0%
[build by hexo/next/gitalk/hexo-generator-search/LaTeX]">
- 最简单的数据扩充方法就是垂直镜像对称,假如,训练集中有这张图片,然后将其翻转得到右边的图像。对大多数计算机视觉任务,左边的图片是猫,然后镜像对称仍然是猫,如果镜像操作保留了图像中想识别的物体的前提下,这是个很实用的数据扩充技巧。
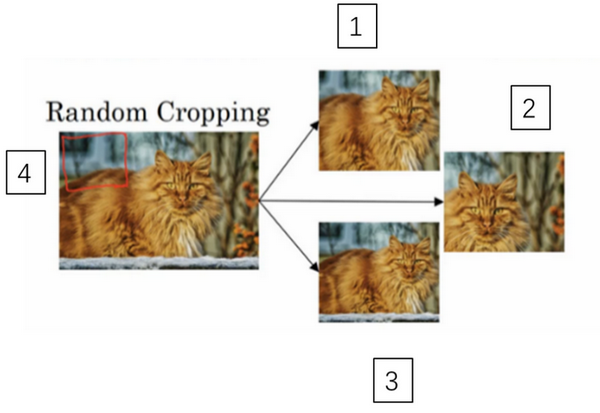
- 另一个经常使用的技巧是随机裁剪,给定一个数据集,然后开始随机裁剪,可能修剪这个(编号1),选择裁剪这个(编号2),这个(编号3),可以得到不同的图片放在数据集中,你的训练集中有不同的裁剪。随机裁剪并不是一个完美的数据扩充的方法,如果你随机裁剪的那一部分(红色方框标记部分,编号4),这部分看起来不像猫。但在实践中,这个方法还是很实用的,随机裁剪构成了很大一部分的真实图片。
- 镜像对称和随机裁剪是经常被使用的。当然,理论上,你也可以使用旋转,剪切(shearing:此处并非裁剪的含义,图像仅水平或垂直坐标发生变化)图像,可以对图像进行这样的扭曲变形,引入很多形式的局部弯曲等等。当然使用这些方法并没有坏处,尽管在实践中,因为太复杂了所以使用的很少。
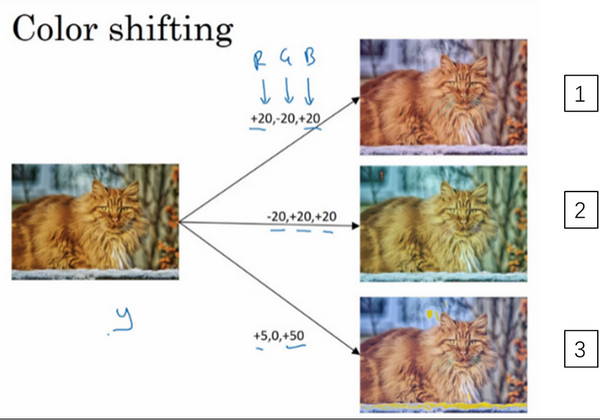
- 第二种经常使用的方法是彩色转换,有这样一张图片,然后给R、G和B三个通道上加上不同的失真值。