种
当Oracle实例在正常启动时,系统首先要访问的是初始化参数文件spfile,然后Oracle为系统全局区(SGA)分配内存。这是,Oracle实例处于安装状态,并且控制文件处于打开状态;接下来Oracle会自动读出“控制文件”中的所有数据文件和日志文件的信息,并打开当前数据库中所有的数据文件和所有的日志文件以供用户访问。
Oracle服务器主要由实例、数据库、程序全局区(PGA)和前台进程组成。
实例可以划分为:系统全局区(SGA)和后台进程(PMON、SMON等)两部分,其中,SGA使用操作系统的内存资源,而后台进程需要使用CPU和内存资源。
是所有用户进程共享的一块内存区域,也就是说,SGA中的数据资源可以被多个用户进程共同使用。SGA主要由高速数据缓冲区、共享池、重做日志缓存区、Java池和大型池等内存结构组成。SGA随着数据库实例的启动而加载到内存中,当数据库实例关闭时,SGA区域也就消失了。
高速数据缓冲区(Database buffer cache):存放着Oracle系统最近访问过的数据块(数据块在高速缓冲区中也可称为缓存块)。
若无法在高速数据缓冲区中找到所需要的数据,则Oracle首先从数据文件中读取指定的数据块到缓冲区,然后再从缓冲区中奖请求的数据返回给用户。由于高速数据缓冲区被所有用户共享,只要数据文件中的某些数据块被当前用户或其他用户请求过,那么这些数据块就会被装载到高速数据缓冲区中。经常或最近被访问的数据块会被放置到高速数据缓冲区前端,不常被访问的数据块会被放置到高速数据缓冲区的后端,当高速数据缓冲区填满时,会自动挤掉一些不常被访问的数据块。
- 脏数据区:脏数据区中存放着已被修改过的数据,这些数据等待被写入数据文件中。
- 空闲区:空闲区中的数据块不包含任何数据,这些数据块可以被写入数据,Oracle可以从数据文件中读取数据块,并将其放到该区中。
- 保留区:保留区包含那些正在被用户访问的数据块和明确保留以作为将来使用的数据块(即缓存块),这些数据块将被保留在缓冲区中。
重做日志缓冲区(Red log buffer cache):存放对数据库进行修改操作时所产生的日志信息,这些日志信息在写入到重做日志文件之前,首先存放到重做日志缓冲区中,然后,在检查点发生或重做日志缓冲区中的信息量达到一定峰值时,最后由日志写入进程(LGWR)将此缓冲区的内容写入到重做日志文件。
重做日志缓冲区的大小由LOG_BUFFER参数指定,该参数也可以在树立启动后动态修改。相对于高速数据缓冲区而言,重做日志缓冲区的大小对数据库性能的影响较小,通常较大的重做日志缓冲区能减少重做日志文件的对I/O的读取次数,对数据库的整体性能有一定的提高。
共享池(Shared Pool):共享池是SGA保留的内存区域,用于缓存SQL语句、PL/SQL语句、数据字典、资源锁、字符集以及其他控制结构等。共享池包含库高数缓冲区(Library cache)和字典高速缓冲区(Dictionary cache)。
库高速缓冲区是共享池的一部分,主要包括共享SQL区和私有SQL区两个组成部分。每条被缓存的SQL或PL/SQL语句都被分成两个部分,分别被存放在共享SQL区和私有SQL区中。共享SQL区存放SQL或PL/SQL语句的语法分析结果和执行计划,如果以后要再次执行类似的语句,则可以利用共享SQL区已缓存的语法分析结果和执行计划。私有SQL区存放SQL语句中的绑定变量、环境和会话等信息,这些信息属于执行该语句的用户的私有信息,其他用户则无法共享这些信息。
字典高速缓冲区用于存放Oracle系统内部管理所需要的数据字典信息,例如用户名、数据对象和权限等。
大型池(Large pool):大型池在SGA区中不是必需的内存结构,只在某些特殊情况下,实例需要使用大型池来减轻共享池的访问压力,常用的情况有以下几种:
Java池:用来提供内存空间给Java虚拟机使用,目的是支持在数据库中运行Java程序包,其大小由JAVA_POOL_SIZE参数决定。
流池:Oracle流池用于在数据库与数据库之间进行信息共享。如果没有用到Oracle流,就不需要设置该池。流池的大小由参数STREAMS_POOL_SIZE决定。
也称作用户进程全局区,它的内存区在进程私有区而不是共享区中。虽然PGA是一个全局区,可以把代码、全局变量和数据结构都可以存放在其中,但区域内的资源并不像SGA一样被所有的用户进程所共享,而是每个Oracle服务器进程都只拥有属于自己的那部分PGA资源。
各个服务进程的PGA区的总和即为实例的PGA区的大小。通常PGA区由私有SQL区和会话区组成:
前台进程包括用户进程和服务进程,它不属于实例的一部分,但是用户在不知不觉中经常会用到它,使用前台进程能够实现用户和实例沟通。
用户进程:指那些能够产生或执行SQL语句的应用程序。在用户进程中有两个非常重要的概念:连接和会话。
服务器进程:用于处理用户会话过程中想数据库实例发出SQL语句,它可以分为专用服务器模式和共享服务器模式。在专用服务器模式下,每个用户进程都有一个专用的服务器进程,这个服务器进程代表用户进程执行SQL语句,必要时还可以回传执行结果给用户进程。在共享服务器模式下,每个用户进程不直接与服务器连接,而是连接到分派程序,每个分派程序可以同时连接多个用户进程。
是一组运行于Oracle服务器端的后台程序,是Oracle实例的重要组成部分。其中SMON、PMON、DBWR、LGWR和CKPT这5个后台进程必需正常启动,否则导致数据库实例崩溃。
数据写入进程(DBWR):主要任务是负责将内存中的脏数据块回写到数据文件中通常在以下几种情况发生时,DBWR进程会将脏数据块写入数据文件:
在某些比较繁忙的应用系统中可以修改服务器参数文件SPFILE的DB_WRITER_PROCESSES参数,以允许使用多个DBWR进程。但是DBWR进程的数量不应当超过系统处理器的数量,否则多余的DBWR不但无法发乎作用,反而会耗费系统资源。
检查点进程(CKPT):检查点进程可以看作一个时间,当检查点时间发生时,CKPT会要求DBWR将某些脏数据块回写到数据文件。当用户进程发出数据请求时,Oracle系统从数据文件中读取需要的数据并存放到高速数据缓冲区中,用户对数据的操作是在缓冲区中进程的。当用户操作数据时,就会产生大量的日志信息并存储在重做日志缓冲区,当Oracle系统满足一定条件时,日志写入进程(LGWR)会将日志信息写入到重做日志文件组中,当发生日志切换时,就会启动检查点进程。
日志写入进程(LGWR):用于将重做日志缓冲区中的数据写入重做日志文件。
归档进程(ARCH):归档进程是一个可选择的进程,只有当Oracle数据库处于归档模式时,该进程才可能起到作用。若Oracle数据库处于归档模式,当各个日志文件组都被写满而即将被覆盖之前,先由归档进程(ARCH)把即将被覆盖的日志文件中的日志信息读出,然后再把这些“读出的日志信息”写入到归档日志文件中。
系统监控进程(SMON):系统监控进程是在数据库系统启动时执行恢复工作的强制性进程。比如,在并行服务器模式下,SMON可以恢复另一个处于失败的数据库,使系统切换到另一台正常的服务器上。
进程监控进程(PMON):用于监控其他进程的状态,当有进程启动失败时,PMON会清除失败的用户进程,释放用户进程所用的资源。
锁定进程(LCKN):这是一个可选进程,并行服务器模式下可以出现多个锁定进程以利于数据库通信。
恢复进程(RECO):这是在分布式数据库模式下使用的一个可选进程,用于数据不一致时进行恢复工作。
调度进程(DNNN):这是一个可选进程,在共享服务器模式下使用,可以启动多个调度进程。
快照进程(SNPN):快照进程用于处理数据库快照的自动刷新,并通过DBMS_JOB包运行预定的数据库存储过程。
一个或多个数据块组成一个数据区,一个或多个数据区再组成段。
一个段可以属于多个数据文件。一个区不能跨越数据文件。
Oracle逻辑存储结构中最小的逻辑单位,也是执行数据库输入输出操作的最小存储单位。通常数据块是操作系统块的整数倍。Oracle支持在同一个数据库中使用多种大小的块,与标准块大小不同的块就是非标准块。
数据块由以下几个部分组成:
v$parameter where name='db_block_size'可以查询标准的数据库大小。
有一组连续的Oracle数据块所构成的Oracle存储结构。
它不是存储空间的分配单位,而是一个独立的逻辑存储结构。
通常有以下4种类型的段:
使用表空间将相关的逻辑结构组合在一起,是最大的逻辑划分区域,通常用来存放数据表、索引、回滚段等数据对象。表空间与数据文件相对应,一个表空间有一个或者多个数据文件组成,一个数据文件只属于一个表空间。
Oracle数据块的物理存储结构由多种物理文件组成,主要有数据文件、控制文件、重做日志文件、归档日志文件、参数文件、口令文件和警告日志文件等。
用于保存用户应用程序数据和Oracle系统内部数据的文件,这些文件在操作系统中就是普通的操作系统文件。只能由Oracle系统负责为数据对象选择具体的数据文件,并在其中分配物理存储空间,用户是无法指定使用哪一个数据文件来进程存储的。
在读取数据时,Oracle系统首先从数据文件中读取数据,并将数据存储在内存的高速数据缓冲区中,如果用户要读取数据库中的某些数据,而请求的数据又不在内存的高速数据缓冲区中,则需要从相应的数据文件中能够读取数据斌光存储在缓冲区中。当修改和插入数据时,Oracle不会立即将数据写入数据文件,而是把这些数据保存在数据缓冲区中,然后由Oracle的后台进程DBWR决定如何将其写入相应的数据文件。这样的存取方式减少了磁盘的I/O操作,提高了系统的响应性能。
是一个二进制文件,它记录了数据库的物理结构,其中主要包含数据库名、数据文件与日志文件的名字和位置、数据库建立日期等信息。控制文件一般在Oracle系统安装时或创建数据库时自动创建,控制文件所存放的路径有服务器参数文件spfileorcl.ora和control_files参数值来指定。
由于控制文件存放有数据文件、日志文件等的相关信息,因此,Oracle实例在启动时必需访问控制文件。
当Oracle实例在正常启动时,系统首先要访问的是初始化参数文件spfile,然后Oracle为系统全局区(SGA)分配内存。这是,Oracle实例处于安装状态,并且控制文件处于打开状态;接下来Oracle会自动读出“控制文件”中的所有数据文件和日志文件的信息,并打开当前数据库中所有的数据文件和所有的日志文件以供用户访问。
每个数据库至少拥有一个控制文件,一个数据库可以同时拥有多个控制文件,但是一个控制文件只能属于一个数据库。控制文件内部除了存放数据库名以及其创建日期、控制文件、日志文件等的相关信息之外,在系统运行过程中,还存放有系统更改号、检查点信息及归档的当前状态灯信息。
处于安全考虑,在安装Oracle数据库或创建数据库时,Oracle数据库系统会自动创建2个或3个控制文件,每个控制文件记录相同的信息。v$controlfile可以查询控制文件信息。
主要功能是记录对数据所做的修改,对数据库所做的修改记录都记录在日志文件中。
用来记录数据库所有发生过的更改信息(修改、添加、删除等信息)及由Oracle内部行为(创建数据表、索引等)而引起的数据库变化信息。在数据库恢复时,可以从该日志文件中读取原始记录。在数据库运行期间,当用户执行COMMIT命令时,数据库首先将每笔操作的原始记录写入到日志文件中,写入日志文件成功后,才把新的记录传递给应用程序。
通过对表或则整个表空间设定NOLOGGING属性时,使基于表或表空间中所有的DML操作(如创建表、删除试图、修改索引等操作)都不会产生日志信息。
为了保障数据库系统的安全,每个Oracle实例都启用一个日志线程来记录数据库的变化。日志线程有若干“日志组”构成,而每个日志组又由一个或者多个日志文件构成。
Oracle系统在运行过程中产生的日志信息,首先被临时存放在系统全局区的“重做日志缓冲区”中,当发出COMMIT命令(或日志缓冲区信息满1/3)时,LGWR进程(日志写入进程)将日志信息从“重做日志缓冲区”中读取出来,并将“读取的日志信息”写入到日志文件组中序列号较小的文件里,一个日志组写满后接着写另外一个日志组。当LGWR进程将所有能用的日志文件都使用过一遍后,它将再辞转向第一个日志组重新覆写。
v$logfile查询日志文件。
在所有的日志文件被写入一遍之后,LGWR进程将再次转向第一个日志组进行重新覆写,这样务必会导致一部分较早的日志信息被覆盖掉,但Oracle通过归档日志文件解决了这个问题。
Oracle数据库可以运行在两种模式下,即归档模式和非归档模式。非归档模式是指在系统运行期间,所产生的日志信息不断地记录到日志文件组中,当所有重做日志被写满后,又重新从第一个日志组开始覆写。归档模式是在各个日志文件都被写满而即将被覆盖之前,先由归档进程(ARCH)将即将被覆盖的日志文件中的日志信息读出,并将“读出的日志信息”写入到归档日志文件中,而这个过程又被称为归档操作。
在归档操作进程的过程中。日志写入进程(LGWR)需要等待归档进程(ARCH)的结束才能开始覆写日志文件,这样就延迟了系统的响应时间,而且归档日志本身又会占用大量的磁盘空间,这些都会影响系统的整体性能。所以在默认情况下,Oracle系统不采用归档模式运行。
如果将Oracle数据库系统设置成在归档模式下运行,则可以通过服务器参数文件spfile的log_archive_dest参数来规定归档日志文件的所在路径。
SPFILE(Server parameter File)是二进制文件,用来记录Oracle数据库的基本参数信息(如数据库名、控制文件所在路径、日志缓冲大小等)。数据库实例在启动之前,Oracle系统首先会读取SPFILE参数文件中设置的这些参数,并根据这些初始化参数来配置和启动实例。比如,设置标准数据块的大小(即参数db_block_size的值)、设置日志缓冲区的大小(即参数log_buffer的值)等,所以SPFILE参数文件非常重要。服务器参数文件在安装Oracle数据库系统时由系统自动创建,文件的名称为SPFILEsid.ora,sid问所创建的数据库实例名。
是Oracle系统用于验证sysdba权限的二进制文件。
是一个存储在Oracle系统目录下的文本文件(名称通常为alert_orcl.log),它用来记录Oracle系统的运行信息和错误信息。
跟踪文件包括后台进程跟踪文件和用户跟踪文件。后台进程跟踪文件用于记录后台进程的警告或错误信息,每个后台进程都有对应的后台进程跟踪文件。用户跟踪文件主要用于跟踪SQL语句。
session在web开发中是一个非常重要的概念,这个概念很抽象,很难定义,也是最让人迷惑的一个名词,也是最多被滥用的名字之一,在不同的场合,session一次的含义也很不相同。这里只探讨HTTP Session。
为了说明问题,这里基于Java Servlet理解Session的概念与原理,这里所说Servlet已经涵盖了JSP技术,因为JSP最终也会被编译为Servlet,两者有着相同的本质。
在Java中,HTTP的Session对象用javax.servlet.http.HttpSession来表示。
Session代表服务器与浏览器的一次会话过程,这个过程是连续的,也可以时断时续的。在Servlet中,session指的是HttpSession类的对象,这个概念到此结束了,也许会很模糊,但只有看完本文,才能真正有个深刻理解。
一个常见的误解是以为session在有客户端访问时就被创建,然而事实是直到某server端程序调用 HttpServletRequest.getSession(true)这样的语句时才被创建,注意如果JSP没有显示的使用 <% @page session="false"%> 关闭session,则JSP文件在编译成Servlet时将会自动加上这样一条语句 HttpSession session = HttpServletRequest.getSession(true);这也是JSP中隐含的 session对象的来历。
由于session会消耗内存资源,因此,如果不打算使用session,应该在所有的JSP中关闭它。
引申:
1 | Cookie:JSESSIONID=客户端第一次拿到的session ID |
这样,服务器端在接到请求时候,就会收到session ID,并根据ID在内存中找到之前创建的session对象,提供给请求使用。这也是session使用的基本原理—-搞不懂这个,就永远不明白session的原理。
下面是两次请求同一个jsp,请求头信息:
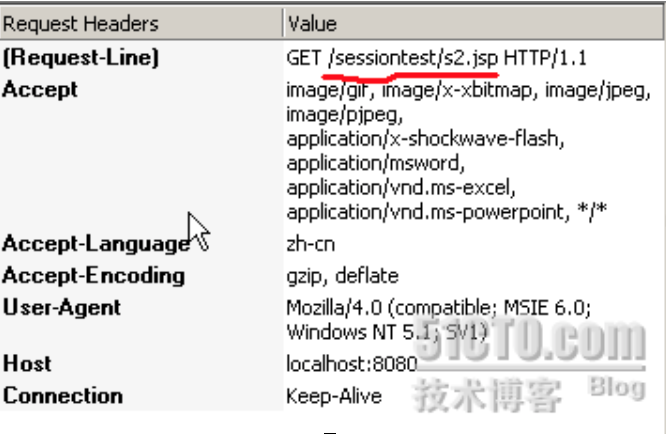
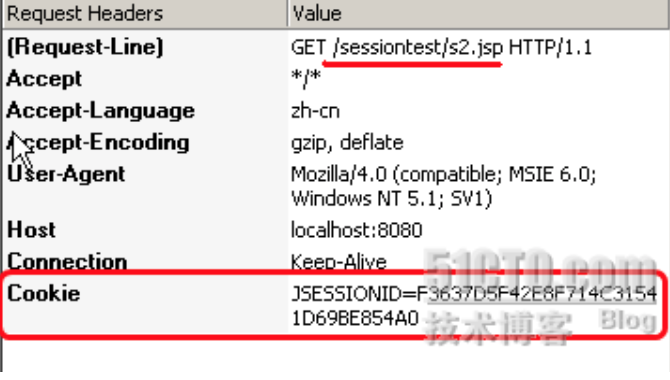
通过图可以清晰发现,第二次请求的时候,已经添加session ID的信息。
服务器端的内存中。不过session可以通过特殊的方式做持久化管理。
当客户端第一次请求session对象时候,服务器会为客户端创建一个session,并将通过特殊算法算出一个session的ID,用来标识该session对象,当浏览器下次(session继续有效时)请求别的资源的时候,浏览器会偷偷地将sessionID放置到请求头中,服务器接收到请求后就得到该请求的sessionID,服务器找到该id的session返还给请求者(Servlet)使用。一个会话只能有一个session对象,对session来说是只认id不认人。
不会,session只会通过上面提到的方式去关闭。
一般来说,每次请求都会新创建一个session。
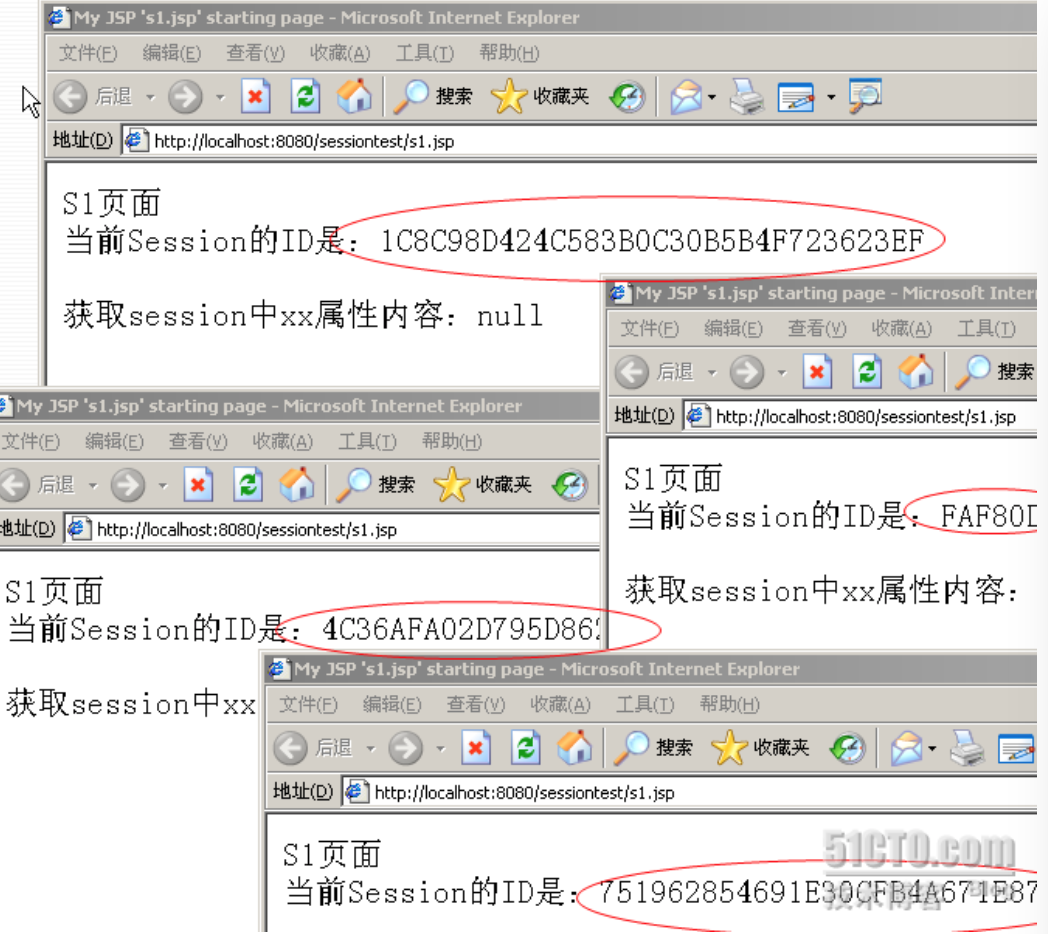
其实,这个也不一定的,总结下:对于多标签的浏览器(比如360浏览器)来说,在一个浏览器窗口中,多个标签同时访问一个页面,session是一个。对于多个浏览器窗口之间,同时或者相隔很短时间访问一个页面,session是多个的,和浏览器的进程有关。对于一个同一个浏览器窗口,直接录入url访问同一应用的不同资源,session是一样的。
转自:http://blog.csdn.net/kobejayandy/article/details/12690041
@RequestMapping
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
RequestMapping注解有六个属性,下面我们把她分成三类进行说明。